
[ad_1]
Tired of workflows that require you to rename PDF files or documents? Automate such tedious manual tasks with Nanonets. Click below to check out Nanonets’ Zap to automatically rename PDF files based on their content!
Why Rename PDF Files based on their content?
* PDF files shared between organizations are named haphazardly.
* The file names often have nothing to do with the data they contain.
* This makes it hard to keep track of documents and identify them.
* Precious man-hours are spent in renaming and organizing such documents for convenient reference.
*This allows users to identify files more quickly, and get some information about the documents without having to open them individually.
PDF files are convenient for sharing and storing vast amounts of data/information. But PDF file names are not standardized.
Businesses struggle to organize & identify large numbers of PDF files in their database. The file names often have nothing to do with the underlying content of the document. It is not uncommon for organizations to receive PDF documents with a string of unintelligible characters for a file name.
For example, organizations often receive invoices as PDF files. Vendors follow different file naming conventions and invoicing formats. So vendor A might share a PDF invoice named “Vendor A” and vendor B might title their invoice “July2021 Vendor B”.
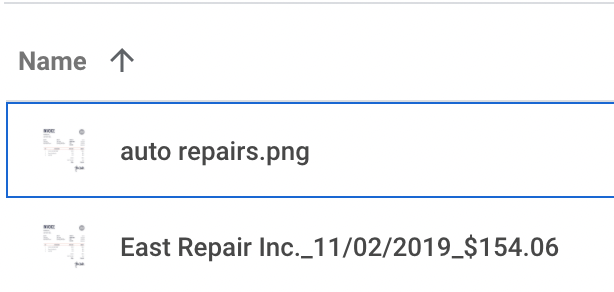
A standardized file naming protocol would make life so much easier – e.g. “Date_VendorName_Amount”. Organizing or identifying invoices renamed in this format would be so much more convenient and practical.
But it’s quite unrealistic to expect vendors or external parties to adhere to specific conventions such as “naming PDF files based on content” for each document they share. For all practical concerns, they might have their own rules, or worse none at all. Businesses often end up having to manually rename PDF files; an extremely time-consuming, error-prone & inefficient process.
So is there an efficient/automated way to reorganize PDF names based on their content or metadata?
How to Rename PDFs Based on Content
* Set up a Zap with Nanonets & Google Drive in 2 mins.
* Or reuse/customize Nanonets' Zap.
*Just add files to a dedicated Google Drive folder.
*Nanonets extracts data from the documents for renaming them in a meaningful way.
*Renamed copies of the files are saved on another Google Drive folder.
The team at Nanonets came up with an elegant solution to rename PDF files based on content – a Zap.
All you need is a Zapier account, a free Google Drive account and a free Nanonets account. And the Zap can be set up (or customised) in 2 minutes.
This is how the workflow looks like:
- A new file is added in a folder on Google Drive
- Nanonets OCR scans the file to extract information from the document
- A renamed copy of the file (based on the extracted data) is saved to another Google Drive folder
By connecting Nanonets & Google Drive on Zapier, you can create an automated workflow that renames PDF files according to content within each file. Here’s the shared version of the Zap that can be customized on Zapier for your specific use case.
Although this Zap specifically deals with renaming invoices, Nanonets’ OCR engine has pre-trained algorithms that can extract information from receipts, passports, & driver’s licenses. You can additionally train a custom OCR model with Nanonets to handle different/unknown document types (id cards, reports, bank statements etc.) & file formats (.doc, images etc.).
Looking to extract data from financial documents? Check out Nanonets invoice automation or invoice scanner & receipt OCR solutions to optimize your workflows.
Alternate Solutions
* Adobe plugins
*Does the job but not automated
*Requires considerable manual intervention
*Might throw up errors
Most solutions that attempt to rename documents in bulk come in the form of plugins for Adobe’s PDF reader; since renaming PDFs is the most popular use case.
While these solutions do a decent job, they are not automated in the true sense. They require considerable manual intervention to operate; and require some level of review/validation to check for errors.
Using a template-based approach to extract data, these solutions require users to mark areas of interest in the documents. This allows the plugin/software to identify content correctly in each document with the same layout. But this approach is impractical when dealing with unknown or non-standard document layouts. Users would be forced to make different templates for each document type; an inefficient and tedious approach!
Looking to convert bank statements from PDF to Excel or PDF to XML? Check out Nanonets for similar use cases.
Why Nanonets’ Zap is Better
* Fully automated, scalable & accurate
* AI/ML capabilities that keep learning continuously
* Renames multiple files automatically in seconds
* Handles unknown layouts and various file formats
Nanonets’ Zap is a truly automated solution powered by Zapier & Nanonets. Just upload the documents to one folder on Google Drive and get the renamed files in another dedicated folder.
Nanonets leverages AI & ML capabilities to only extract relevant data accurately from documents. This makes renaming PDFs or any other documents based on content pretty straightforward & scalable.
Nanonets can handle documents with unknown or new layouts/formatting with ease. Its algorithms learn continuously and keep getting better with time. Do you want to rename multiple documents that come in various file formats, different layouts and/or multiple languages? Nanonets can handle it all.
Nanonets online OCR & OCR API have many interesting use cases that could optimize your business performance, save costs and boost growth. Find out how Nanonets’ use cases can apply to your product.
Update June 2021: this post was originally published in June 2021 and has since been updated.
Here’s a slide summarizing the findings in this article. Here’s an alternate version of this post.
[ad_2]
Source link