
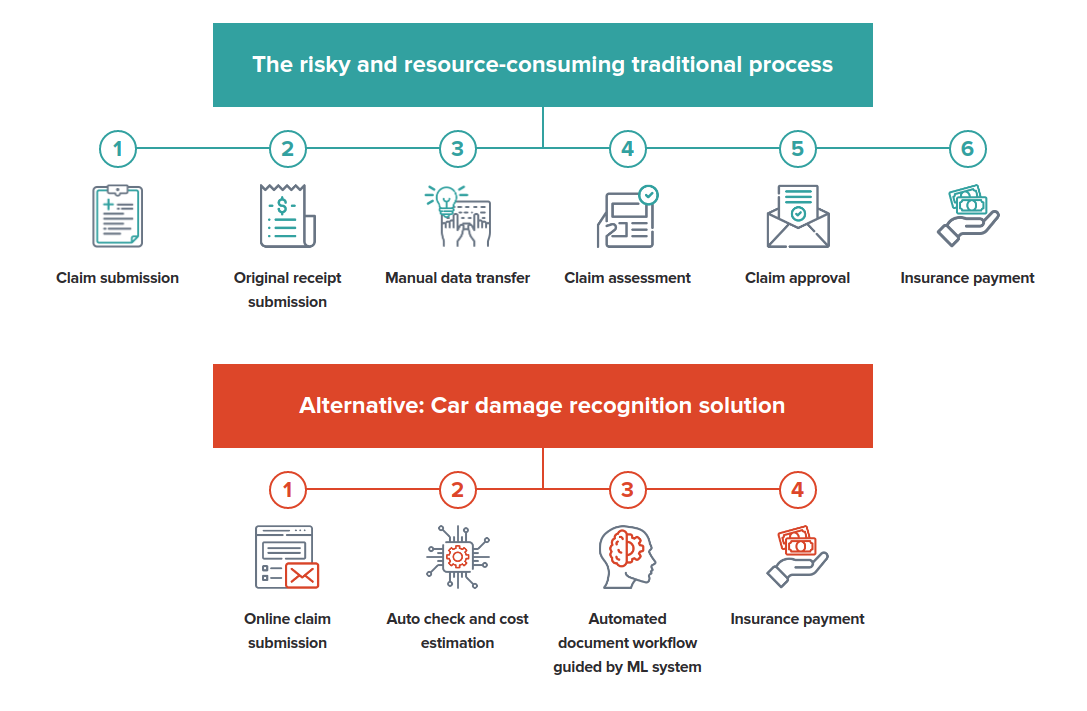
[ad_1]
Introduction
This article will take you through how Insurance companies can use artificial intelligence to automate claims processing by automatically detecting various kinds of damages – mobile phones, vehicles, roofs, etc. We will also learn how to build a simple binary classifier which will classify vehicle images into damaged or not using fast.ai.
Insurance is one of the oldest and most traditional industries and until recently it has been very resistant to change. Insurtech companies are focusing on adding value through automating tasks using different methods of artificial intelligence. They are positioning their value addition in the areas of natural language processing, computer vision, and machine learning. Using omnipresent data from different sources to offer deeper data insights and personalized plans for their clients.
Have a visual inspection problem in mind? Want to automatically detect where a vehicle is damaged and with what severity? Nanonets OCR API has many interesting use cases. Talk to a Nanonets AI expert to learn more.
Claims processing automation
Claims processing is one of the automation use cases in the insurance that is already seeing the great benefit by applying computer vision. Fast and efficient claims processing is paramount to success for insurance companies.
The latest advances in computer vision algorithms using deep learning are achieving interesting results in the classification of images, object detection, and image segmentation. The applications are still emerging, an increasing number of companies are starting to look at this technology as a way to make insurance claims processes easier and more efficient as one of the insurtech industry’s biggest challenges.
Claims processing in 2030 remains a primary function of insurance carriers, but headcount associated with manual claims is reduced by 70-90% compared with 2018 levels. – McKinsey Research
Manual inspection for claim processing is not scalable and error-prone. Automatic assessment of the damages through image analysis is much faster and more accurate and it will become even better as they collect more & more data for each use case. Here are some of the future insurtech use-cases that are being already built today.
Automatic Vehicle Damage Inspection

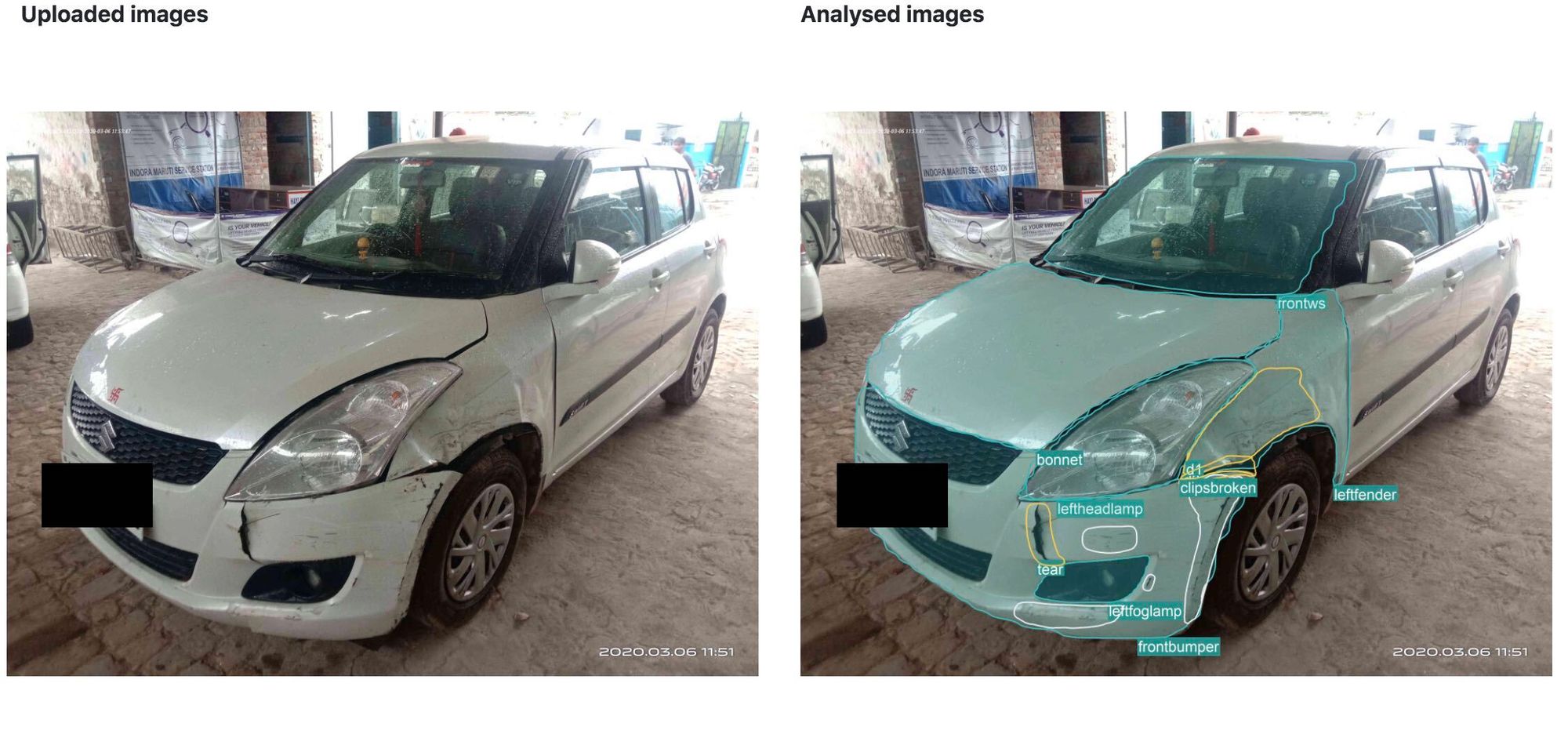
Inspections are often the very first step of the car insurance claim process. With deep learning we can automatically detect scratches, dents, rust, breakages. We can also detect which part of the vehicle is damaged and with what severity. The vehicle can be automatically inspected using images or video feeds by creating a 360° overview. After the inspection, the report can be generated with a list of damages and estimate cost repair.
You can learn more about the Nanonets solution for automatic vehicle damage detection here
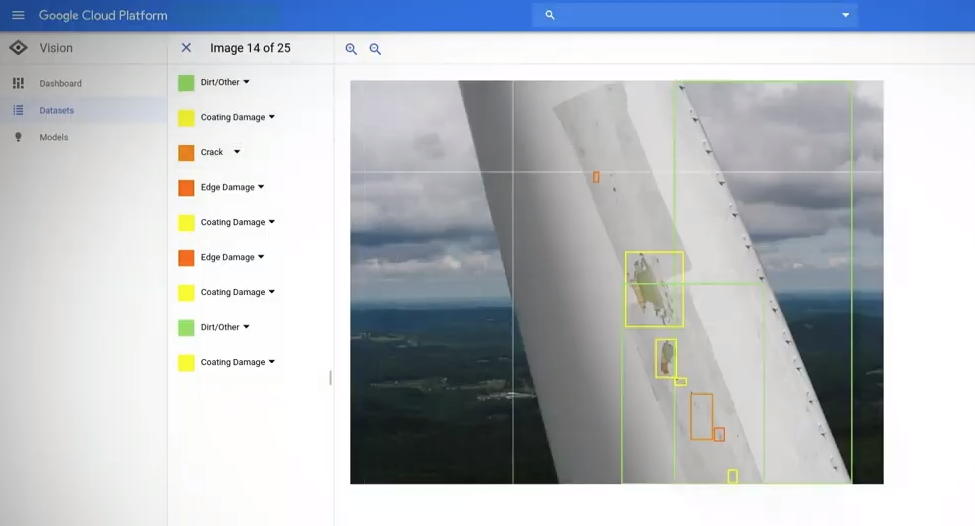
Drone Assessment for Roof Insurance

Roof inspection is dangerous and time-consuming work. Taking measurements by hand or estimating damage manually has always been a part of doing this kind of business. A new approach by using satellite, aerial drone imagery combined with a growing number of other data attributes like historical weather, to determine the characteristics and condition of a roof and the risk of future insurance claims. Computer vision technology can automatically detect roof shape, material, damage, ponding, and rust. Insurers can find the right coverages and pricing for their clients.
You can learn more about the Nanonets solution for roof damage assessment here
Mobile Screen Damage Inspection

Mobile phone insurance is essentially a type of insurance coverage that protects the mechanically damaged mobile phones. Companies selling mobile phone insurance deal with insurance claims with most cases being cracked screen or mobile damage. Automating the greater volume of the claims processing from the mobile phone will cut huge expenses. The main idea is to classify images of mobile phones into two categories. One representing that the mobile is damaged and other being without damage. By combining this approach with OCR for detecting phone serial number and extraction of other important data, claims can be further accelerated.
You can learn more about the Nanonets solution for automatic mobile damage detection here
Optical Character Recognition
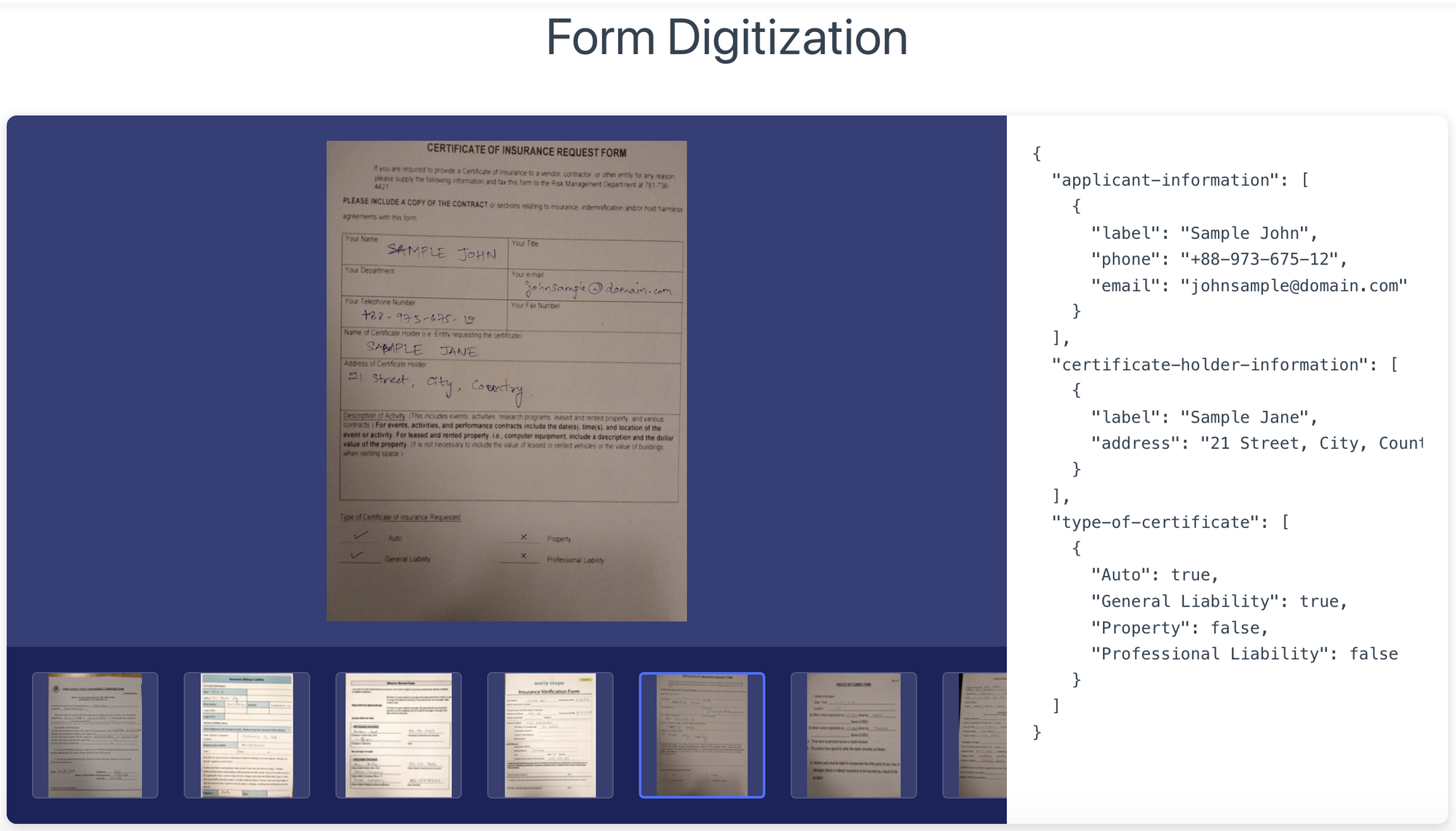
Computer vision task for converting images with characters or scanned documents into machine-readable text. Insurance claims processing with OCR is one of the products that first comes to our mind. In essence, it is the process of automatically filling the forms and documents that have to be systematically processed and digitally stored.
You can learn more about the Nanonets solution for form digitization using OCR here
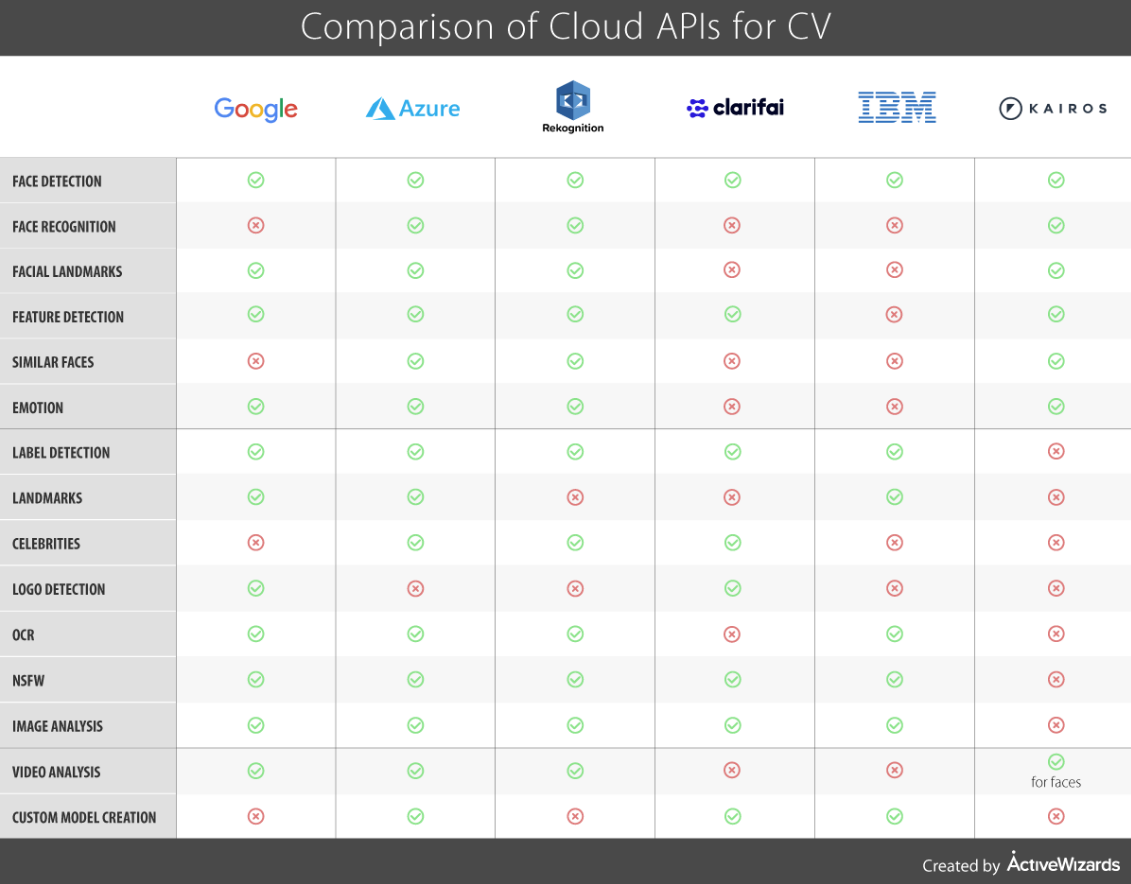
Here is a short overview of the most popular tools and services that can be used for vehicle damage inspection.
Amazon Rekognition makes it easy to add image and video analysis to your applications. It requires no deep learning expertise to use. Rekognition is based on highly scalable, deep learning technology developed by Amazon’s computer vision scientists. Amazon platform offers detection and recognition for objects, events or activities. It is mostly used with face detection, recognition, and identification. Rekognition does not have a model for damage inspection but AWS Marketplace offers several curated third-party software and services that customers need to build solutions and run their businesses. There is no easy solution for creating an image classification model for our specific use-case.
Google Cloud Vision AI could be separated into two bigger categories, AutoML Vision and Vision API. Vision API is API offered by Google pre-trained models similar to Amazon Rekognition and Azure Machine Learning studio. AutoML Vision is very interesting because you can create your custom model by training on custom images. Models are trained to automatically classify images according to labels you define. With a prepared dataset of high-quality images, this seems like the easiest way to develop a robust vehicle damage inspection model. Prepare the images of vehicles into 2 labels (damaged, not damaged) and follow the documentation.
Azure Machine Learning Studio is a simple browser-based, visual drag-and-drop authoring environment where no coding is necessary. A fully-managed cloud service that enables you to easily build, deploy, and share predictive analytics solutions. An interesting approach for visual scripting the models but still domain knowledge of machine learning is required. Developers with expertise can be more efficient using azure machine learning studio or service.
Vehicle damage inspection
Insurers are starting to use deep learning to improve operational efficiency and to enhance the customer experience while reducing the claims settlement time. Computer vision and deep learning predictive models are being developed faster and even without programming skills as many companies offer cloud model training, software-as-a-service or computer vision APIs. Tech giants like Google, Microsoft and Amazon are investing heavily to develop and improve complex algorithms that securely provide hidden and meaningful information from processing images in milliseconds.
Companies often avoid AI-based vision technologies due to their complexity and requirement of developers with extensive expertise. Models that are being used in the production require extensive computational training and generally many sample images. Relevant quality data is hard to gather and for some use-cases, the datasets are simply not available.
Automated vehicle damage inspection is a critical component to efficient vehicle insurance issuer. How the perfect vehicle damage inspection flow would look like?
- The client uploads clear images of the insured vehicle to the insurance claim processing platform
- The platform automatically verifies that images have sufficient quality for running the inspection
- Notifying the client if the images need to be reuploaded.
- Run models for vehicle damage inspection that gives boxes around damaged areas, detect what part of the vehicle is damaged and what kind of damage it might be like rust, dents, scratches, etc.
- The second step could be further processing the damaged vehicle images to make a more detailed report of the damage like identifying which parts of the car got damaged and the severity of the damage.
- Building report that resolves the claim or creates a report to be further reviewed by the manual reviewer in the case of higher uncertainty by the model
Steps to build a Vehicle Damage inspection model
We will now see what are some of the challenges of automatic damage inspection and later we will see a simple model to vehicle damage inspection that can be used with collected data as a baseline model.
Vehicle damage dataset
The main thing when starting deep learning research is to have a high-quality dataset with plenty of images. Deep learning models work better with bigger, more balanced datasets and can be further improved with the addition of the data augmentation process.
Datasets for automatic vehicle damage inspection are not publicly available. Insurance companies involved in vehicle insurance should already have a strategy to collect and organize data collection of vehicle images. This process of collecting and storing data should be employed for all use cases which could be automated in the future. A few examples have already been mentioned like mobile damage inspection and house damage.

Web scraping is one way to generate a starter dataset to create a few base models and ideas. Thanks to FastAI, PyImageSearch you could easily get a decent number of images for any classification problem. Check out these links to see how it is possible PymageSearch Article, Medium Blog, Course video from fastAI for step by step explanation. I will add some hints that helped me:
- Turn off adblocker if you have, because it blocks the method for gathering URLs
- Try using different terms for searching the same dataset
- Store all URLs into excel CSV file and remove duplicates
- After downloading filter to remove non-images
Preprocessing approach
Preprocessing is a method of preparing images for models to achieve better results with computer vision models. It is heavily dependent on the feature extraction method and the input image type. Some of the common methods are:
- Image Denoising – applying a Gaussian or other filter for removing noise from images
- Image Thresholding – method of applying threshold value for every pixel. If the pixel value is smaller than the threshold, it is set to 0, otherwise, it is set to a maximum value
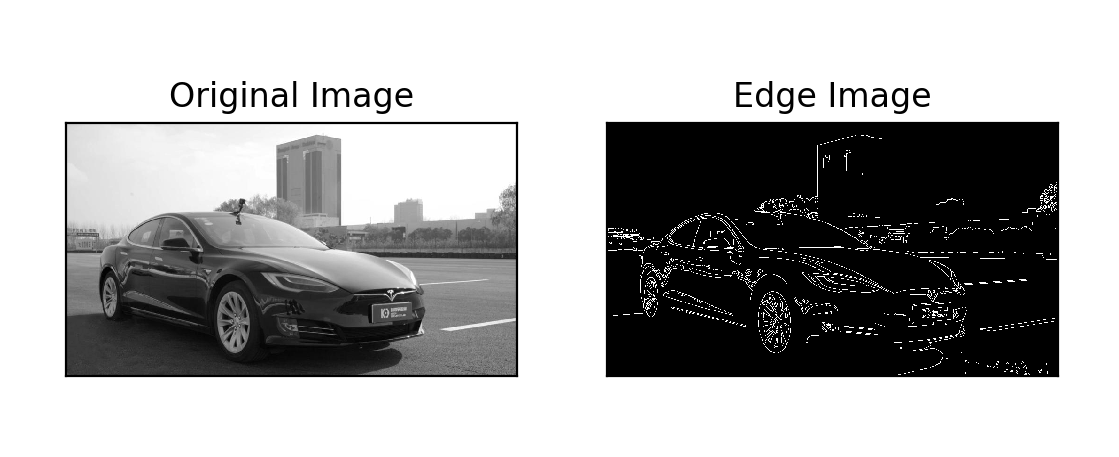
- Canny Edge Detector – most popular edge detector, usually bundled with the process of converting colored images into grayscale images
The most used library for image preprocessing is OpenCV. OpenCV (Open Source Computer Vision Library) is an open-source computer vision and machine learning software library. OpenCV was built to provide a common infrastructure for computer vision applications and to accelerate the use of machine perception in commercial products. It has C++, Python, Java and MATLAB interfaces and supports Windows, Linux, Android, and Mac OS. OpenCV leans mostly towards real-time vision applications and takes advantage of MMX and SSE instructions when available.
The problem with preprocessing is that it is hard to evaluate which preprocessing techniques make a difference generically. Sometimes you can make great progress for your dataset you use but it is beneficial only for subsets of images. The process of evaluating the accuracy gain of the employed preprocessing method is slow and can end up with wrong conclusions.

Lack of publicly available models
A lot of research is done in the field of machine vision in the detection of manufacturing defects. The techniques developed for the manufactury industry require special equipment and approaches but lack of publicly developed models makes it harder to build upon ideas of other researchers. It is not possible to compare performance differences and to have beneficial discussions.
Code and results
I was able to implement a simple classifier for damaged or not damaged vehicles using the fast.ai framework. You can find the notebook in this github repository. The code uses a resnet34 architecture for the classification task and achieves an accuracy of 80% when trained on 60 images of damaged cars and 79 images of not damaged cars.
We are using the fast.ai library since it offers a great API to prototype fast and trying out different models. Fastai has a nice class for handling everything related to the input images for vision tasks. It is called ImageDataBunch and has different functions, respective of the different ways data can be presented to the network. Since our images are placed in folders whose names correspond to the image labels, we will use the ImageDataBunch.fromfolder() function to create an object that contains our image data.
# Create path to your image data
path = Path('data/vehicle')
# Define number of classes, they are called like a folder so it automatically maps from where to read
classes = ['vehicle_damaged', 'vehicle_not_damaged']
# Setting up seed for repetability
np.random.seed(42)
# Create data loader, split images into 80% for training 20% for test and rescale images to 224x224
data = ImageDataBunch.from_folder(path, train='.', valid_pct=0.2, ds_tfms=get_transforms(), size=224, num_workers=4).normalize(imagenet_stats)
# Verify dataset
print(data.classes, data.c, len(data.train_ds), len(data.valid_ds))
# Model training
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
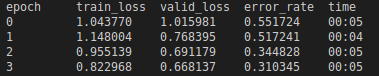
# Train for 4 epochs
learn.fit_one_cycle(4)The model for image classification should train for 4 epochs, meaning it goes through all images of vehicles 4 times while improving model parameters. We can see this from the output because the error rate is going down.
# Save weights, so we don't need to retrain (this matters when training is time consuming)
learn.save('stage-1')
# Must be done before calling lr_find, because we need to unfreeze all layers of the pre-trained model
learn.unfreeze()
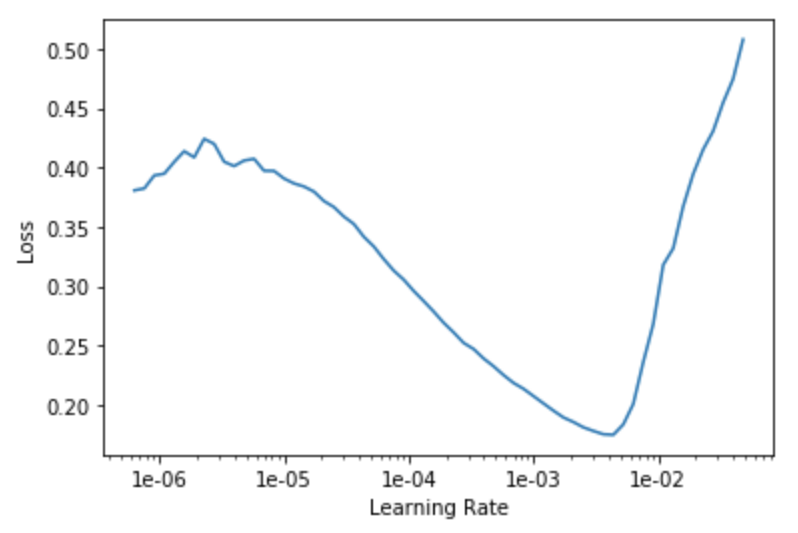
# Plot function for finding the best learning rate
learn.lr_find()
# Visualize graph where loss is depending on picked learning rate
# The best tool to pick a good learning rate for our models
# Here we are taking the value of learning rate with the biggest fall in loss
# in this example it would be [1e-04, 1e-03]
learn.recorder.plot()Here we are saving the trained model so we do not need to repeat that first process. The idea is to use method lr_find(). We want to choose the learning rate that decreases the loss the most. The graph shows that picking the learning rate between [1e-04, 1e-03] decreases loss the most. Now we do not want to pick the learning rate with the lowest loss. Read here for more info about this technique.
# Training model 8 epochs more with learning rates ranging from 1e-04 to 1e-03
learn.fit_one_cycle(8, max_lr=slice(1e-4, 1e-3))
learn.save('stage-2')
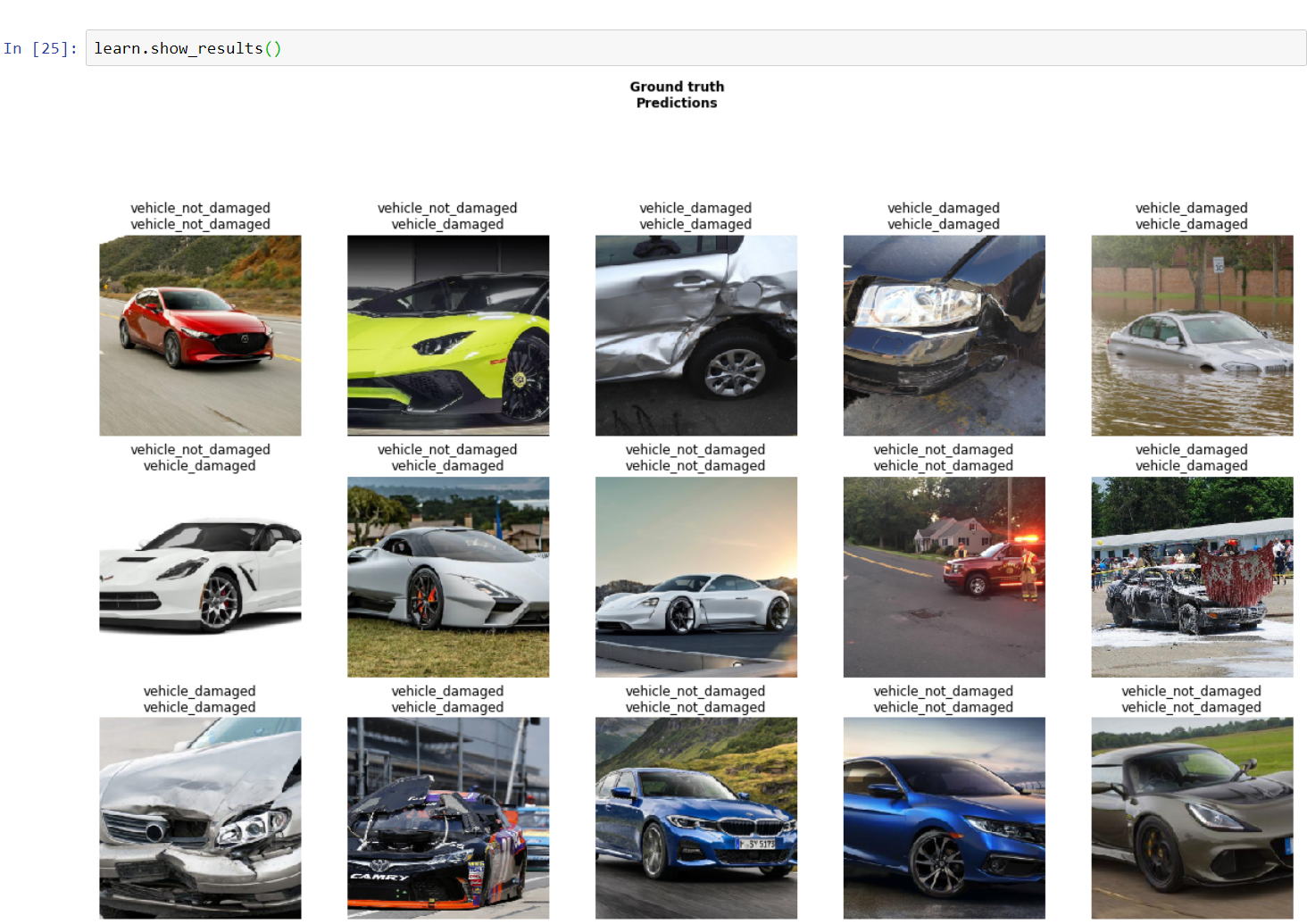
# Show results
learn.show_results()After we have found the best learning rate range, train the model for some time more using this new learning rate range we have found. The idea here is that we train lower layers of the model with lower learning rates because they are pre-trained on the Imagenet. The higher layers should train with a higher learning rate to fine-tune the classification model for our dataset. Note that you will maybe get different levels of accuracy, still around ~ 80% accuracy.
There’s, of course, a much better, simpler and more intuitive way to do this.
Vehicle damage inspection with Nanonets
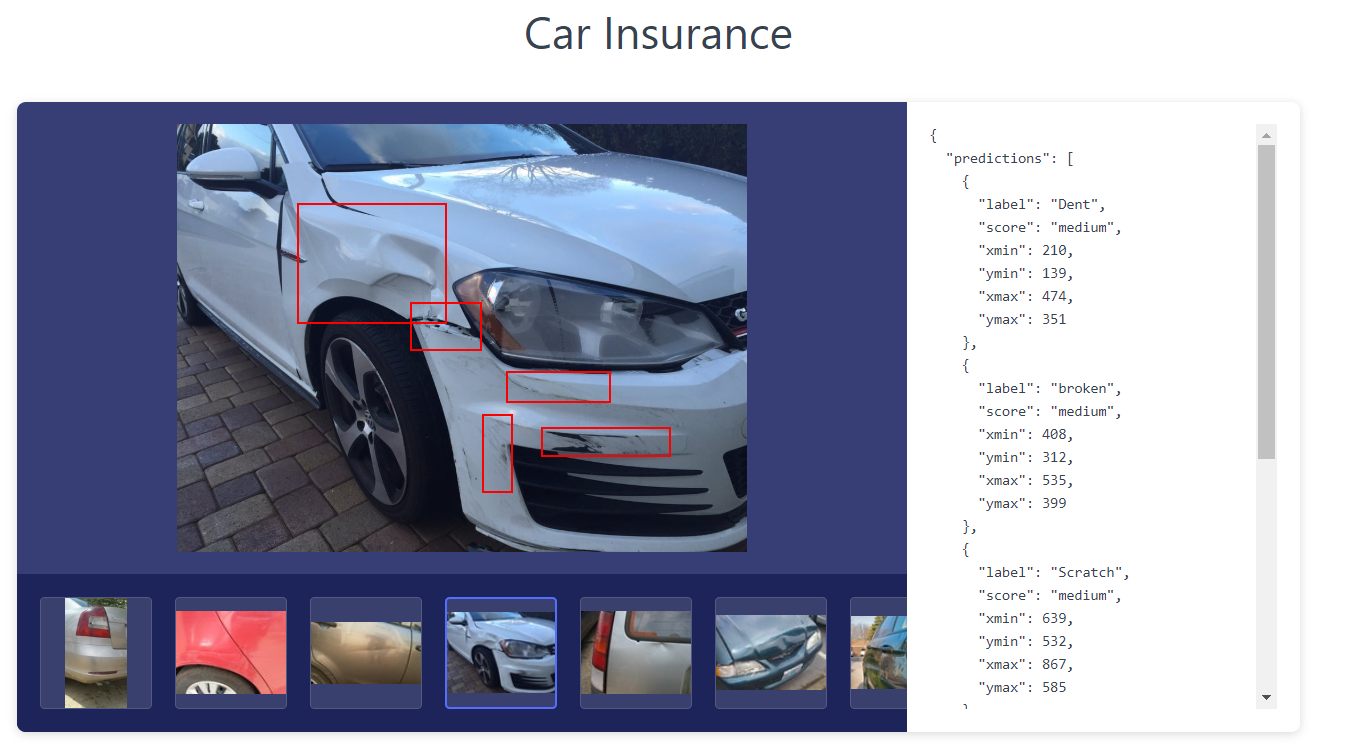
While we have discussed damage detection using image classification, the problem of damage inspection requires much more than just classification models. Using the right models and data can reduce inspection costs by 90%.
Image Classification, Object Detection and Image Segmentation can be used to find out exactly what kind of damage (eg: scratches, dents, rust, broken) is found, at what location (bounding box information) and how severe the damage is.
With more data, you could also build models that would automatically identify which parts of the car (windshield, left door, the right headlight?) are damaged.

You might be interested in our latest posts on:
Start using Nanonets for Automation
Try out the model or request a demo today!
TRY NOW

[ad_2]
Source link