
[ad_1]
Want to extract data from printed or handwritten forms ? Check out Nanonets™ form data extractor for free & automate the export of information from any form!
Forms are everywhere; they are defined as documents created to collect information by asking the participants to fill out the information needed in a specific format. They are helpful because of their ability to gather a lot of data in a short time. However, not all forms have the same capacity for collecting data and often require manual work later. Therefore, we rely on tools and algorithms to intelligently automate the process of form data extraction. This blog post will deep dive into different scenarios and techniques to extract data from forms using OCR and Deep Learning.
Form Data Extraction is the process of extracting data from forms – both online and offline. This data can be found in any format, usually containing a form with the relevant information. However, extracting this data is not always an easy task because many layouts and designs do not allow text to be selected easily. There is no native way of copying data from them. Therefore, we rely on automated techniques to help extract data from forms that are more effective and less error-prone.

For example, today, many users depend on PDF-based forms to collect contact information. This is a highly efficient way to gather information because it does not require the sender and recipient to provide input. But extracting this data from a PDF form can be challenging and expensive.
Here, form data extraction can help extract data from a PDF form, such as name, email address, phone number, etc. It can be imported into another application like Excel, Sheets, or any other structured format. The way it works is the extraction tools read over the PDF file, automatically pull out what it needs, and organize it in an easy-to-read format. This data can be exported into other formats like Excel, CSV, JSON, and other well-structured data formats. In the next section, let’s look at some of the frequently encountered challenges when building form data extraction algorithms.
Want to extract data from printed or handwritten forms ? Check out Nanonets™ form data extractor for free & automate the export of information from any form!
Data extraction is an exciting problem for a variety of reasons. For one, it is an image recognition problem, but it also has to consider the text that may be present in the image and the layout of the form, which makes building an algorithm more complex. This section discusses some of the common challenges people encounter when building form data extraction algorithms.
- Lack of Data: Data Extraction algorithms are usually built using powerful deep learning and computer vision-based algorithms. These typically rely on vast amounts of data to achieve state-of-the-art performance. Thus, finding a consistent and reliable dataset and processing them is crucial for any form of data extraction tool or software. For example, say we have forms with multiple templates, then these algorithms should be able to understand a wide range of forms; therefore training them on a robust dataset would have a more accurate performance.
- Handling Fonts, Languages, and Layouts: There are dizzying amounts of different typefaces, designs, and templates available for different kinds of form data. They may fall into several completely different classifications, which makes it challenging to ensure accurate recognition when there’s a vast amount of different character types to take into account. Hence it’s important to limit the font collection to a particular language and type because it will create many processes that flow smoothly once you have those documents appropriately processed. In multilingual cases, juggling between characters from multiple languages needs to be prepared for and also take care of complex typography.

- Orientation and Skew (Rotation): During data curation, we often scan images to train algorithms for input data collection. If you’ve ever used a scanner or digital camera, then you may have noticed that the angle at which you capture images of documents can sometimes cause them to appear skewed. This is known as skewness which refers to the degree of angle. This skewness can reduce the accuracy of the model. Luckily, various techniques can be used to fix this problem by simply modifying how our software detects features in particular regions of the image. An example of such a technique is Projection Profile methods or Fourier Transformation methods, which allow for much cleaner results in shape, dimension, and texture recognition! Although orientation and skewness might be simple mistakes, these can impact the accuracy of the model in large numbers.

- Data Security: If you are extracting data from various sources for data collection, it is important to be aware of the security measures that are in place. Otherwise, you risk compromising the information that is being transferred. This can lead to situations where personal information is breached or the information that is sent to an API is not secure. Therefore, while working with ETL scripts and online APIs for data extraction, one must also be aware of data security issues.
- Table Extraction: Sometimes, we see form data inside tables; building a robust algorithm that can handle both form extraction and table extraction can be challenging. The usual approach is to build these algorithms independently and apply them to the data, but this will lead to the use of more computation power which increases costs. Therefore, an ideal form extraction should be able to extract both form-data as well as data from a given document.

- Post Processing / Exporting Output: The output data from any data extraction is not straight. Therefore, developers rely on post-processing techniques to filter the results into a more structured format. After processing the data, it is exported into a more structured format such as CSV, Excel, or a database. Organizations rely on third-party integrations or develop APIs to automate this process, which is again time-consuming. Hence, ideal data extraction algorithms should be flexible and easy to communicate with external datasources.

Want to extract data from printed or handwritten forms ? Check out Nanonets™ form data extractor for free & automate the export of information from any form!
Understanding the Depth of the Form Extraction with Various Scenarios
So far, we have discussed the fundamentals and challenges of form data extraction. In this section, we will deep dive into different scenarios and understand the depth of form data extraction. We will also look at how we can automate the extraction process for these specific scenarios.
Scenario #1: Hand-Written Recognition for Offline Forms
Offline forms are commonly encountered in daily life. It is imperative for the forms to be easy to fill out and submit. Manually digitalizing offline forms can be a hectic and expensive task, which is why deep learning algorithms are needed. Handwritten documents are a major challenge to extract data from due to the complexity of the handwritten characters. Therefore, data recognition algorithms are heavily used by which a machine learns to read and interpret the handwritten text. The process involves scanning images of handwritten words and converting them into data that can be processed and analyzed by an algorithm. The algorithm then creates a character map based on strokes and recognizes corresponding letters in order to extract the text.

Scenario #2: Checkbox Identification on Forms
Checkbox forms is a form of data input used to gather information from a user in an input field. This type of data is usually found in lists and tables requiring the user to select one or more items, such as items they want to be contacted. It can be found in any number of places- online forms, questionnaires and surveys, and so on. Today, some algorithms can automate the data extraction process even from the checkboxes. The primary goal of this algorithm is to identify the input regions using computer vision techniques. These involve identifying lines (horizontal and vertical), applying filters, contours and detecting edges on the images. After the input region is identified, it’s easy to extract the checkbox contents that are either marked or unmarked.

Scenario #3: Layout Changes of the form from time to time
When it comes to filling out forms, there are typically two different types of options. For some forms, we need to provide our information by writing in all the relevant fields, while for others, we can provide the information by selecting from a few checkboxes. The layout of the form also changes depending on the type of form and its context. Therefore, it’s essential to build an algorithm that can handle multiple unstructured documents and intelligently extract content depending on the form labels. One popular technique of deep learning architecture to handle document layouts is Graph CNNs. The idea behind Graph Convolutional Networks (GCNs) is to ensure that the neuron activations are data-driven. They are designed to function on graphs, which are composed of nodes and edges. A graph convolutional layer is capable of recognizing patterns in the absence of a task-specific training signal. Therefore, these are suitable when the data is robust.
Scenario #4: Table Cell Detection
In some cases, businesses come across special kinds of forms consisting of table cells. Table cells are rectangular areas inside a table where data is stored. They can be classified as headers, rows, or columns. An ideal algorithm should identify all of these types of cells and their boundaries to extract the data from them. Some popular techniques for table extraction include Stream and Lattice; these are algorithms that can help detect lines, shapes, polygons by using simple isomorphic operations on images.
Form data extraction has its origins in the pre-computer days when people handled paper forms. With the advent of computing, it became possible to store data electronically. The computer programs could use the data to create reports, such as sales statistics. This software could also be used to print mailing labels, such as the name and address of customers, and print out invoices, such as the amount due and the address to which it should be sent. However, today we see a different version of the form data extraction software; these are highly accurate, faster, and deliver the data in a highly organized and structured manner. Now, let’s briefly discuss different types of form data extraction techniques.
- Rule-based From Data Extraction: Rule-based extraction is a technique that automatically extracts data from a particular template form. It can extract data without any human intervention. They work by examining different fields on the page and deciding which ones to extract based on surrounding text, labels, and other contextual clues. These algorithms are usually developed and automated using ETL scripts or web scraping. However, when they are tested on unseen data, they fail entirely.
- Form Data Extraction using OCR: OCR is a go-to solution for any form of data extraction problem. However, one must write additional scripts and programs to achieve accurate performance. For OCR to work, it requires an input of an image with text on it. The software then reads each pixel and compares each pixel to its corresponding letter. If it matches, it will output that letter and any numbers or symbols close enough to the letter. The biggest challenge with OCR is figuring out how to separate letters. For example, when the notes are close together or overlap, such as “a” and “e.” Therefore, these may not work when we are extracting offline forms.
- NER for Form Data Extraction: Named entity recognition is the task of identifying and classifying predefined entities in natural language text. It is often used to extract information from forms, where people type in names, addresses, comments, etc. The task of recognising named entities is closely related to the broader task of coreference resolution, which determines whether mentions of the same entities refer to the same real-world entities. Today with advanced programming tools and frameworks, we could leverage pre-trained models to build NER based models for information extraction tasks.

- Using Deep Learning for Form Data Extraction: Deep learning is not new, it has been around for decades, but recent developments in deep learning architectures and computing power have led to breakthrough results. Form data extraction using deep learning achieved state-of-the-art performance in almost any format, be it digital or handwritten. The process begins by feeding the deep neural network (DNN) thousands or millions of different examples labelled with what they are. For example, image-form labels with its entities like name, email, id, etc. The DNN processes all this information and learns on its own how these pieces are connected. However, building a highly accurate model requires lots of expertise and experimentation.
Want to extract data from printed or handwritten forms ? Check out Nanonets™ form data extractor for free & automate the export of information from any form!
There are many different libraries available for extracting data from forms. But what if you want to extract data from an image of a form? This is where Tesseract OCR (Optical Character Recognition) comes in. Tesseract is an open-source OCR (Optical Character Recognition) engine developed by HP. Using Tesseract OCR, it is possible to convert scanned documents such as paper invoices, receipts, and checks into searchable, editable digital files. It is available in several languages and can recognize characters in various image formats. Tesseract is typically used in combination with other libraries to process images to extract text.
To test this out, make sure you install Tesseract on your local machine. You can either use Tesseract CLI or Python bindings for running the OCR. Python-tesseract is a wrapper for Google’s Tesseract-OCR Engine. It can be used to read all image types supported by the Pillow and Leptonica imaging libraries, including jpeg, png, gif, bmp, tiff, and others. You can use it easily as a stand-alone invocation script to tesseract if needed.
Now, let’s take a receipt containing form data and try to identify the location of the text using Computer Vision and Tesseract.
import pytesseract
from pytesseract import Output
import cv2
img = cv2.imread('receipt.jpg')
d = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(d['level'])
for i in range(n_boxes):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imshow(img,'img')
Here, in the output, as we can see, the program was able to identify all the text inside the form. Now, let’s apply OCR to this to extract all the information. We can simply do this by using the image_to_string function in Python.
extracted_text = pytesseract.image_to_string(img, lang = 'deu')
Output:
Berghotel
Grosse Scheidegg
3818 Grindelwald
Familie R.Müller
Rech.Nr. 4572 30.07.2007/13:29: 17
Bar Tisch 7/01
2xLatte Macchiato &ä 4.50 CHF 9,00
1xGloki a 5.00 CH 5.00
1xSchweinschnitzel ä 22.00 CHF 22.00
IxChässpätz 1 a 18.50 CHF 18.50
Total: CHF 54.50
Incl. 7.6% MwSt 54.50 CHF: 3.85
Entspricht in Euro 36.33 EUR
Es bediente Sie: Ursula
MwSt Nr. : 430 234
Tel.: 033 853 67 16
Fax.: 033 853 67 19
E-mail: grossescheidegs@b luewin. Ch
Here we’re able to extract all the information from the form. However, in most cases, using just OCR will not help as the data extracted will be completely unstructured. Therefore, users rely on key-value pair extraction on forms, which can only identify specific entities such as ID, Dates, Tax Amount, etc. This is only possible with deep learning. In the next section, let’s look at how we can leverage different deep learning techniques to build information extractions algorithms.
Graph Convolution for Multimodal Information Extraction from Visually Rich Documents
Graph Convolutional Networks (Graph CNNs) are a class of deep convolutional neural networks (CNNs) capable of effectively learning highly non-linear features in graph data structures while preserving node and edge structure. They can take graph data structures as input and generate ‘feature maps’ for nodes and edges. The resulting features can be used for graph classification, clustering, or community detection. GCNs provide a powerful solution to extracting information from large, visually rich documents like invoices and receipts. To process these, each image must be transformed into a graph comprised of nodes and edges. Any word on the image is represented by its own node; visualization of the rest of the data is encoded in the node’s feature vector.

This model first encodes each text segment in the document into graph embedding. Doing so captures the visual and textual context surrounding each text element, along with its position or location within a block of text. It then combines these graphs with text embeddings to create an overall representation of the document’s structure and what is written within it. The model learns to assign higher weights on texts that are likely to be entities based on their locations relative to one another and the context in which they appear within a larger block of readers. Finally, it applies a standard BiLSTM-CRF model for entity extraction. The results show that this algorithm outperforms the baseline model (BiLSTM-CRF) on a wide margin.
LayoutLM: Pre-training of Text and Layout for Document Image Understanding
The architecture of the LayoutLM model is heavily inspired by BERT and incorporates image embeddings from a Faster R-CNN. LayoutLM input embeddings are generated as a combination of text and position embeddings, then combined with the image embeddings generated by the Faster R-CNN model. Masked Visual-Language Models and Multi-Label Document Classification are primarily used as pretraining tasks for LayoutLM. The LayoutLM model is valuable, dynamic, and strong enough for any job requiring layout understanding, such as form/receipt extraction, document image classification, or even visual question answering can be performed with this training model.
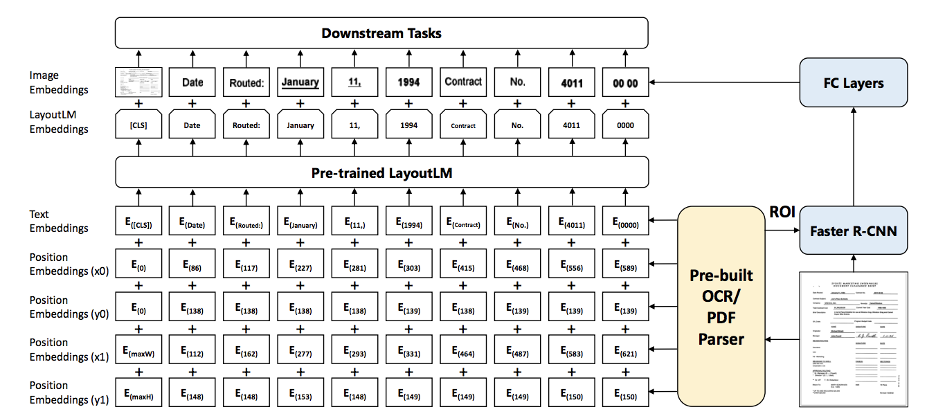
The LayoutLM model was trained on the IIT-CDIP Test Collection 1.0, which includes over 6 million documents and more than 11million scanned document images totalling over 12GB of data. This model had substantially outperformed several SOTA pre-trained models in form understanding, receipt understanding, and scanned document image classification tasks.
Form2Seq: A Framework for Higher-Order Form Structure Extraction
Form2Seq is a framework that focuses on extracting structures from input text using positional sequences. Unlike traditional seq2seq frameworks, Form2Seq leverages relative spatial positions of the structures, rather than their order.
In this method, first, we classify low-level elements that will allow for better processing and organization. There are 10 types of forms, such as field captions, list items, and so on. Next, we group lower-level elements, such as Text Fields and ChoiceFields, into higher-order constructs called ChoiceGroups. These are used as information collection mechanisms to achieve better user experience lower-level elements into higher-order constructs, such as Text Fields, ChoiceFields and ChoiceGroups, used as information collection mechanisms in forms. This is possible by arranging the constituent elements in a linear order in natural reading order and feeding their spatial and textual representations to the Seq2Seq framework. The Seq2Seq framework sequentially makes predictions for each element of a sentence depending on the context. This allows it to process more information and arrive at a better understanding of the task at hand.
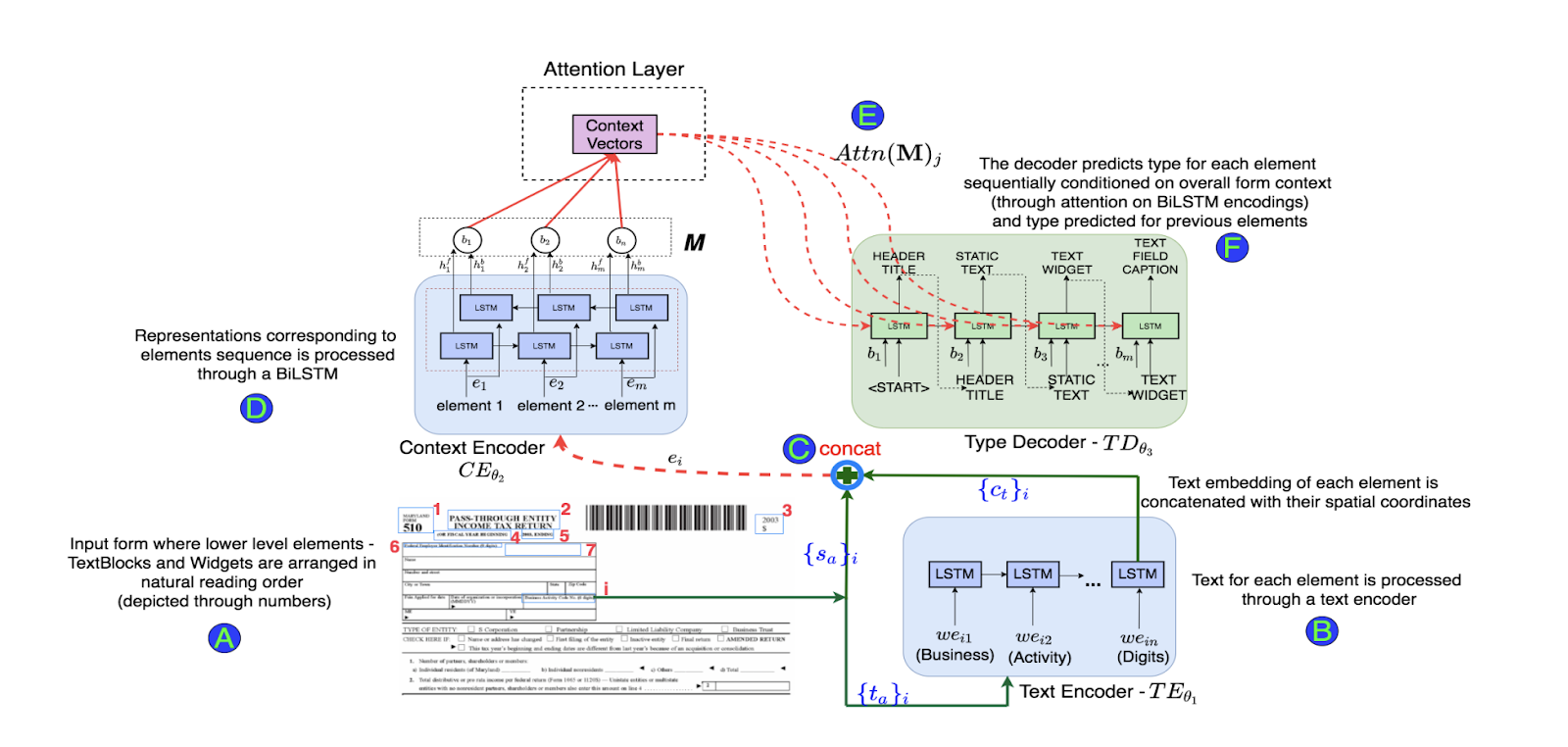
The model achieved an accuracy of 90% on the classification task, which was higher than that of segmentation based baseline models. The F1 on text blocks, text fields and choice fields were 86.01%, 61.63% respectively. This framework achieved the state of the results on the ICDAR dataset for table structure recognition.
Want to extract data from printed or handwritten forms ? Check out Nanonets™ form data extractor for free & automate the export of information from any form!
Why Nanonets AI-Based OCR is the Best Option
Though OCR software can convert scanned images of text to formatted digital files such as PDFs, DOCs, and PPTs, it is not always accurate. Today’s leading-edge software like Nanonets AI-based OCR deep learning system has overcome many challenges that traditional OCR systems have faced while creating an editable file from a scanned document. It has become the best option for data extraction because it can provide high accuracy rates and high tolerance levels for noise, graphical elements, and formatting changes. Now, let’s discuss a few points on how AI-based OCR is the best option.

- OCR, as discussed, is a straightforward technique to extract data. However, they won’t work consistently when put on unseen/new data. However, AI-based OCR could handle situations like these, as they train on a wide range of data.
- Normal OCRs cannot handle complex layouts for form data extractions. Therefore, when powered with deep learning or AI, they give the best results by understanding the data’s layouts, text, and context.
- OCRs might underperform when there is noise in data, such as skewness, low-light scanned images etc., while deep learning models can handle such conditions and still return highly accurate results.
- AI-based OCRs are highly customizable and flexible compared to traditional OCRs; they can be built on various kinds of data to convert unstructured data into any structured format.
- Post-processing outputs from AI-based OCR are accessible compared to plain OCR; they can be exported into any data formats such as JSON, CSV, Excel Sheets, or even a database such as Postgres directly from the model.
- AI-Based OCR can be exported as a simple API using pre-trained models. This is still possible in other traditional methods, but it might be hard to improve the models consistently on a timely basis. While on AI-based OCR, it can automatically be tuned by errors.
- Table extraction is highly impossible using straight OCR. However, it can be done with ease with the power of AI/DL. Today, AI-based OCRs can positively point table-based forms inside documents and extract information.
- If there is any financial or confidential data in documents, AI models can also perform fraud checks. It basically looks for edited/blurred text from the scanned documents and notifies the administrators. Duplicate documents or information can also be identified through these models. While OCR simply fails in such cases.
[ad_2]
Source link