
[ad_1]
Want to make contents in your PDF documents searchable? With Nanonets, all the documents you upload and process are made searchable and you can search for any information in any of your documents in your database.
PDF documents are considered to be one of the most important and widely used file types. We can see them in most daily activities and transactions. They are also used in various business and industrial processes. However, when we look for the required information from PDF documents, we often face some problems. For example, when we need to find a specific piece of data from a PDF document, we must open each PDF file page and scan it manually. This is not only time-consuming, but it is also a very ineffective way of finding any information we need. This is why we need to make PDF documents searchable. Well, in this blog post, we are here to show you that you can easily and quickly make a PDF document searchable and that you can get your document to be searched just like a regular Word document; using various techniques involving OCR and Deep Learning.
What is a Searchable PDF?
A searchable PDF is a PDF document that can be searched for terms or phrases. This means that users can jump right to the document section where the term or phrase is located. It is a great feature to have if you have a long document that you are providing for download. Users often want to access the information they are looking for as quickly as possible. A searchable PDF can help them do that. This is especially useful for contracts, scanned forms, receipts, and other documents.

For example, say we have many invoices from clients. If we want to find a particular invoice number, we must go through each invoice and search manually. Most of the images are in scanned formats, and the text may not be in the editable format. Nevertheless, suppose we turn our PDF invoices into searchable PDFs. In that case, we can instantly find the invoice without going through each document or line item. Therefore, people rely on different tools and programming frameworks to extract information and then create a search function over PDF using OCR and other programming frameworks. Note that these techniques are applied based on the type of PDFs we are using; therefore before diving into these algorithms and methods, let us discuss the types of PDFs we regularly encounter.
#1 Text-based: Text-based PDF documents are PDF documents that contain text only; no images, no special fonts or graphics, just plain text that can be read by anyone with a computer and a PDF reader. It is easy to convert text-based PDFs into searchable PDFs by using OCR or software such as Abode Acrobat. However, we might have some complications when there are elements like tables, charts, etc.
# 2 Image-based PDF: Image-based PDF documents are created by importing images into a PDF document. This is typically done by scanning a paper document and importing the scanned image into a PDF document. Documents created with images can be rather large and can be challenging to search. Image-based PDFs cannot be indexed by search engines such as Google. However, there are ways to make image-based PDFs searchable using optical character recognition (OCR) technology.
In the next section, let us look at different ways we can make PDFs searchable
Want to make contents in your PDF documents searchable? With Nanonets, all the documents you upload and process are made searchable and you can search for any information in any of your documents in your database.
How to Make PDFs Searchable?
We can leverage different tools and software to convert any PDF into a searchable PDF, but as discussed, one must be clear on the type of PDF they are working with before applying any technique.

Now, let us look at how we can leverage Adobe Acrobat to generate a searchable PDF.
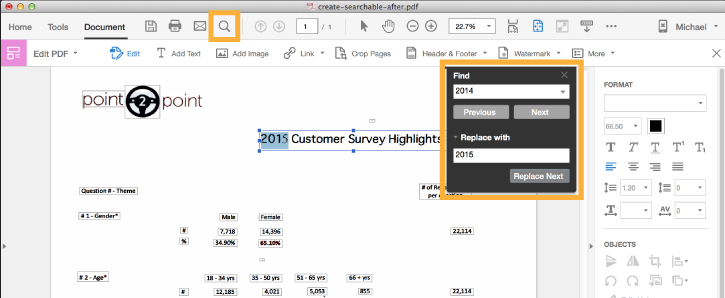
1. First of all, open Acrobat.
2. From the menu bar, select File -> Enhance -> Edit with OCR.
3. Then, choose the correct technique and language from the boxes. After selecting the correct method and terminology, click on the Enhance button. Wait for a while for OCR to detect the text in the PDF file.
4. After OCR has finished, click on the Protect button, and then you can save your document as a PDF.
5. Open the PDF file; you can see that OCR text has been automatically highlighted on the pages.
6. All you have to do now is run a standard PDF file search and find the text highlighted on each page of the PDF document. This task is much easier, and it will take you less than 10 minutes.
However, there are some drawbacks to using Adobe Acrobat. The main disadvantage of using this tool is that it will cost you a fortune if you have many documents to be made searchable. You have to buy a license for each computer where you want to install this program. And it is not just the cost of the program that you need to worry about. The headache of having to update each copy of the program as and when Adobe releases an update is something that you should also worry about. This is where OCR and Machine Learning come into the picture.
If you have a PDF document you want to convert into a searchable and editable document, the best way to do it is by using Deep Learning based OCR. OCR or Optical Character Recognition is a technology that can take images and convert them into searchable and editable text. Deep Learning based OCR is the next generation of OCR, which is more accurate than traditional OCR. With Deep Learning, you do not need to add unique fonts to your PDF document to make it searchable. Deep Learning is a type of machine learning that uses many layers of non-linear processing units for feature extraction and transformation. Now let us discuss these techniques in more detail.
Want to make contents in your PDF documents searchable? With Nanonets, all the documents you upload and process are made searchable and you can search for any information in any of your documents in your database.
Extracting Data from PDFs Using OCR and Making them Searchable
As discussed, PDFs are created using a combination of text, images, and other multimedia elements. This is what makes it difficult to search for a specific piece of text in a PDF document. However, Optical Character Recognition (OCR) can help us convert text images into searchable text. The process involves scanning the document, identifying the font, language, etc., converting it into text, and cleaning up the text. It is done using what is called an OCR Engine. There are different OCR engines available. Some are free, and some are paid. Some are cloud-based, some are installed on your computer. Many of them are also capable of converting the text into editable text, making it very convenient.
As an example, let us use Tesseract OCR to understand the process of generating searchable PDFs from image-based PDFs. If you are hearing Tesseract for the first time, it is an optical character recognition (OCR) engine by Google. It supports more than 100 languages. The most important thing for Tesseract is training data – Tesseract comes with a set of training data that allows it to recognize the characters. Training data is available for many languages, but sometimes it is not sufficient. We can extend the Tesseract training data using its command-line tool. It is worth mentioning that the Tesseract OCR tool is free and open source. We can download the tool and modify it to add new languages to the training data.
To install Tesseract on Windows, we can use the precompiled binaries that can be found here. Do not forget to edit the “path” environment variable and add a tesseract path. For Linux or Mac-based installation, it is installed with a few commands.
We can use the Tesseract engine on the image with image_path and convert the image to text, written line by line in the command prompt by typing the following.
$ tesseract image_path stdout
To write the output text in a file
$ tesseract image_path text_result.txt
To specify the language model name, write language shortcut after -l flag, by default, it takes the English language:
$ tesseract image_path text_result.txt -l eng
This is how we can extract all the information from PDF into editable format and generate an utterly searchable PDF. However, there can be many complications here. Sometimes, the OCR might not perform well due to the ambiguity of the data we are using. For example, the text might be placed across different images, which might misplace the extracted text; similarly, OCR might not perform well when there is any handwritten text. This is where Deep Learning algorithms come into the picture.
Deep Learning for Making PDFs Searchable
To make PDFs searchable using deep learning techniques, one must first understand different ways of information extraction. Today, deep learning, neural networks in specific have achieved a state of the art performance in extracting any kind of text-based data. These algorithms are trained on a wide range of datasets over different parameters. Now, let’s look at different techniques on how we can extract data from PDFs and make them searchable.

Primarily we leverage neural networks to solve data & information extraction from PDF documents. The process begins with an application that converts the PDF into a series of images. The images are then split into individual pages. Each page is assigned a category based on the contents in the page. The categories are used to train the neural network to extract relevant information from the document. The network is trained for accuracy through a process called backpropagation. The backpropagation algorithm is used to calculate the error rate of the network. The error rate determines how many times the network should adjust its weights to extract the best information.
This error rate is again optimised by setting and updating the hyper-parameters of the network. However, today we need not do everything from scratch, we can utilise pre-trained models such as RESNET, BERT which are already trained on a wide range of data and build a simple neural network on top of it. After the model is trained and evaluated we then create a new electronic PDF or can save them in specific formats as required by the user. Following are some of the state-of-the-art research work that can be used for data extraction from PDF to create searchable PDFs.
- CUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor
- Named Entity Recognition on CoNLL 2003 (English)
- Key Information Extraction From Documents: Evaluation And Generator
- Deep Reader: Information extraction from Document images via relation extraction and Natural Language
In the next section, let’s take a look at how Nanonets, one of the best OCR tools in the market can make PDFs searchable using state of the art OCR and deep learning technologies.
Want to make contents in your PDF documents searchable? With Nanonets, all the documents you upload and process are made searchable and you can search for any information in any of your documents in your database.
Enter Nanonets – Advanced OCR
Nanonets™ is one of the prominent players in the market that offers users to build their own OCR conversion engines and models based on the data they provide. With this, any information, say PDF, Images, can be instantly extracted and can be made searchable. This can significantly help enterprises manage their operations more effectively and increase work, revenue efficiency, and productivity without writing a single line of code.
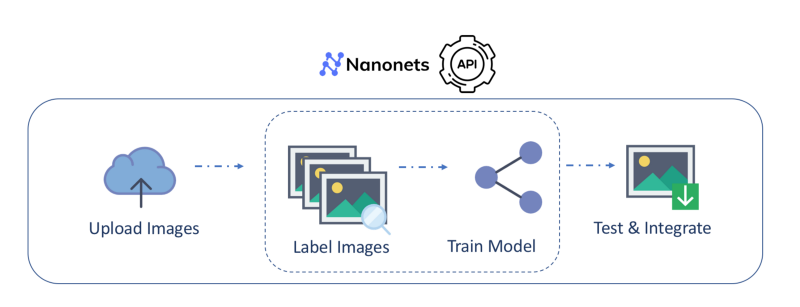
In the next section, we will discuss in detail how we can convert unstructured PDF files into readable and searchable files using the Nanonets.
Search on Nanonets
Nanonets recently announced a set of new search features with the best OCR technology, with this, users can find documents not only by searching for keywords but also by opening a PDF file and searching for a phrase or a word inside the document. This feature will help users to find the right content quickly and easily. There are no limitations here, the search will work on any kind of PDF data or even images. Let’s see this in action!
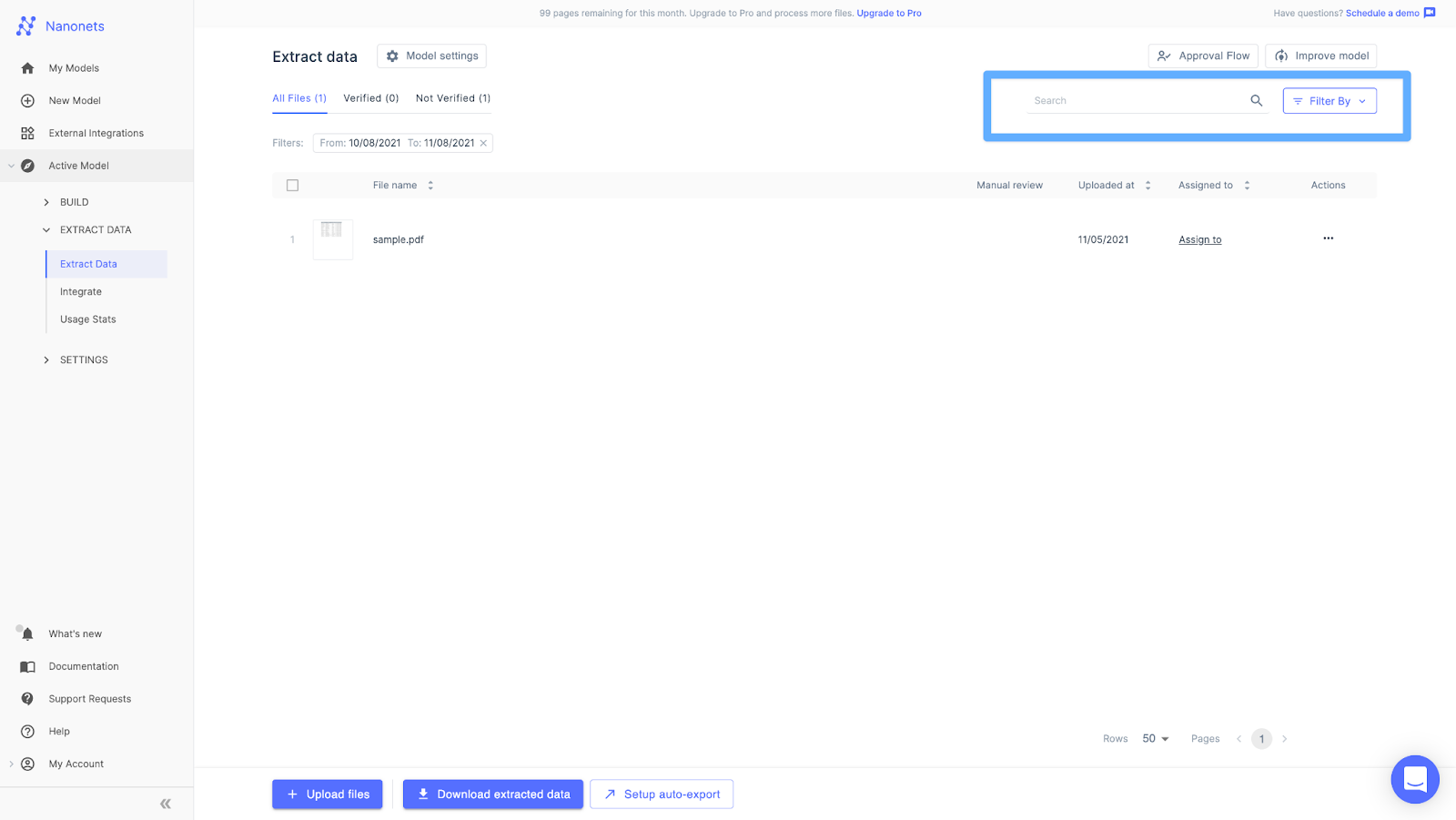
#1 Basic Search on Extracted Data on Nanonets
After annotating the images and training the model, we can directly enter the value we are looking for in the search input. Nanonets platform automatically parses through all the files using its advanced OCR and returns the files that contain the value. For example, say we have an invoice extraction model and search for text in an invoice, say a key. You can leverage the search option on the top right corner and directly enter the text. This will return all the files that contain this text, just like any other Adobe acrobat but with more precision.
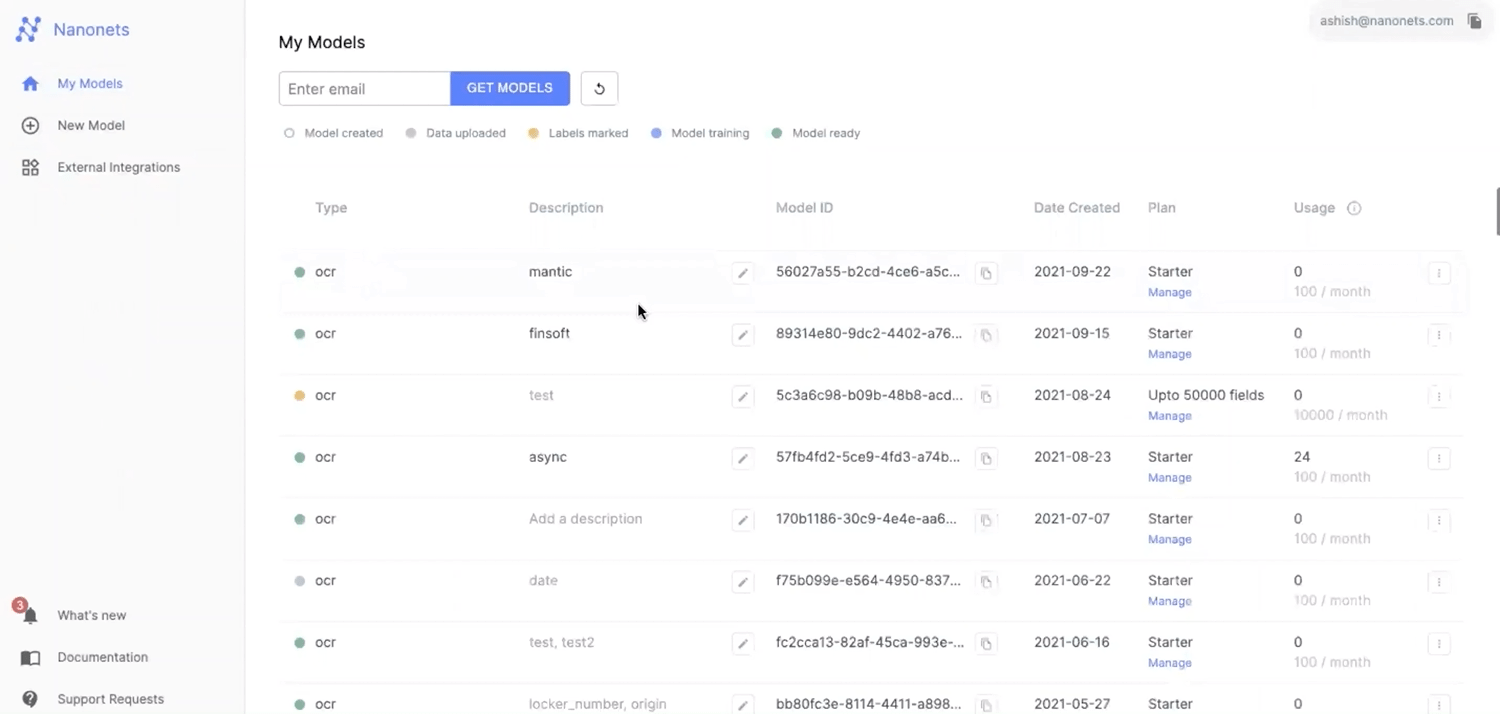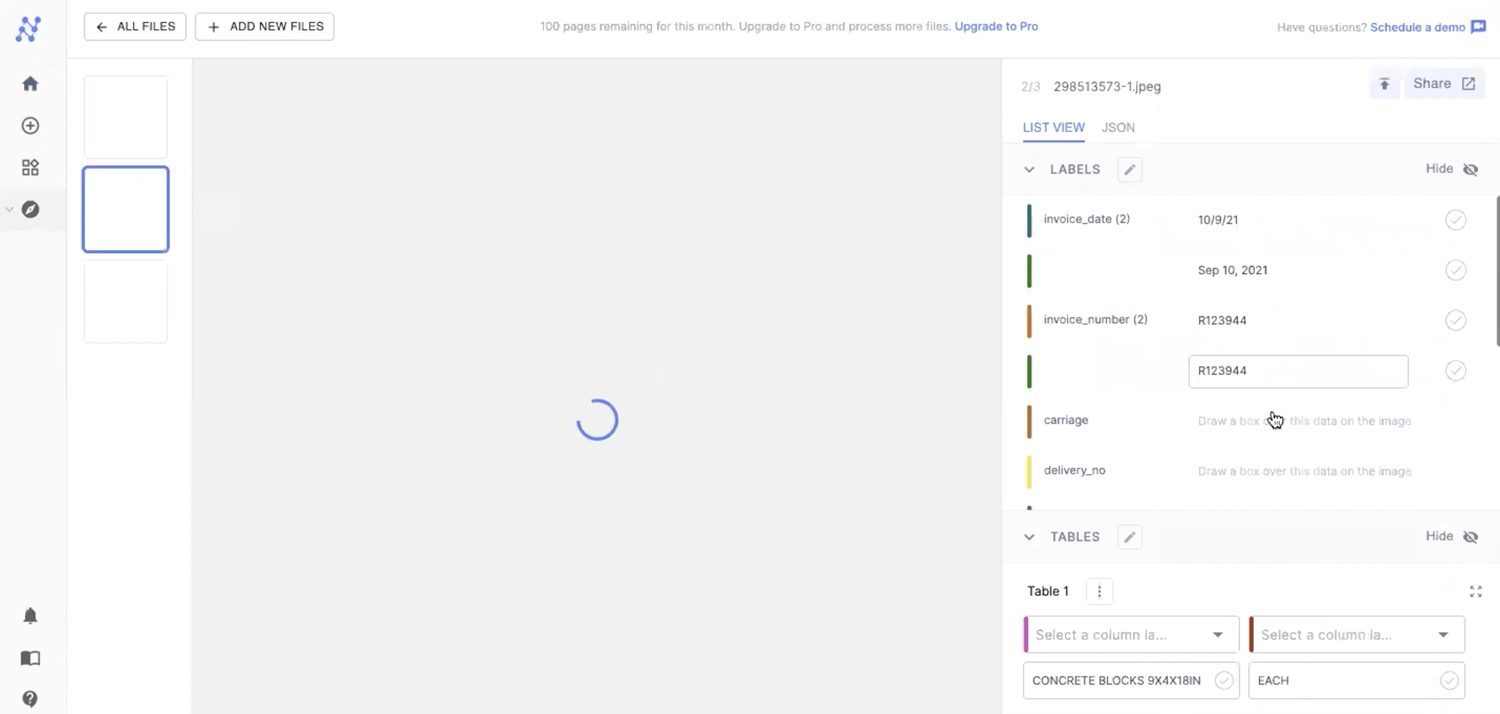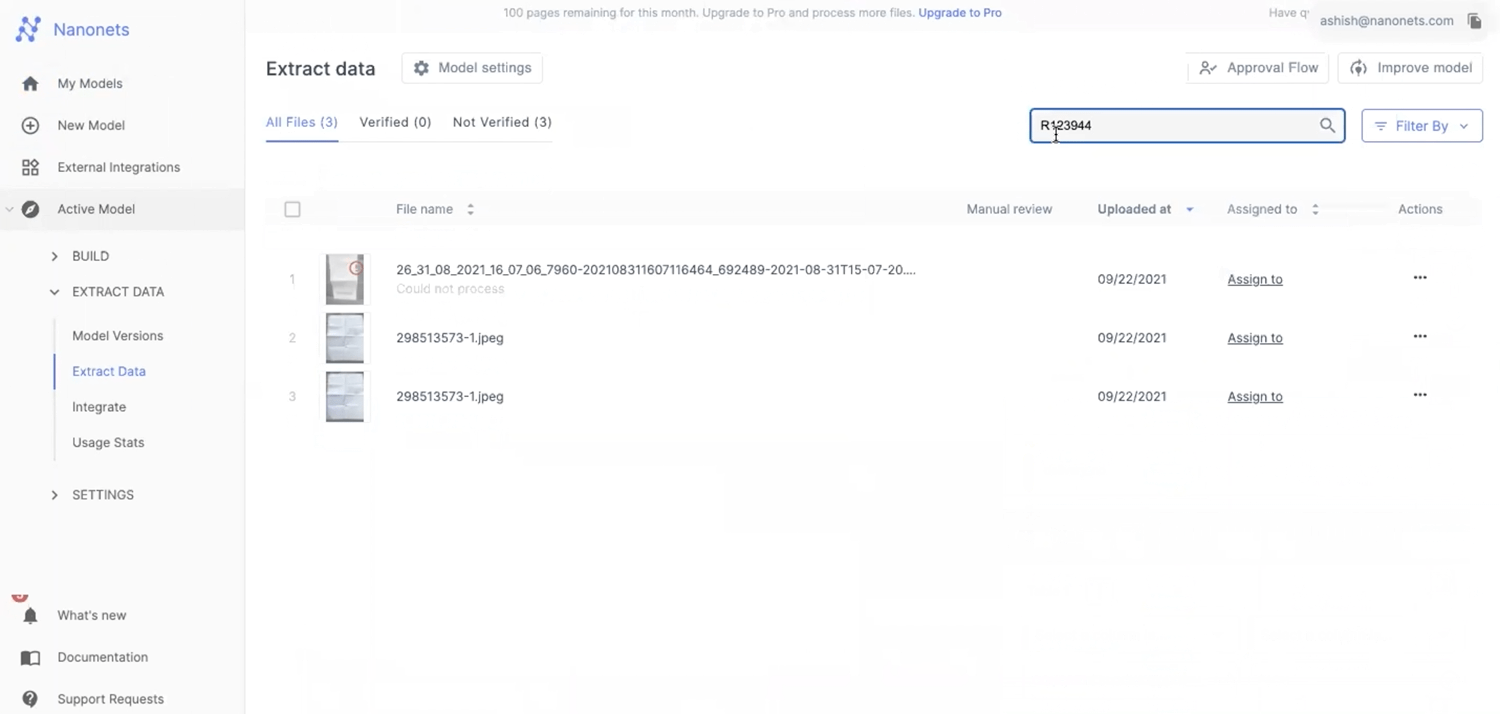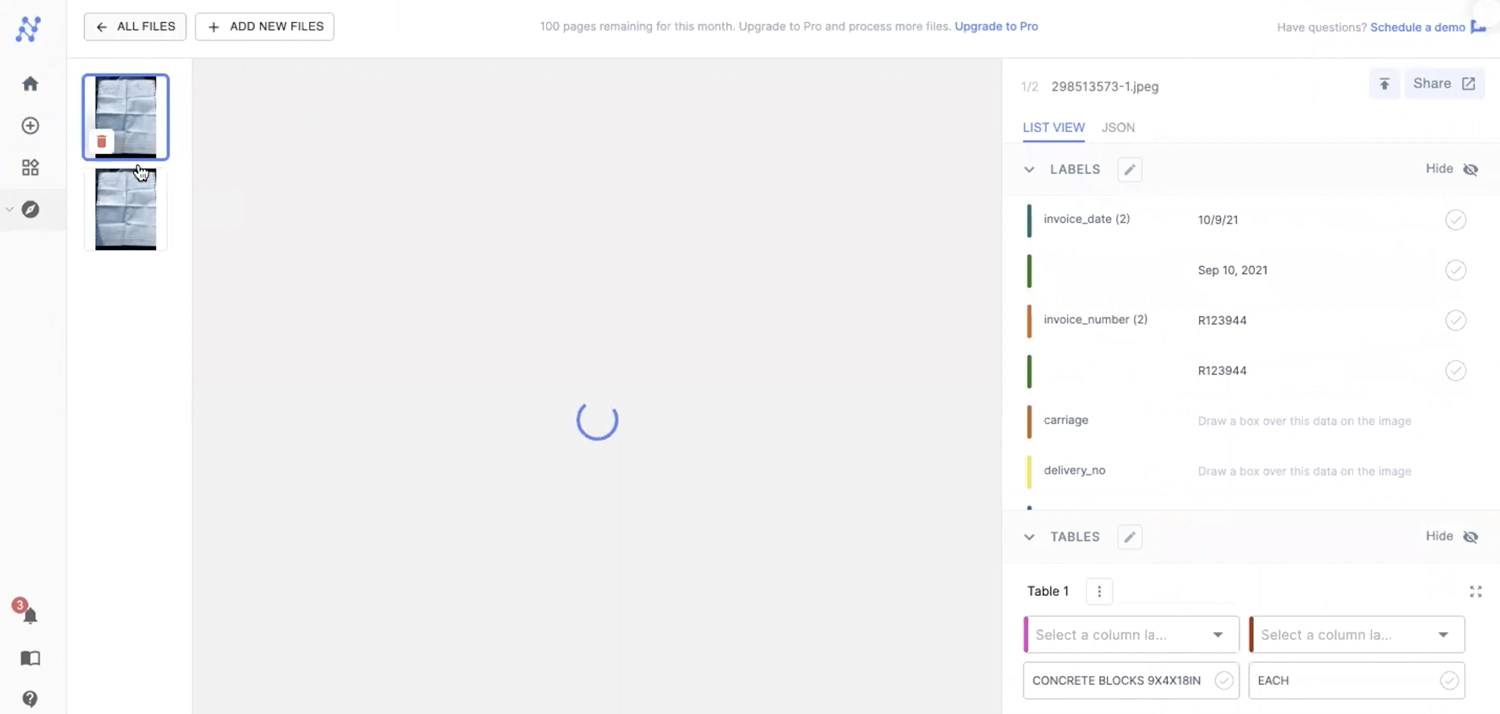
#2 Specifying data types for advanced search
To make the search more accurate, Nanonets lets you assign data types for values inside your information. For example, say you have to filter PDFs based on the invoice date and invoice total. Now, under your model settings, you can set the formatting type to a particular data type for your model, in this case, the date is set to the date-time format and the invoice is set to the integer as seen in the screenshot below.
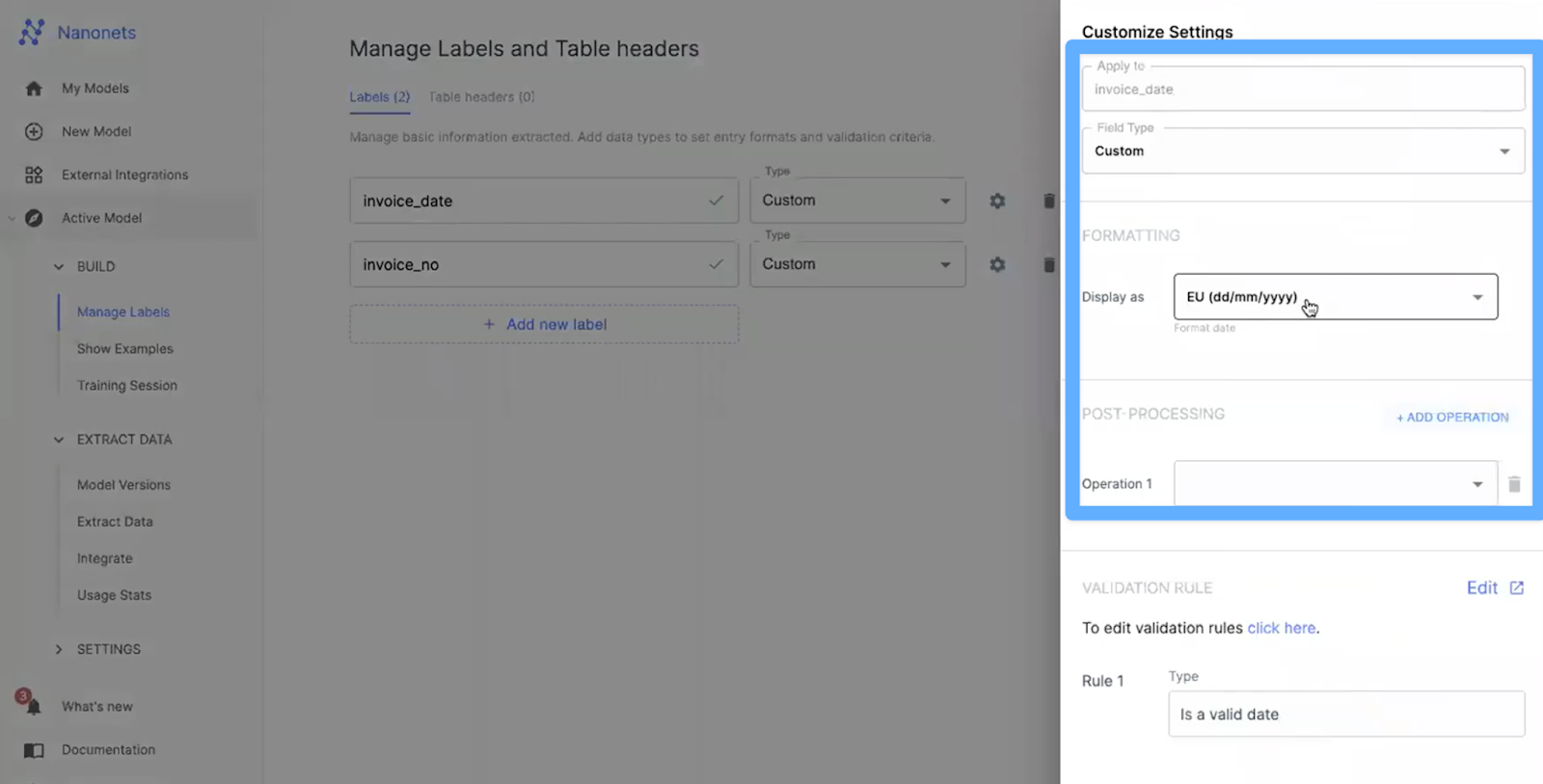
The expected behaviour is to return all PDFs that contain the match date and invoice total. But, Nanonets intelligently identifies the date and invoice based on content and the position of the invoice and returns only the sorted invoices that match the given search input.
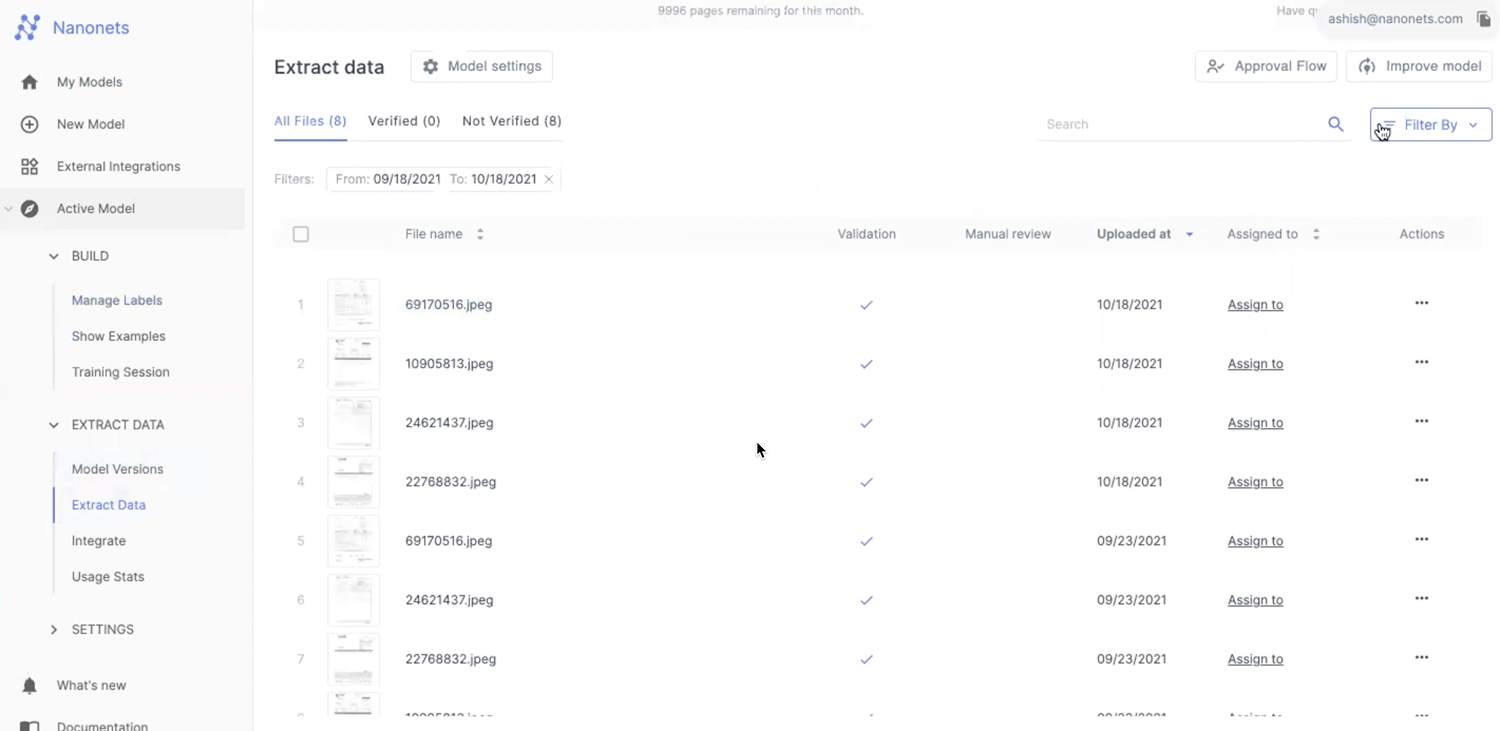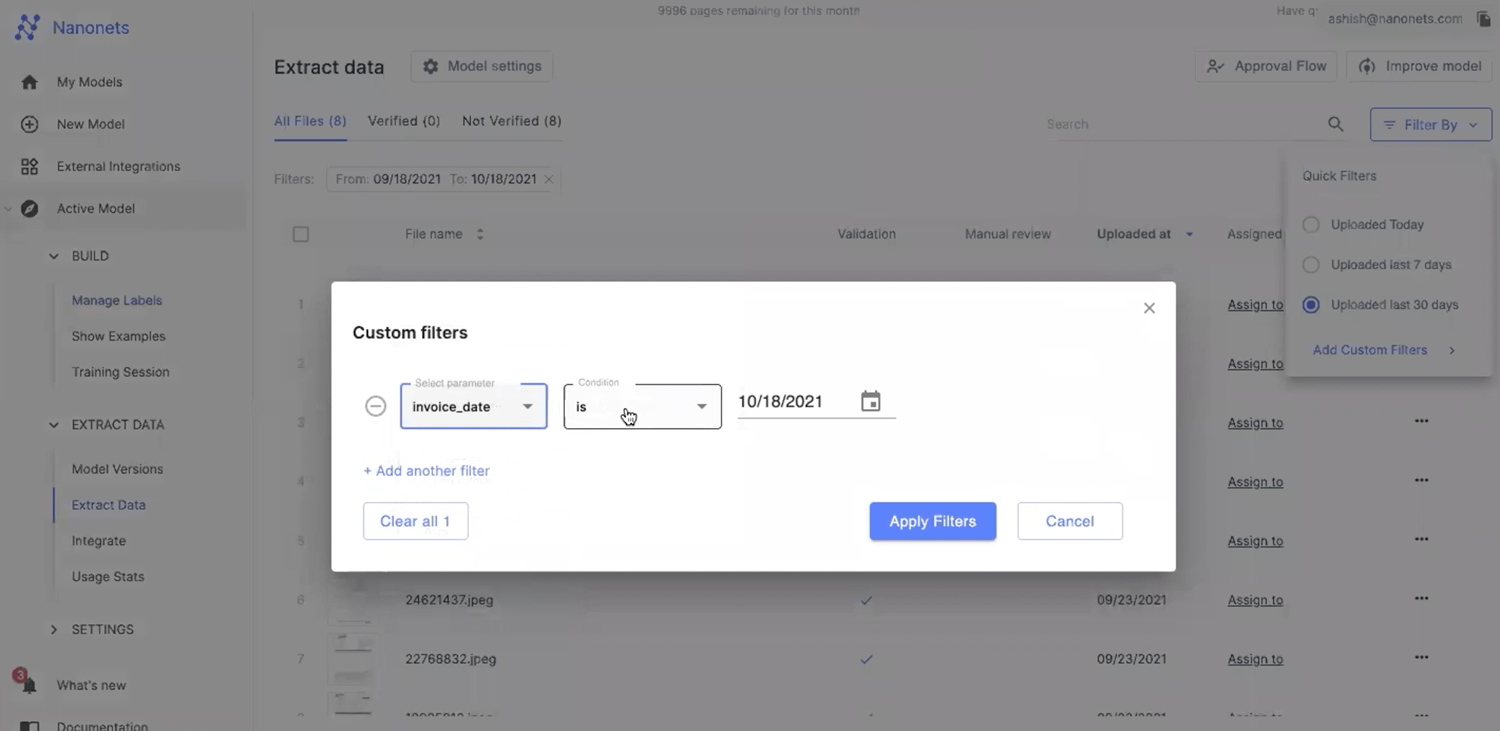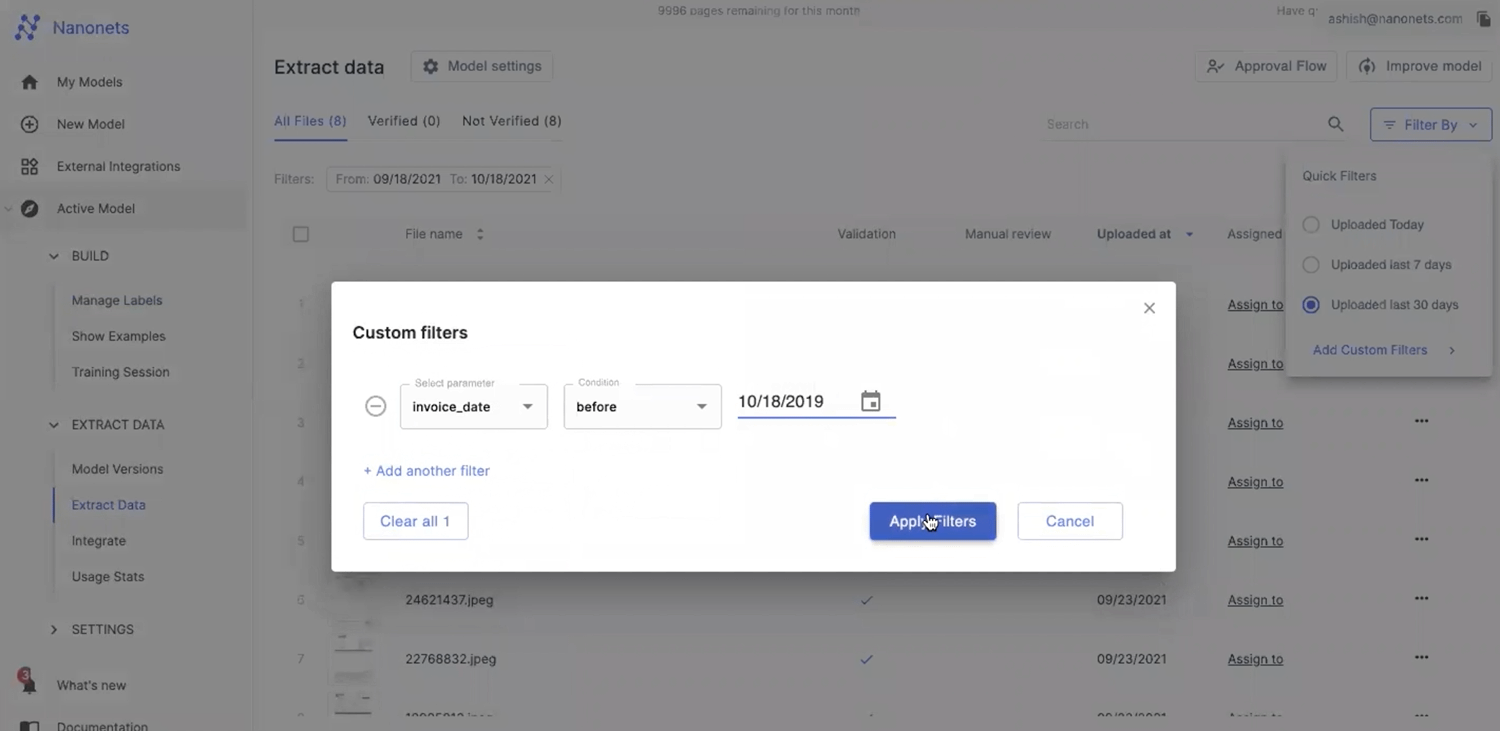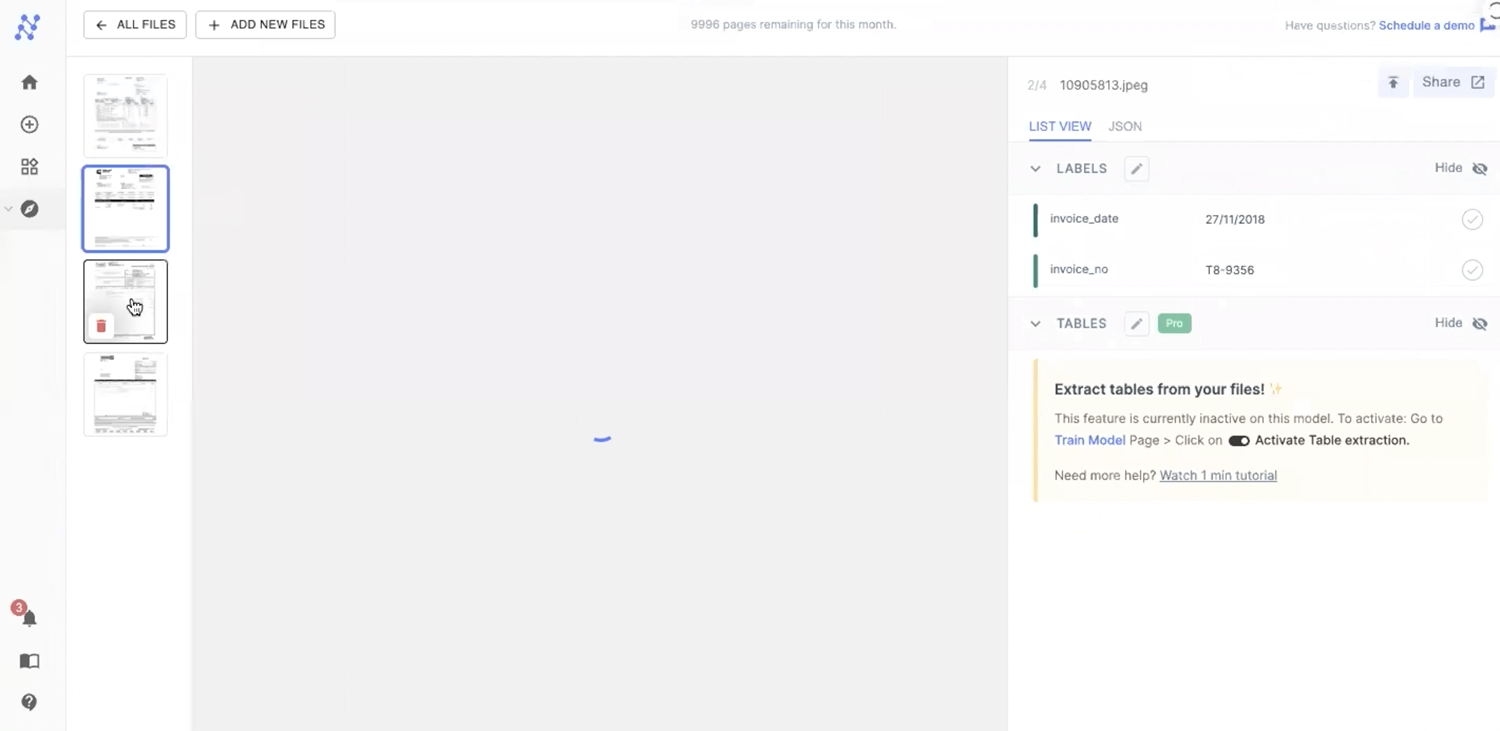
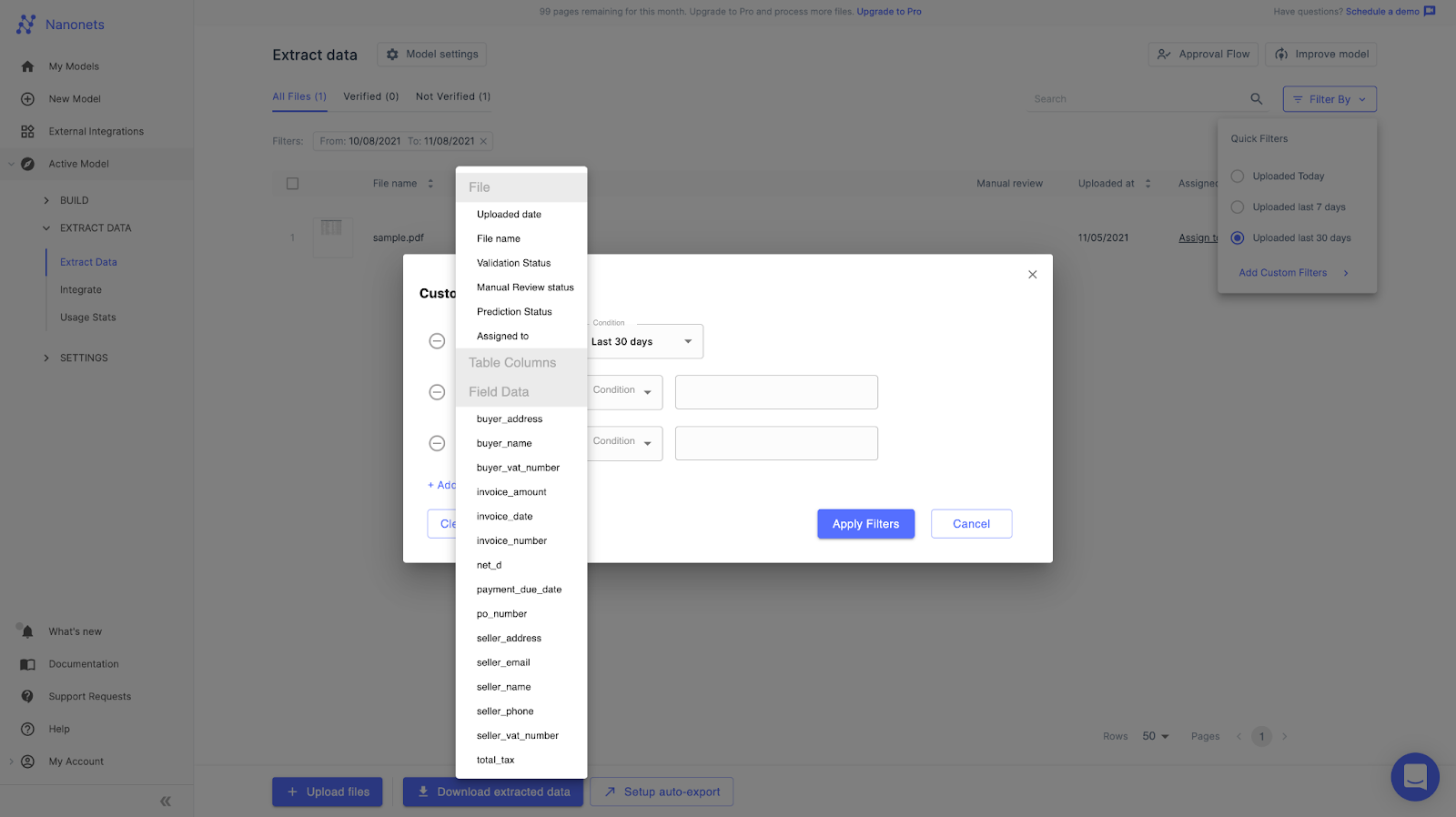
#3 Adding Conditions on Search
If you are working with multiple files, you can add filters on PDF or images on Nanonets for different parameters and conditions without writing any line of code. Say, for example, if you have a group of unsorted invoices and want to sort them based on the total invoice amount — you can use the filter option beneath the search bar. This has two options, which are the `Assigned Value` and `Condition`, the Assigned value` will be mapped to the key, and the `Condition` will be set the Ascending, and just like that, we should see all our invoices sorting in ascending order based on the invoice total.
Conclusion
We hope you enjoyed our article on how to make PDFs searchable. As you can see, making a PDF searchable is not as complicated as you may have thought. You can use deep learning and OCR-based algorithms to develop your own algorithm as discussed or any cloud-based tools. On Nanonets, you can quickly and easily make your PDF documents searchable. So be sure to keep it in mind the next time you have a PDF document that needs to be made searchable :). Thank you for reading our blog today!
[ad_2]
Source link