")
[ad_1]
Several organisations and businesses rely on PDF documents to share important documents such as invoices, payslips, financials, work orders, receipts, and more. However, PDFs are not the go-to formats for storing historical data since they can’t be easily exported & organised into workflows. So people use information extraction algorithms to digitise PDFs & scanned documents into structured formats like JSON, CSV, Tables or Excel that can easily be converted into other organisational workflows.
In some cases, PDFs hold essential information to be processed in different ERPs, CMS, and other database-driven systems. Unfortunately, PDF documents do not have an easy PDF to database function, and writing scripts or building a workflow around this task is a bit complicated. This is where OCR and Deep Learning (DL) algorithms come into the picture to extract data from these PDF formats and export it into a database. In this blog post, we will look at different ways for how you might accomplish that by using DL technologies as well as some popular APIs on the market.
Table of Contents
What is PDF to Database Conversion
PDF to Database Conversion is the task of exporting data from PDFs into a database such as Postgres, Mongo, MySQL, etc.
Suppose we were to build a web application or an ERP system that holds and maintains invoice information from different sources. Adding historical invoices manually onto a database is an uphill task and is highly error-prone. On the other hand, using a simple OCR might not extract tables from invoices accurately.
This is where advanced AI-driven PDF to Database conversion comes in handy!
Can this AI-driven PDF to database conversion process be automated? – Yes.
In the sections below, we use computer vision and deep learning to detect table regions from scanned documents. These tables are further stored in a particular data format such as CSV or excel and will be pushed directly into databases.
Before discussing these, let us understand some use-cases where PDF to database detection can be useful.
Different use-cases for PDF to Databases
Databases are the best ways to store information on both cloud and local storage. They allow us to perform different operations and manipulations using simple queries. Here are some use cases that could be greatly optimised with an automated PDF to database conversion workflow:
- Invoice Management on the Web: Businesses and organizations deal with several invoices every day; and it is hard for them to process each invoice manually. Also, sometimes, they raise and receive invoices in a non-digital format, which makes them harder to track. Hence, they rely on web-based applications that can store all their invoices in one place. A PDF to database converter could automate data extraction from the invoices to the web application. To automate these tasks efficiently, we could run cron jobs and integrate them with third-party services such as n8n and Zapier – when a new invoice is scanned and uploaded, it can run the algorithm and automatically push it into tables.
- ECom Inventory Management: Lots of e-com inventory management still runs through manual entry of products from PDFs and scanned copies. However, they need to upload all their data into billing management software to keep track of all their products and sales. Hence, using the table to database conversion algorithm can help automate their manual entry and save resources. This process typically involves scanning the inventory list from scanned documents and exporting them into specific database tables based on different business rules and conditions.
- Data Extraction from Surveys: To collect feedback and other valuable information, we usually conduct a survey. They provide a critical source of data and insights for nearly everyone engaged in the information economy, from businesses and the media to government and academics. When these are collected online, it’s easy to extract the table data status based on the user response and upload it onto a database. However, in most cases, survey responses are on paper. In such cases, it’s super hard to manually collect information from and store them in a digital format. Therefore, relying on a table to database algorithms can save time and also cut additional costs.
How to extract information from PDFs to Relational and Non-Relational Databases
A PDF file is seen as two different types, electronically generated and non-electronically generated.
- Electronic PDFs: This scanned PDF document may have hidden text behind the image; these are also referred to as electronically generated PDFs.
- Non-electronic PDFs: In this type, we see more content hard-coded as images. This is the case when you have a hard copy document scanned into a PDF file.
We could rely on simple programming languages and frameworks such as Python and Java for the first type (electronically generated). For the non-electronically generated PDFs, we will need to utilize Computer Vision techniques with OCR and deep learning. However, these algorithms might not be the same for all the table extraction algorithms, and they will need to change depending on the type of data to achieve higher accuracy. NLP (Natural Language Processing) is also utilized to understand the data inside tables and extract them in some cases.
On the other hand, there are two kinds of databases (relational and non-relational); each of these databases has different sets of rules based on their architecture. A relational database is structured, meaning the data is organized in tables. A few examples include MySQL, Postgres, etc.
In contrast, the non-relational database is document-oriented, meaning all information gets stored in more of a laundry list order. Within a single constructor document, you will have all of your data listed out – for example, MongoDB.
PDF to a database when documents are electronically generated
As discussed, for electronically generated PDFs, the process of extracting tables is straightforward. The idea is to extract tables and then use simple scripts to convert them or add them into tables. For table extraction from PDFs, there are primarily two techniques.
Technique #1 Stream: The algorithm parses through tables based on whitespaces between cells to simulate a table structure—identifying where the text is not present. It is built on PDFMiner’s functionality of grouping characters on a page into words and sentences using margins. In this technique, first, the rows are detected by making rough guesses based on some text’s y-axis position (i.e., height). All text on the same line is considered to be part of the same row. Next, the reader is grouped and put together as a different group to identify the columns in the table. Lastly, the table is set together based on the rows and columns detected in earlier steps.
Technique #2 Lattice: In contrast with the stream, Lattice is more deterministic. Meaning it does not rely on guesses; it first parses through tables that have defined lines between cells. Next, it can automatically parse multiple tables present on a page. This technique essentially works by looking at the shape of polygons and identifying the text inside the table cells. This would be simple if a PDF has a feature that can identify polygons. If it had, it would plausibly have a method to read what is inside of it. However, it does not. Hence, computer vision is widely utilised to identify these shapes and extract the contents of the table.
The extracted tables are primarily saved in a data frame format. It is one of the native data types that’s offered by one of the most popular Python library pandas. There are several advantages of storing table data in a data frame. They can be easily handled, manipulated, and exported into different formats such as JSON, CSV, or tables. However, before we push these data frames into tables, we should first connect to the DB-Client database and then migrate the table. Using languages like Python, we can find several libraries that can connect to these data sources and export data.
PDF to the database when documents are non-electronically generated
The above-discussed techniques might not work for non-electronically generated PDFs, as the data here is manually scanned through a different source. This is why we will be using OCR and Deep Learning techniques to extract data from scanned documents and export them into databases.
In short, Optical Character Recognition, OCR is a special tool that converts printed letters from scanned documents into editable text. For identifying PDF tables from documents, first, we need to identify the position of the table and then apply OCR to extract data from table cells. Following are the steps on how it is achieved:
- First, we detect the line segments by applying horizontal and vertical contours.
- The line intersections between lines are detected by looking at the intensity of the pixels of all lines. If a line pixel has more intensity than the rest of the pixel, it is part of two lines and, therefore, an intersection.
- The edges of the table are determined by looking at the intensity of the pixels of intersected lines. Here, all the pixels of a line are taken, and the most external lines represent the boundaries of the table.
- The image analysis is translated into the PDF coordinates, where the cells are determined. The text is assigned to a cell based on its x and y coordinates.
- OCR is applied to the coordinates to extract the text
- The extracted text is exported into a data frame based on the position of the table.
This is how we can extract tables using CV. However, there are a few drawbacks here. These algorithms fail for large tables and tables with different template styles. This is where deep learning comes in; they use a special kind of neural network framework to learn from data and identify similar patterns based on the learnings. Over the last decade, they have achieved state-of-the-art performance, especially for tasks like information extraction. Now, let’s look at how deep neural networks can learn from data and extract tables from any document.
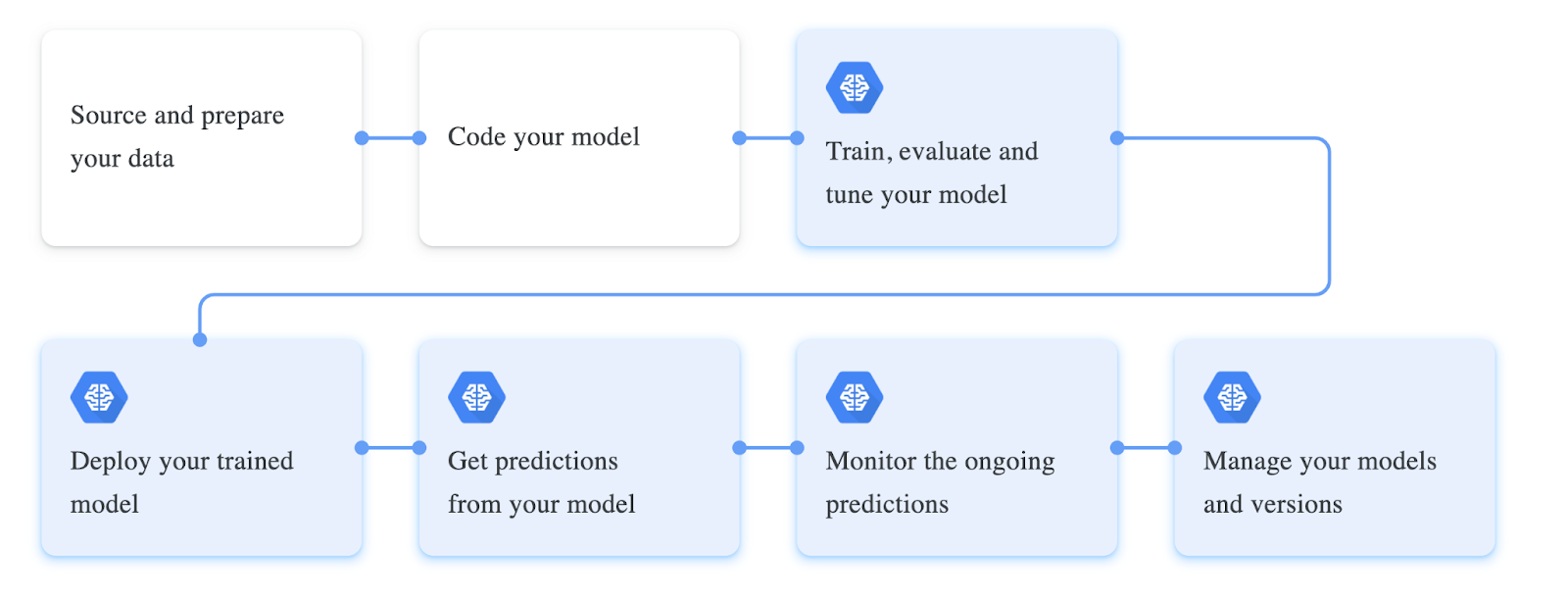
Training deep neural networks involves a specific workflow; these workflows are often altered based on the type of data we are working with and their model’s performance. The first phase of the workflow involves collecting the data and processing them based on our model. In our case of extracting the tables from the PDF documents, the dataset should ideally contain unstructured documents. These documents are converted into images, loaded as tensors, and made ready as a data loader class for training. Next, we usually define all the hyperparameters that are required for training. These usually include setting up the batch size, loss function, optimizer for the model. Lastly, a neural network architecture is defined or built on top of a pre-defined model. This model will be trained on top of data and fine-tuned based on the performance metrics.
Following is a screenshot of different steps that are involved in training a deep learning model:
Extracting data from pdf and exporting them into SQL database using Python
So far, we have learned what pdf to database conversion is and have discussed some use-cases where it can be helpful. This section will practically approach this problem using Computer Vision and detect tables in scanned pdfs and export them into databases. To follow along, make sure to install Python and OpenCV on your local machine. Alternatively, you can use an online Google Collab notebook.
Step 1: Install Tabula and Pandas
In this example, we will be using Tabula and Pandas to extract and push tables into databases. Let’s install them via pip and import them into our program.
import tabula
import pandas as pdStep 2: Reading Tables into Dataframe
Now, we will be using the read_pdf function from tabula to read tables from PDFs; note that this library only works on PDF documents that are electronically generated. Following is the code snippet:
table = tabula.read_pdf("sample.pdf",pages="all",multiple_tables=False)
df = pd.concat(table)Here, as we can see, first, we use to read the contents for PDF file, we set the parameter multiple_tables to False, as the document used in the example only has one table.
Now, we will be loading this list into a data frame using pandas, and you can check the type of the table by using the type method; this will return a native pandas data frame.
Step 3: Migrating Dataframe to Postres
Before we push our table into databases, first, we should establish a connection to it from our program, and we can do this using the sqlalchemy client in python. Similarly, different programming languages offer this kind of database clients to interact with databases directly from our programs.
In this program, we will be using the create_engine method that lets us connect with the database; make sure to replace the database credentials in the given string to get this working. Next, we use the write_frame function to export the extracted table into the connected database.
engine = create_engine('postgresql+psycopg2://username:password@host:port/database')
sql.write_frame(df, 'table_name', con, flavor="postgresql")
And just like that, we were able to export tables from PDFs into the database, this looks pretty straightforward and easy as we have used a simple processed electronically generated PDF. For extracting tables from non-electronically generated tables following are popular deep learning techniques that can be utilised:
- Papers with Code – GFTE: Graph-based Financial Table Extraction
- Papers with Code – PubTables-1M: Towards a universal dataset and metrics for training and evaluating table extraction models
- TableNet: Deep Learning model for end-to-end Table detection and Tabular data extraction from Scanned Document Images
Enter Nanonets: Advanced OCR for PDF Table to Database Conversion
This section will look at how Nanonets can help us perform tables to the database in a more customizable and easier way.
Nanonets™ is a cloud-based OCR that can help automate your manual data entry using AI. We will have a dashboard where we can build/train our OCR models on our data and transport them in JSON/CSV or any desired format. Here are some of the advantages of using Nanonets as a PDF document scanner.
One of the highlights of Nanonets is the simplicity the service brings. One can opt for these services without any programming background and easily extract PDF data with cutting edge technology. The following is a brief outline of how easy it is to convert PDF into the database.
Step 1: Go to nanonets.com and register/log in.
Step 2: After registration, go to the “Choose to get started” area, where you can use the pre-built extractors or create one on our own using your dataset. Here, we will be using Invoice pre-built invoice extractor.

Step 3: Upload PDF of images, to perform data extraction and choose auto-extract option.

Step 4: Create a new integration MySQL integration to export extracted data into database. Alternatively, you can choose various options based on the databases of your choice.

Establish data connection and click add integration. With this, the data will be extracted and automatically uploaded onto a database whenever files are uploaded. If you don’t find the required integrations, you can always use the Nanonets API and write simple scripts to get the automation done.
[ad_2]
Source link