
[ad_1]
In this article, we will look at toxic speech detection, the problem of text moderation and understand the different challenges that one might encounter trying to automate the process. We look at several NLP and deep learning approaches to solve the problem and finally implement a toxic speech classifier using BERT embeddings.
Introduction
As of June 2019 there are now over 4.4 billion internet users. According to the latest Domo Data Never Sleeps report, Twitter users send 511,200 tweets per minute. While that happens, TikTok gets banned in Indonesia, Discord sees an increasing number of neo-Nazi posts, tech and film celebrity accounts get hacked so hackers can spurt out several racist slurs and hate speech volumes rise in India on facebook due to the controversial Citizenship Amendment Act (CAA).
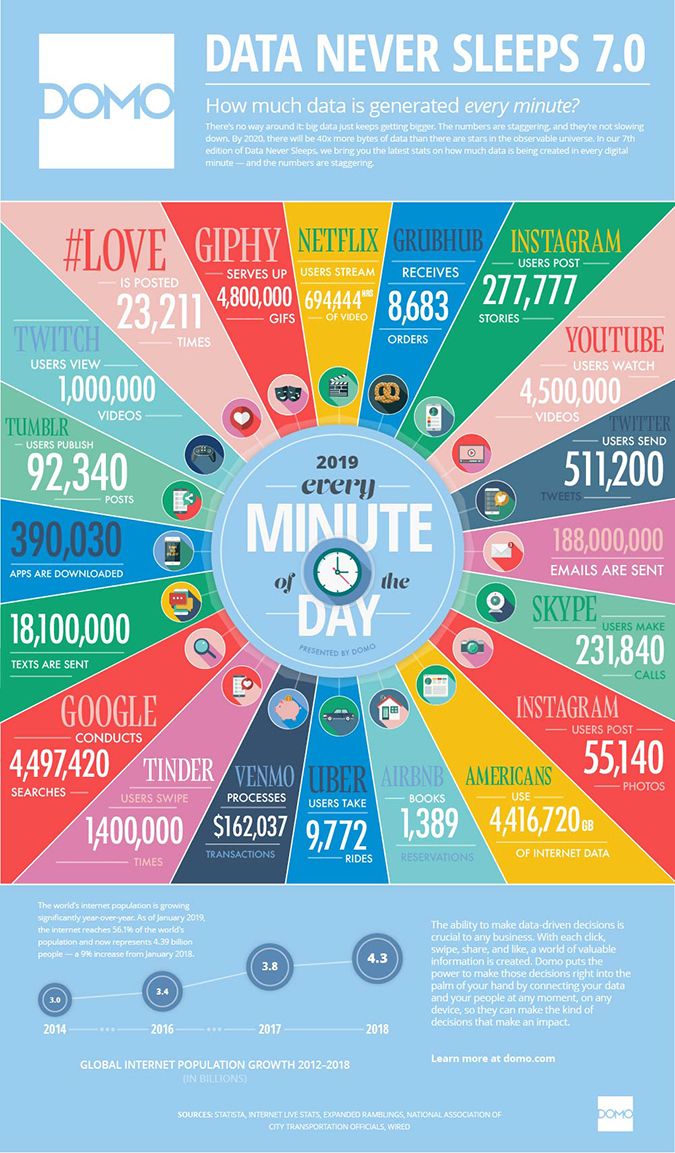
Social media continues to be used by several to incite violence, spread hate and target minorities based on religion, sex, race and disabilities. As the teams behind these platforms continue their efforts towards building a safer, friendlier internet by upping their moderation efforts, hate-mongers and misanthropists find new ways to create enmity between groups – like the crisis in Myanmar, where more than 50 Rohingya settlements were demolished and many men and women subjected to rape, a military-led violent crackdown that resulted in 700,000 Rohingya fleeing over the border. U.N investigators cite the role of facebook in helping the spread of misinformation.
In the midst of all this, content moderators work round the clock for a low wage towards curbing the internet of hatred and perversion and face trauma that leads them suffering mentally due to PTSD.
Moderating Textual Content
According to the UN human rights body,
Hate speech is a term for speech intended to degrade a person or group of people based on their race, gender, age, ethnicity, nationality, religion, sexual orientation, gender identity, disability, language ability, ideology, social class, occupation, appearance (height, weight, hair colour, etc), mental capacity, and any other distinction that might be considered by some as a liability.
Even with this comprehensive definition of what constitutes hate speech, understanding language can be tricky and algorithmically detecting what constitutes hate speech can range from extremely-obvious to even-human-aren’t-sure on the difficulty scale.
Much of this struggle to moderate content is due to the grey areas, where analyzing what kind of violation a comment commits comes with several caveats and foot-notes. Add spelling errors, grawlixes, cultural differences in languages and you realise that a rule based engine that will ban comments based on the use of a few words or phrases is far from enough and requires regular human supervision and assistance.

On the other hand, human moderation can never be seen as a sustainable solution to this problem at this kind of scale and an automation focused approach that can understand the nuances of language, what constitutes hate speech for different languages and in different contexts is a must.
Capturing The Nuances
A report on the 1400 page facebook content moderation rule book that sets up guidelines and rules for moderators to refer to when analysing comments and posts explains the various nuances of this task like, for example, understanding context by looking for indicators in emojis.
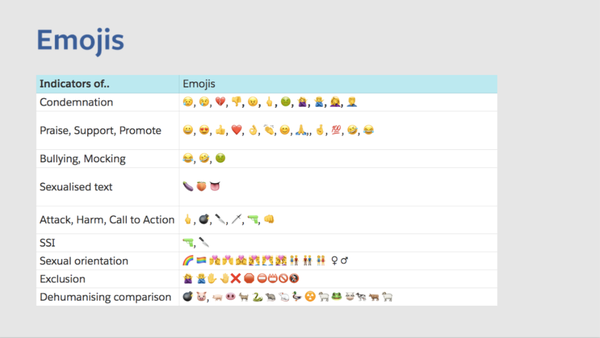
A whole document is devoted to finding out when the utterance of the word “martyr” or “jihad” suggest pro-terrorist intent and many other considerations fill the rule book pages. Even despite the comprehensive nature of the report, over 40% of the Islamophobic and casteist posts that were reported to and removed by facebook were restored after an average of 90 days.
Rule Based Engines with Lexicons
Several people have tried to tackle the automation of text moderation problem by building lexicons that might make detecting hate speech easier. These methods aim to build a large vocabulary of hateful and offensive words and phrases that anyone trying to build a moderation engine can query and match against to find if a particular piece of text is offensive or not.
Here are links to a few hate speech lexicons –
- Sinhalese Racism
- Hate Speech Lexicon
- Youtube Comments Blacklist
- WordPress Comments Blacklist
- List of Dirty, Naughty, Obscene, and Otherwise Bad Words
Hatebase, a Toronto-based company dedicated to reducing the incidents of hate speech and the violence predicated by it provides a broad hate speech vocabulary based on nationality, ethnicity, religion, gender, sexual orientation, disability and class, with data across 95+ languages and 175+ countries.
Many more datasets can be found here.
Why Only Lexicons Don’t Work
Yik Yak ran into a controversy in 2015 when Grace Rebecca Mann, a junior at the University of Mary Washington, and member of UMW’s Feminists United, was killed in April for being outspoken about the school’s rugby team calling for violence against women, including rape and necrophilia. Even if the app filters out certain words like ‘rape’, users have found ways to get around that by using similar sounding words, replacing a few characters with special ones like hyphens or asterisks.
Building a lexicon and the rules that will capture all these syntactical confusions is a mammoth task and more often than not, an impractical way to go about moderating text. Worse is the fact that a purely rule based engine has no understanding of the language, the context of the comment, the intent of the speaker and the hidden semantics only a human listener and reader can hear and see – like sarcasm, condescension etc.
This article correctly points out – besides finding out what content is offensive and to what severity, many more complexities arise when trying to decide what to do with the content – warnings, shadow bans, do nothing, completely remove the content or build/use tools that let users set their own preferences and thresholds. Building tools for such a problem is a mammoth task that requires a deep understanding of natural language processing – understanding semantics, context as well as intent.
Word Embeddings
Much of the ambiguity in text can actually be captured by algorithms without having to hard code each observation, caution or rule about offensive and toxic language. This is made possible by transforming different words into their vector representations. If you are aware of basic NLP concepts, you know there are several ways to do it – frequency based, count based, TF-IDF based, skip grams, bag of words, etc. You can learn more about these here.
An advantage of turning words, phrases or sentences to vectors is that the abstraction of context and semantics of the sentence allow us to map sentences spatially onto a latent space where we can them measure their similarity with other words in their neighborhood, words farther from them in the vector space and other relationships between different words, the contexts in which they occur and their meanings. This allows us to detect overarching emotions and sentiments that shape the way a sentence is delivered and also comprehended.
Understanding The Moderation Problem
There are several approaches to the problem of text moderation. Some of them try to find certain words, phrases in the text while some others try to classify a comment into different categories based on the degree of offensiveness in the comments as is understood by their feature representations.
Let’s look at the different ways people have tried to understand language and hate speech. We will move step by step. We will first understand pure sentiment analysis and how word representations help us understand a lot more than meets the eye of the reader. We will then understand the hate speech and offensive language specific features. After doing so, we will look at how machine learning is applied to automatically lewarn from available data to detect hate speech in unseen sentences and comments.
Sentiment Analysis
This paper about SO-CAL or the Semantic Orientation Calculator captures the essence of all the different details one needs to consider while doing corpus based sentiment analysis – understanding adjectives, nouns, verbs, adverbs and how they relate with each other in terms of meaning as well as intensity, understanding intensifiers and how they might affect the polarity of a particular comment, understanding negations and blocking irrealis moods.
Another paper on sentiment analysis that chalks out the hourglass of emotions can be used to get a deeper psychological insight into our tweets/comments before running them through hate speech specific lexicons.

The lexicon built from the Hourglass of Emotions study – SenticNet, provides a way to understand contextual information in text by using a bag of concepts model which creates concepts through clustering word vectors generated from word2vec, and uses the frequencies of these concept clusters to represent document vectors. This helps get rid of the curse of dimensionality due to the bag of words model and lack of transparency in the Doc2Vec representations.
Looking for Microagressions
Breitfeller et al. tackle building a toxic language lexicon by looking for microaggressions – comments or actions that subtly and often unconsciously or unintentionally express a prejudiced attitude toward a member of a marginalized group. Microaggressions are often veiled in euphemisms, ironies, sarcasm, generalisations etc, and are harder to detect using a predefined lexicon of offensive words and phrases. To address this issue, the authors attempt to create a new typology for identifying microaggressions and using the same for text moderation.

Their new typology builds upon the work of Sue et al. with the goal to create a typology that generalises well over all different themes of microaggressions presented in the paper. The subthemes are categorized into 4 major themes of microaggressions – attributive, institutionalized, teaming and othering. The code can be found here.
Us and Them – The Language of Othering
Alorainy et al. proposes a novel framework that utilises language use around the concept of ‘othering’ – the use of language to express divisive opinions between the in-group (‘us’) and the out-group (‘them’), for example, around immigration and terrorism.

A preliminary justification for this approach is provided by analysing the number of tweets in their corpus which classify as hate speech and included two sided pronouns against those that included these pronouns and did not fall in the category of hate speech. The results can be seen in the above graph where it is quite evident that two-sided pronouns are a lot more frequent in anti-islamist and anti-semetic language. In general, any form of offensive language is seen to have a significant increasing chance of also including othering language.

The paper mentioned above used two datasets to build their ‘Othering’ language lexicon, one that classifies tweets as including hate speech, offensive language or ones that contain neither and another one that tries to answer a single question about the text in question – Is this text antagonistic or hateful based on a protected characteristic? The corpus is built by getting the dependency relationships and PoS tags, narrowing down to the ones absolutely necessary and creating Doc2Vec embeddings using the distributed memory model for the extracted corpus.
Semi-automated Lexicon Building
Njagi et al. attempts to abstract hate speech into three areas – race, religion and nationality, identify polarity in subjective sentences and builds a lexicon for hate speech. They use the Subjectivity Lexicon which describes the polarity of words and phrases (positive, negative, neutral) and the degree of polarity (strongly negative, weakly negative). To build the lexicon, they use the words and phrases in the above lexicon that would be high on the negativity scores or would be highly subjective. They also use a seed list of hate verbs to find synsets and hypernyms to grow their hate speech lexicon. Following this they build a rule based classifier based on the lexicon – finding text which has several strongly negative words, words from the lexicon appearing alongside strongly or weakly negative words and themed nouns co-occurring with strongly negative words or words from the lexicon in the same noun phrase.
Embeddings, Sentiment Scores and Classifiers
Ahluwalia et al. applied an ensemble of classifiers containing a Logistic regression model, an SVM, a random forest, a gradient boosting model, and a stochastic gradient descent model, all trained on a BOW representation of the tweets followed by a sentiment analysis using SentiWordNet to detect misogynistic tweets.
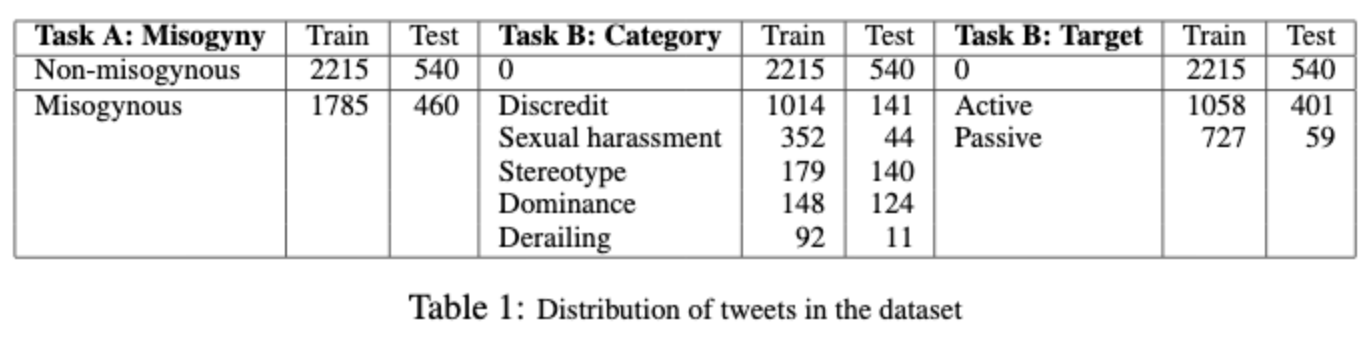
They also incorporate sentiment scores and the following lexical features about the tweets to improve results – link presence, hashtag presence, swear word presence, swear word count, sexist slur presence and women word presence. While adding these lexical features improves the results on Task A –
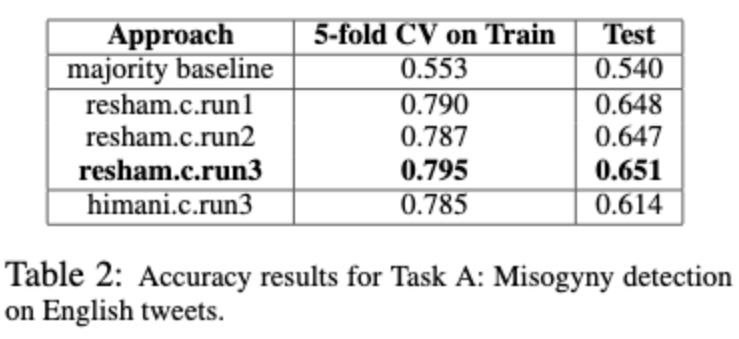
Their BOW + senetiment scores + ensemble of classifiers performs the best on Task B.

Solving with Deep Learning
Deep Learning has shown a lot of promise in solving natural language processing tasks. Here we will look at some key papers using deep learning for the task of hate speech detection and the promising directions in which the research in this domain could head.
Embeddings, CNNs and LSTMs
Holgate et al. attempt to solve the problem for Vietnamese social media text by using Bi-GRU-LSTM-CNN model. The labels include hate, offensive and clean. The authors chose to use fasttext embeddings. The model architecture is a sort of siamese network with one network being a Bi-GRU + 1D CNN whereas the other one is a Bi-LSTM + 1D CNN. The outputs of the two are concatenated after pooling and finally passed through a Dense layer to get the classification outputs. The architecture is detailed below.

The authors attempted to solve the hate speech detection task proposed at the VLSP Shared Task 2019. Their official result is 70.576% of F1-score, ranking the 5th of the scoreboard on the public-test set. The results are summarized below.

Badjatiya et al. compares several different deep learning algorithms on the hate-speech detection task – whether the tweet in question is sexist, racist or neither. They experimented with a dataset of 16K annotated tweets. Of the 16K tweets, 3383 are labeled as sexist, 1972 as racist, and the remaining are marked as neither sexist nor racist.
The experiments are divided into three parts. The first part is for baseline methods and baseline methods combined with an ensemble method – gradient boosting decision trees. The second one tests the proposed embeddings along with the deep learning methods mentioned above. The final part adds the gradient boosting classifier on top of the deep learning experiments proposed in the second part. The results are summarized below.

Stereotypes, Bias and Embeddings
There hasn’t been a lot of work done in the field of AI fairness. While bias removal has been studied for structured data, Badjatiya et al. attempt to solve this for unstructured data. They find that several predictions by hate speech detectors trained on transferred word embeddings without any bias mitigation strategy learn to interpret data in a wrong manner. Some examples are shown below.

They adapt a two stage debiasing approach. First stage involves finding bias sensitive words – words that introduce an unreasonable amount of bias in the classifier. They do this by doing the following –
- Create a manual list of words that are of a similar nature but are disproportionately present in hateful samples.
- Get a list of words by calculating their Skewed Occurrence Across Classes (SOAC) – define a term frequency threshold. Sort a list of words that have a higher document frequency in the ‘hateful’ class and cross the term frequency threshold in the dataset.
- Understand the classifier bias by calculating the Skewed Predicted Class Probability Distribution (SPCPD) – the probability with which the classifier predicts the class for a single word.
The second stage involves the debiasing of the data itself. This is done by correcting your data by removing all private attributes like gender, caste, religion, age, etc and replacing them with generic tags. Example – ‘An Indian guy’ would change to ‘An <NATIONALITY> guy’. Likewise, they replace try different replacements for the bias sensitive words like PoS tags, NE tags, K-nearest neighbor and knowledge based generalisations like replacing them with their hypernyms as found in its WordNet synsets. The combine different approaches in a final method which includes taking into account the latent representation of words, finding similar words with same PoS usage, finding the K nearest neighbors, and generalising the word vector to the embedding for its centroid.
Once that is done, the transformed data is run through a CNN based classifier. The results are detailed in the table below –

Transformers and Transfer Learning
In a nutshell, attention is a feed-forward layer with trainable weights that help us capture the relationships between different elements of sequences. It works by using query, key and value matrices, passing the input embeddings through a series of operations and getting an encoded representation of our original input sequence. Transformers use multi-headed attention to better learn long range dependencies in sequential tasks. Another important addition is a positional embedding that encodes the time at which an element in a sequence appears. These positional embeddings are added to our input embeddings for the network to learn time dependencies better.

Mozafari et al. use BERTbase – a model which contains an encoder with 12 layers (transformer blocks), 12 self-attention heads and 110 million parameters. Extracted embeddings from BERTbase have 768 hidden dimensions. They use pre-trained weights for BERT trained on the English Wikipedia and the Book Corpus. They transfer these weights to different deep learning architectures (simple softmax classification, multiple nonlinear layers, CNNs and LSTMs) and compare the precision, recall and f1 scores on two different datasets. The results are summarised below.

[Code] BERT + CNNs for text moderation
Besides the approaches mentioned above, there are several other methods and pipelines we can adopt to solve this problem – training named entity recognition models for offensive language, trying different kinds of embeddings, different deep learning architectures.
We will implement a Multi-label classifier which takes BERT pre-trained embeddings as inputs and passes them through a CNN based classification architecture for predictions.
Time to get our hands dirty!
We will be implementing the BERT + CNN model using Pytorch and the Hugging Face transformers library for our implementation. The dataset used is taken from the Kaggle Toxic Comments Challenge and can be downloaded from here. An exploratory analysis of the data can be found here.
Full code can be found in this repository.
Getting Input Examples
The Hugging Face transformers require us to input our data in the form of a TensorDataset which is created by turning our sample data points into Example objects that are further turned into Features. You can learn more here.
class InputExample(object):
def __init__(self, id, text, labels=None):
self.id = id
self.text = text
self.labels = labelsGetting Input Features
Once we have the examples, we will create features from our examples using a Tokenizer. We will define our Tokenizer, Bert Model and the CNN architecture later in this post. The convention for BERT as mentioned in the transformers utils code is this –
The convention in BERT is:
(a) For sequence pairs:
tokens: [CLS] is this jack ##son ##ville ? [SEP] no it is not . [SEP]type_ids: 0 0 0 0 0 0 0 0 1 1 1 1 1 1
(b) For single sequences:tokens: [CLS] the dog is hairy . [SEP]type_ids: 0 0 0 0 0 0 0
Where "type_ids" are used to indicate whether this is the firstsequence or the second sequence. The embedding vectors for type=0 andtype=1 were learned during pre-training and are added to the wordpieceembedding vector (and position vector). This is not strictly necessarysince the [SEP] token unambiguously separates the sequences, but it makesit easier for the model to learn the concept of sequences.
For classification tasks, the first vector (corresponding to [CLS]) isused as the "sentence vector". Note that this only makes sense becausethe entire model is fine-tuned.After we have tokenized our text, converted it into the format required as mentioned above, we use the Tokenizer to convert tokens to their corresponding vocabulary IDs using the tokenizer.convert_tokens_to_ids() method. We create segment IDs and input masks and pad the sequences if the sequence length is lesser than the maximum sequence length for our Bert model. Our input feature objects look like this –
class InputFeatures(object):
def __init__(self, input_ids, input_mask, segment_ids, label_ids):
self.input_ids = input_ids
self.input_mask = input_mask
self.segment_ids = segment_ids
self.label_ids = label_idsPreparing the Dataset using BERT
Once we have the features, we convert them into torch tensors which is then converted to a TensorDataset. This allows us to use a DataLoader to iterate through the data in batches.
We get our Bert pretrained model and tokenizer and load it on our GPU. The transformers library provides a lot of different pre-trained weights for a lot of different transformer architectures. If interested, you can definitely experiment other transformers like XLNet, GPT, etc for this task.
device = torch.device(type="cuda")
pretrained_weights="bert-base-cased"
tokenizer = BertTokenizer.from_pretrained(pretrained_weights)
basemodel = BertModel.from_pretrained(pretrained_weights)
basemodel.to(device)We will now use the tokenizer to create our dataset, split the dataset in train and eval batches and prepare out DataLoaders for the training process. We use a sequence length of 256 and a batch size of 8 because increasing either caused OOM errors on my GPU. You can fiddle around with these numbers if you have access to more compute.
Defining our CNN model
We will define our CNN model as is mentioned in this paper and implemented here. The model used passes the Embeddings from BERT through three convolutional layers parallelly of different kernel sizes, concatenates the pooled outputs of them and finally passes them through to a linear layer to get the classification outputs.
class KimCNN(nn.Module):
def __init__(self, embed_num, embed_dim, dropout=0.1, kernel_num=3, kernel_sizes=[2,3,4], num_labels=2):
super().__init__()
self.num_labels = num_labels
self.embed_num = embed_num
self.embed_dim = embed_dim
self.dropout = dropout
self.kernel_num = kernel_num
self.kernel_sizes = kernel_sizes
self.embed = nn.Embedding(self.embed_num, self.embed_dim)
self.convs = nn.ModuleList([nn.Conv2d(1, self.kernel_num, (k, self.embed_dim)) for k in self.kernel_sizes])
self.dropout = nn.Dropout(self.dropout)
self.classifier = nn.Linear(len(self.kernel_sizes)*self.kernel_num, self.num_labels)
def forward(self, inputs, labels=None):
output = inputs.unsqueeze(1)
output = [nn.functional.relu(conv(output)).squeeze(3) for conv in self.convs]
output = [nn.functional.max_pool1d(i, i.size(2)).squeeze(2) for i in output]
output = torch.cat(output, 1)
output = self.dropout(output)
logits = self.classifier(output)
if labels is not None:
loss_fct = nn.BCEWithLogitsLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1, self.num_labels))
return loss
else:
return logitsNow we create our KimCNN model according the BERT embedding dimensions.
embed_num = seq_len
embed_dim = basemodel.config.hidden_size
dropout = basemodel.config.hidden_dropout_prob
kernel_num = 3
kernel_sizes = [2,3,4]
num_labels = 6
model = KimCNN(embed_num, embed_dim, dropout=dropout, kernel_num=kernel_num, kernel_sizes=kernel_sizes, num_labels=num_labels)
model.to(device)Training the model
Finally we define our optimizer and begin training! In each epoch, we iterate through the training dataset in batches, get the embeddings from our base model, pass them through KimCNN, acquire the loss and back-propagate.
lr = 3e-5
epochs = 1
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
labels = ['toxic', 'severe_toxic', 'obscene', 'threat', 'insult', 'identity_hate']
for i in tqdm(range(epochs)):
model.train()
for step, batch in enumerate(train_dataloader):
batch = tuple(t.to(device) for t in batch)
input_ids, input_mask, segment_ids, label_ids = batch
with torch.no_grad():
inputs,_ = basemodel(input_ids, segment_ids, input_mask)
loss = model(inputs, label_ids)
loss = loss.mean()
loss.backward()
optimizer.step()
optimizer.zero_grad() We save the model to our disk for future use.
torch.save(model.state_dict(), './trained_model')And we are done!
To evaluate our model in each model, we use our validation dataset and also acquire the ROC AUC for each class. At the end of the first epoch, we get the following ROC AUC values –
ROC AUC per label:
toxic : 0.9605486064463264
severe_toxic : 0.9841929394445961
obscene : 0.9621109584292289
threat : 0.7886769265503675
insult : 0.9427310938607746
identity_hate : 0.905177301817393And our predictions look something like this –
Comment:
What on earth does anti - semitism have to do with the notion that the US military shot down the plane, Cberlet? I am quite mystified.
Prediction:
toxic : 0.055252425
severe_toxic : 0.002406106
obscene : 0.04549172
threat : 0.0027631551
insult : 0.024192393
identity_hate : 0.0069899107
---------------------------------
Comment:
WikiAwards Hi there. Just to thank you for being the 2nd participant in the WikiAwards Project. Unfortunately the project is causing some controversy and I need to know if it is worth going on. I respect your neutrality but for now I really need to know if there's anybody in this world that supports my idea. I truly believe it is a great way of developing Wikipedia. 05 : 36, 27 Aug 2004 ( UTC )
Prediction:
toxic : 0.0039544455
severe_toxic : 9.456437e-05
obscene : 0.009531345
threat : 0.00067216606
insult : 0.0016024308
identity_hate : 0.0007145586
---------------------------------
Comment:
I'm afraid not. I think you need to ask somebody who's an administrator on Commons. ( I'm an admin on en. wiki, not on Commons. ) — Talk / Stalk
Prediction:
toxic : 0.017199917
severe_toxic : 0.0008454597
obscene : 0.025758682
threat : 0.002444282
insult : 0.008249491
identity_hate : 0.0033726753
---------------------------------
Comment:
Hey useless troll, you just don't get tired enough of being stomped again and again, right?
Prediction:
toxic : 0.7409974
severe_toxic : 0.098911814
obscene : 0.21756598
threat : 0.007269864
insult : 0.27900904
identity_hate : 0.04931407
---------------------------------
Comment:
= = Rambling, discoursive article There was evidently an edit war on this page a number of years ago, although I have trouble understanding exactly what it was about. As a result, the article reads very poorly now. There is, for instance, no clear summary of the timeline, e. g., how many months did the Satyagraha last? I'm not in a position to sort out what happened ( knowing very little of the history ), but I hope someone can step up and tidy this up.
Prediction:
toxic : 0.007893627
severe_toxic : 0.0002704348
obscene : 0.015856728
threat : 0.0005324769
insult : 0.006508061
identity_hate : 0.001252369Hope you enjoyed the read.
You might be interested in our latest posts on:
Start using Nanonets for Automation
Try out the model or request a demo today!
TRY NOW

[ad_2]
Source link