
[ad_1]
Machine learning, and especially deep learning, has become increasingly more accurate in the past few years. This has improved our lives in ways we couldn’t imagine just a few years ago, but we’re far from the end of this AI revolution. Cars are driving themselves, x-ray photos are being analyzed automatically, and in this pandemic age, machine learning is being used to predict outbreaks of the disease, help with diagnosis, and make other critical healthcare decisions. And for those of us who are sheltering at home, recommendation engines in video on-demand platforms help us forget our troubles for an hour or two.
This increase in accuracy is important to make AI applications good enough for production, but there has been an explosion in the size of these models. It is safe to say that the accuracy hasn’t been linearly increasing with the size of the model. The Allen Institute of AI, represented by Schwarz et al in this article, introduces the concept of Red AI. They define it as “buying” stronger results by just throwing more compute at the model.
In the graph below, borrowed from the same article, you can see how some of the most cutting-edge algorithms in deep learning have increased in terms of model size over time. They are used for different applications, but nonetheless they suggest that the development in infrastructure (access to GPUs and TPUs for computing) and the development in deep learning theory has led to very large models.
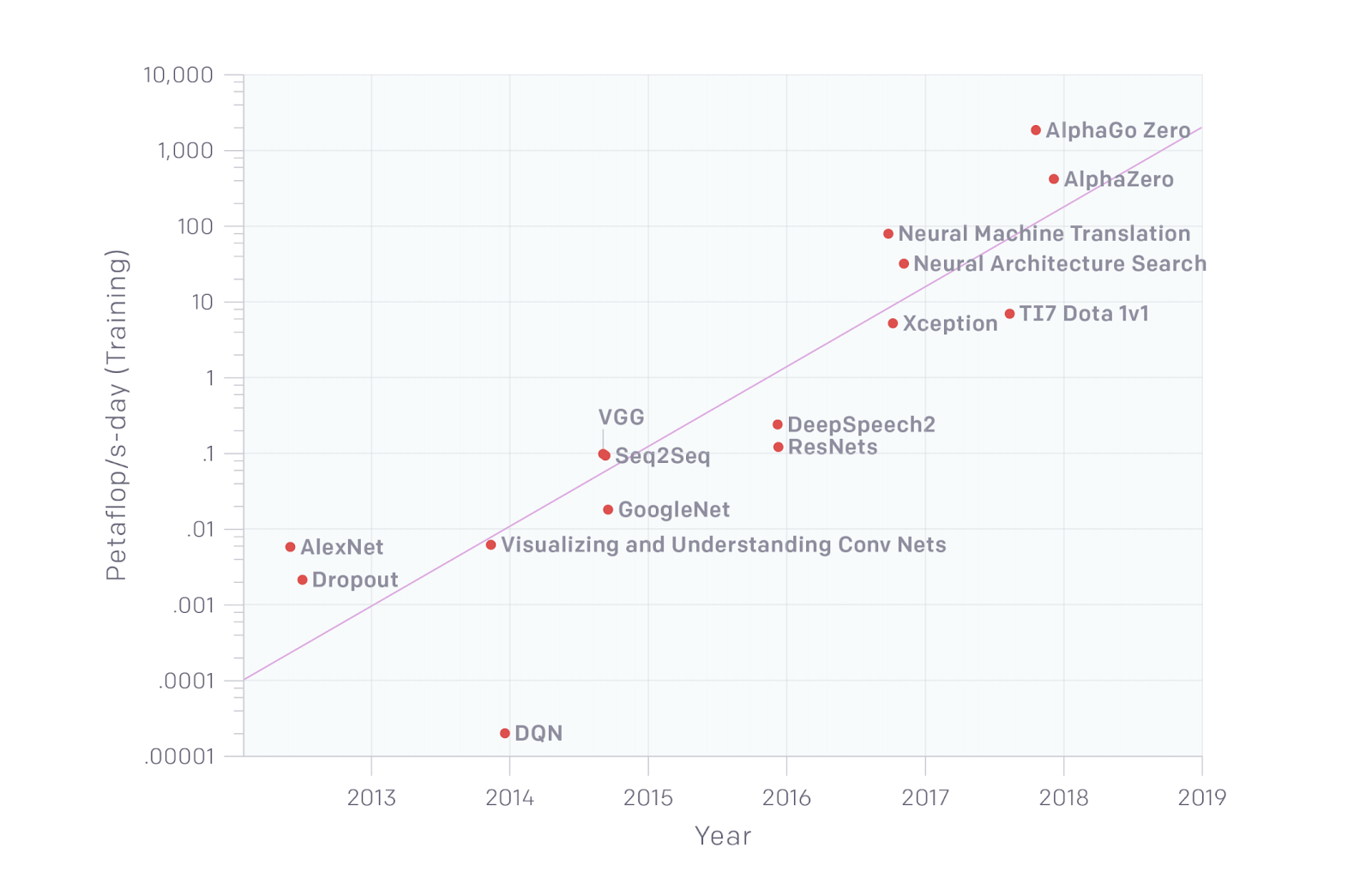
The natural follow-up question is if this increase in computing requirements has led to an increase in accuracy. The below graph illustrates accuracy versus model size for some of the more well-known computer vision models. Some of the models offer a slight improvement in accuracy but at an immense cost of computer resources. Leaderboards for popular benchmarks are full of examples of Red AI where improvements are often the result of scaling processing power.
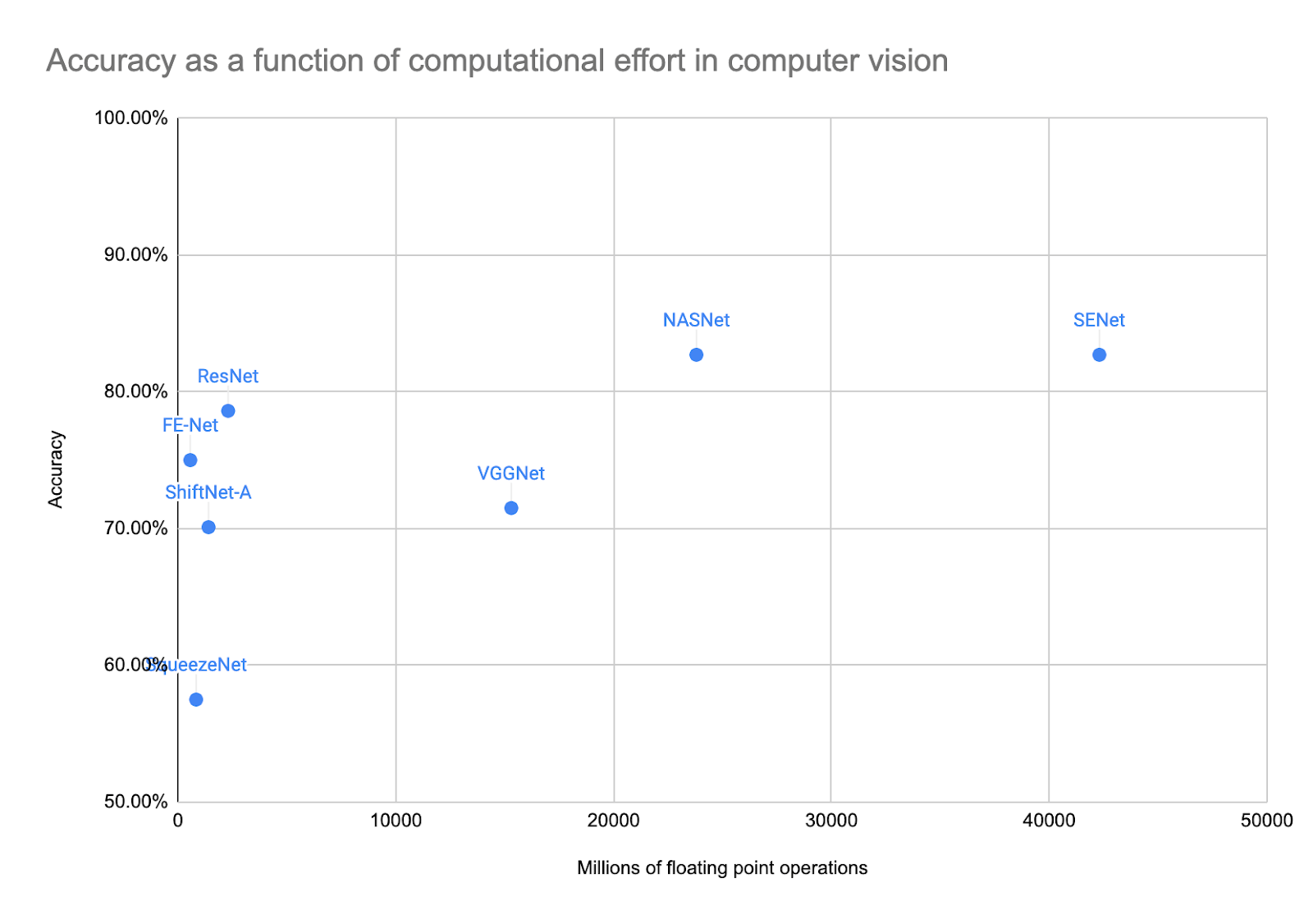
Here, model size is measured by the amount of floating-point operations. As you can see above, the bigger models are more accurate on average, but some of the smaller models (ResNet and FE-Net most prominently) are almost on par in terms of accuracy.
Why should you care? Because model size poses a cost for whoever is paying for your infrastructure, and it also has implications for our environment, as the computational needs of bigger models drain more power from our infrastructure.
To illustrate the energy needed in deep learning, let’s make a comparison. An average American causes a CO2 footprint of 36,000 lbs in one year, while the deep learning Neural Architecture Search (NAS) model costs approximately 626,000 lbs of CO2. That’s more than 17x the average American’s footprint in one year. Furthermore, it costs somewhere between $1 and $3 million in a cloud environment to train. The Natural Language Processing (NLP) model BERT costs approximately 1,400 lbs of CO2 (4% of the average American) and somewhere between $4,000 to $12,000 to train in the cloud.
How can we shift from Red AI that is inefficient and unavailable to the public to efficient and democratic Green AI?
1. Get your power from a renewable source
Needless to say, anything is green if it is powered by something renewable. However, even if your power is from a renewable source, doing unnecessarily power-consuming model building may lead to you using energy that could have been put to better use elsewhere.
2. Measure efficiency, not only accuracy
Machine learning has been obsessed with accuracy — and for good reason. First of all, if a model isn’t accurate enough for what you want to use it for, it can’t be put into production. Second, accuracy is easy to measure, although there are many ways to do it and sometimes it’s hard to prove that the result you obtain is really an unbiased estimate on real-life performance.
Also easy to measure but often overlooked is the resource cost it takes to build a model and to get predictions from it. This comes in many versions, such as time or energy required to train the model, time or energy required to score new data (“inference”), as well as model size (in megabytes, number of parameters, and so forth). Schwarz et al have a comprehensive discussion on which of these metrics are the best, and I recommend their article on this topic. As a hardware-independent metric, they recommend the amount of floating-point operations (FLOPs) to measure model size. However, this can be difficult to retrieve from whatever software you use to build models.
In a green machine learning study from Linköping University, a combination of accuracy and resource cost is proposed as a way to measure efficiency, with citations from other literature on the topic and summarized for convenience. All efficiency metrics derive from this logic:
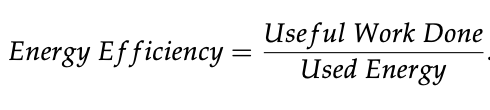
These are various examples the study mentions:

Let’s examine what happens if we apply these metrics to our above computer vision models.
In the graph below, you see that if you divide accuracy with the number of floating point operations (a measure of computing resources), you get the “Model Size Efficiency” as defined above. In this case, that question is, “how many percentage points of accuracy do you get for each billion floating-point operations in it?” Compare it to the previous graph, and you see that the highly accurate SENet and NASNet are actually the least efficient.
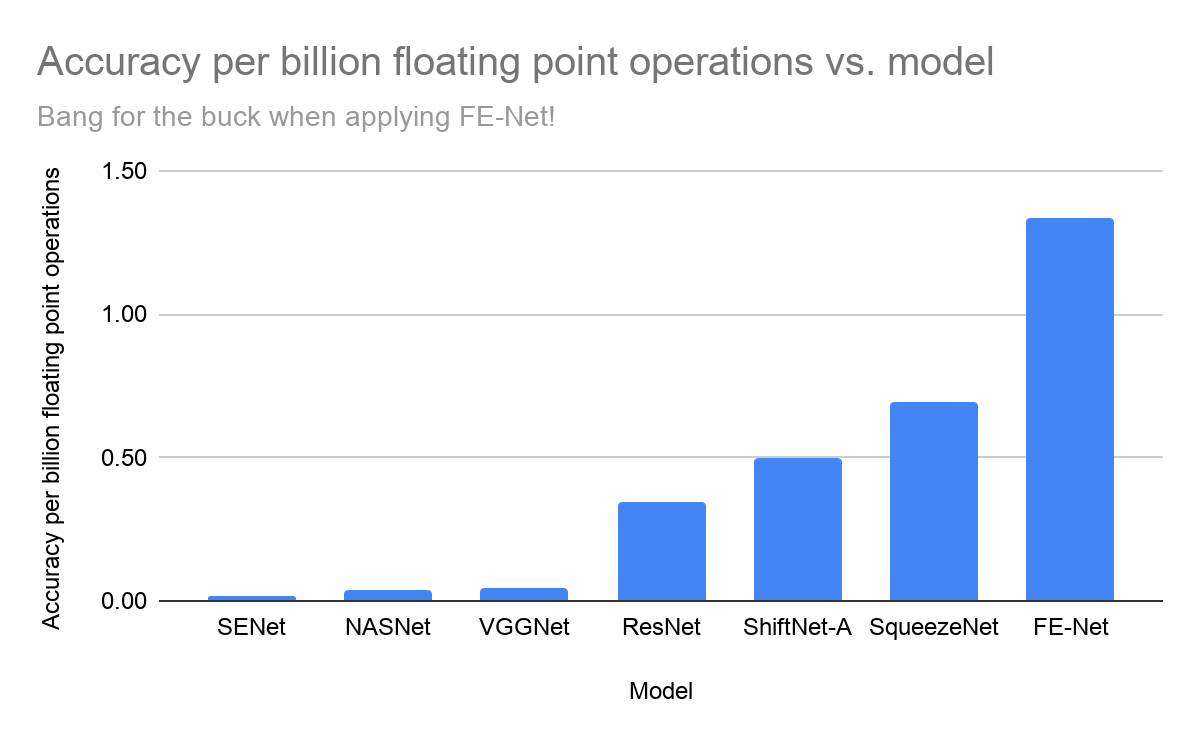
However, one must remember that in the scoping of a machine learning project, an acceptable accuracy should be discussed, (i.e., how accurate does the final model need to be? And how fast can it make predictions?). Many things need to be considered jointly before selecting a final model. If the most efficient model in your case would have been the SqueezeNet, it should also be noted that it is, at least in the case above, significantly less accurate than some much larger models. Is this acceptable? That depends on your use case.
Conclusion
Earth Day is a good time for the machine learning community to think about factors other than accuracy, such as efficiency. When the goal is to improve model accuracy, can we consider other approaches besides throwing megatons of computing at the problem? The real progress would be to make that improvement while balancing the use of our resources. To better quantify this, we have developed methods to measure efficiency. For us, we believe in using efficiency metrics in machine learning software.
On April 22nd, I’m holding a webinar on green machine learning, where we’ll take an in-depth look at theoretical and practical ways to improve efficiency in machine learning. Join us. And if you cannot do that, watch this space for a future blog post with some tips and tricks.

About the author
Customer-Facing Data Scientist for DataRobot
He provides technical guidance to businesses across the Nordics to help ensure they are successful. He conducts demonstrations, delivers proofs-of-concept and solves business problems with AI. He started out as an aspiring political scientist but then fell in love with quantitative methods and became a statistician at Uppsala University.
Meet Oskar Eriksson
[ad_2]
Source link