
[ad_1]
We live in a digital world, where businesses and organizations are rapidly growing with technology. Organisations process vast amounts of data, especially with respect to data or document classification, without even realizing it.
Information is what helps us to make better decisions. Hence, many organisations rely on different ways to collect, classify and store data to perform further analysis. However, it’s highly impossible for human agents to manage such large volumes of data or documents. This is where Automatic Document Classification comes into the picture. It not only helps us in saving information but also helps us find these documents whenever required.
We will dive deep into document classification and discuss different approaches to doing it more efficiently. Further, we’ll also learn about some document classification techniques and talk about real-life scenarios. Following are the table of contents.
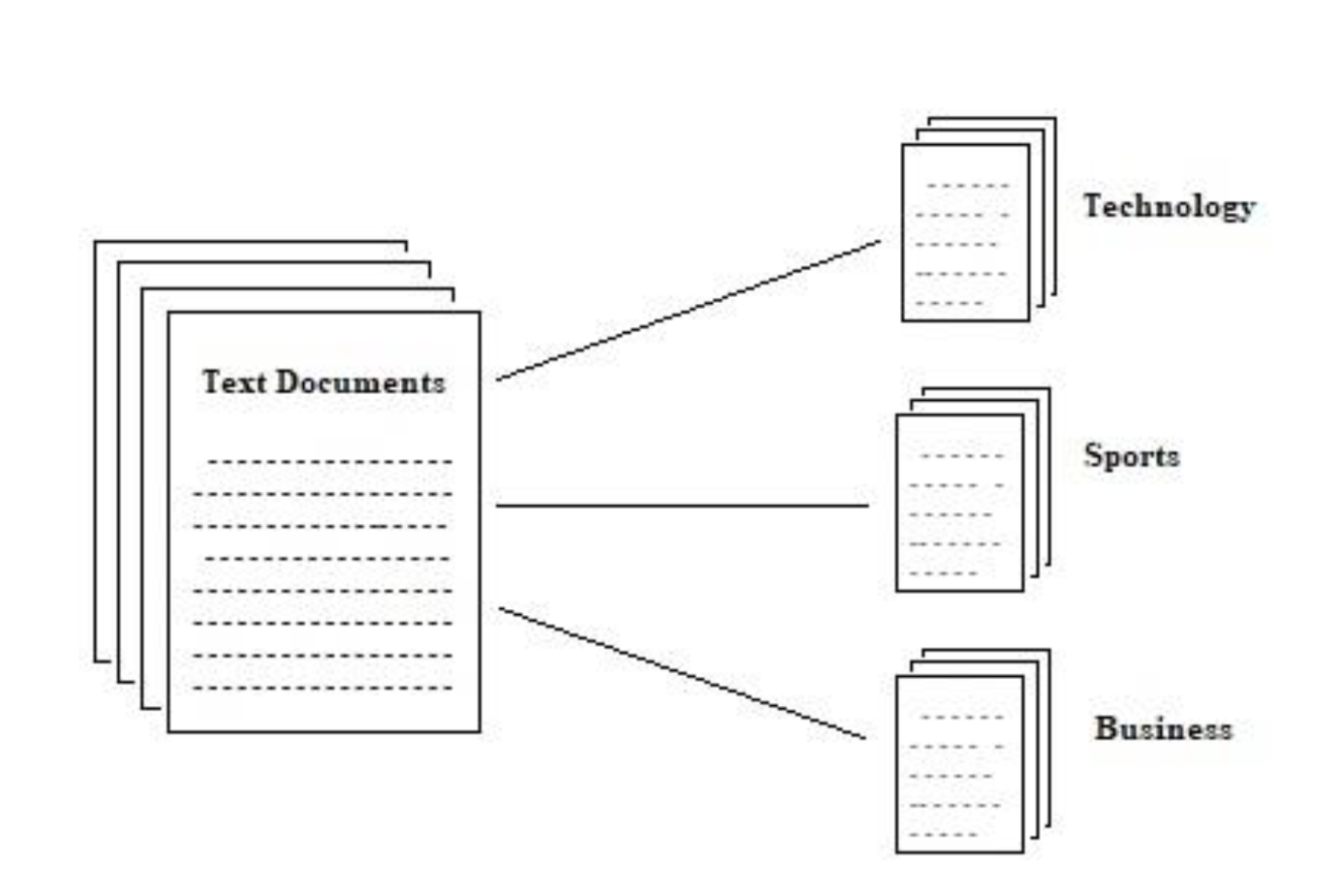
Table of contents
What is Document Classification
Document Classification, as the name suggests, is the process of classifying documents into relevant categories or classes. It is considered as one of the branches of text classification, where the classifier is able to tag a suitable class to the document from a list of predefined classes. This makes the process of organizing and maintaining documents/data easy & efficient.
For example, consider different kinds of invoices like reimbursements, office expenses, invoices for third-party software, etc., that an organization might receive. Usually, these are organized into different folders based on the type of invoice. Now, imagine doing this for an entire firm, organizing some millions of invoices. It’s highly unlikely to achieve one hundred percent accuracy, and manually checking them one by one is time-consuming and tiresome. Hence, for cases like this, an automated algorithm like documents classification could be very handy.
Let’s talk about one more simple example. Let’s suppose you’re an operations manager who has to go through hundreds of emails every day. These might contain sensitive financial documents, office conversations, logistic information, or even something unnecessary (SPAM)! Today, most services like Gmail, Yahoo, etc., do an outstanding job of classifying junk emails as SPAM or NOT SPAM based on the content. This is an extended use of documents classification!
Document classification can be achieved by traditional machine learning algorithms and also with deep neural networks. We’ll learn more about the working of these algorithms in the next section.
How Document Classification Works
Document classification is one of the classic problems in information extraction or retrieval. It plays an essential role in various applications and use-cases for effectively managing text and large amounts of unstructured information. To achieve document classification, we can follow two different methodologies: manual and automatic classification. In manual document classification, as discussed, users manually interpret the meaning of the text and other elements to identify the relationships between concepts and categorize documents. In contrast, automatic document classification applies intelligent techniques such as Machine Learning and Deep Learning to classify documents automatically. This process is much faster, more scalable, accurate, and cost-effective when compared with manual classification.
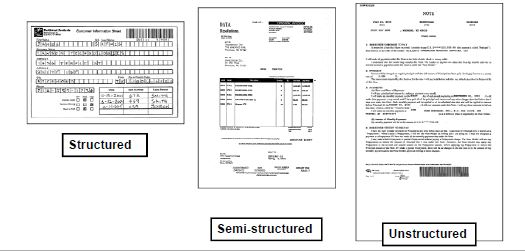
Before we learn about different approaches for automatic document classification, let’s first understand the different kinds of documents:
- Structured Documents: In structured documents or fixed forms, the information is well-formatted. The fonts and numbers are consistent and don’t have many deviations. The layouts or templates are entirely static. It’s easy to build an automated solution over structured documents, as they are well predictable and consistent.
- Unstructured Documents: Such documents contain information presented in an open format, for example, letters, orders, contracts, and bills of lading. In unstructured documents, it’s tough to locate coordinates of any particular information, as they are inconsistent. In some cases, the tables in these documents do not have any borders, making it more difficult for algorithms to locate their exact position. Extensive NLP and NER methodologies are widely used to build intelligent algorithms for such documents.
- Semi Structured Documents: Semi-structured documents are usually a combination of both structured and unstructured documents.
Now that we’ve seen different kinds of documents, let’s learn about the various techniques that can be utilised for achieving document classification!
- Supervised Learning: In this method, the system learns from examples that have both inputs and their corresponding classes or outputs. The algorithm is trained on a manually tagged set of documents. Once the training is complete, the classifier can then predict categories with a confidence indicator; even for previously unseen data/document types.
- Unsupervised Learning: In this approach, similar documents are categorized into different clusters without any prior training. This categorization can be done based on the template, font words or tags, and so on. These algorithms can achieve higher accuracy if specific rules are defined and fine-tuned.
- Rule-based: The rule-based technique is one of the traditional methods for document classification that leverages the natural language understanding capacity of a system and writing grammatical rules that would instruct the system to act like a human while classifying a document. This method has the advantage of regularly enhancing the performance instead of relying solely on statistics or mathematics like the previous two methods. This method is associated with higher accuracy, especially in complicated scenarios. However, building a state of the art model based on rules is time-consuming and difficult to scale.
Why Businesses Use Document Classification
Today, almost every business has to deal with documents to manage their finances, investments, operations, and more. Relying on manual classification for such tasks is hard, time-consuming, error-prone, and highly inefficient. This is where automatic document categorizer comes into play, and it allows corporates, businesses, and organizations from any sector to organize content, making it available at any moment efficiently.
Consider an operations manager who regularly monitors all essential operations and patient-related tasks within a hospital. It includes many documents, such as confirming appointment letters, monitoring doctors’ prescriptions, drug details, payment information, and further appointment details. When dealing with hundreds of patients, it’s easy to simply store these documents in different folders manually. When there are thousands of such folders, operations personnel can’t monitor all this information individually. However, these folders are super essential for them to analyze to make better business decisions. Now consider the same scenario with a documents classification pipeline in place:
Choose templates for different kinds of documents
- Add some metadata to the template like the patient id, invoice id, consulting doctor etc.
- Capture and save all the documents on a database or a machine and collect them on a daily basis
- Pre-process every document based on the model and resize them consistently
- Annotate a few documents initially to train a highly accurate model
- Prepare the annotations and corresponding documents using different data-loaders and transformation functions
- Use an automated document classifier (a machine learning model or deep learning model) to segregate these documents based on their type
- Evaluate the model and fine-tune the parameters based on the performance metrics
- Apply information extraction algorithms to extract crucial information and tables
- Export all the information into the desired format, such as CSV, Excel, Database etc.
- Deploy models into production to put them to use
An Automated Document Classification Process
So far we have seen what document classification is and different techniques that are used in building such algorithms based on different kinds of data. Now, let’s learn a bit more about the machine learning and deep learning workflows that are involved in building these algorithms:
- Collecting Data: ML or Deep Learning algorithms are built and trained on top of massive datasets. To build a highly accurate document classification algorithm, it’s important to gather different kinds of documents with enough examples for each category so that the algorithm can learn how to differentiate between them. However, if the data is inconsistent or unstructured, performing a few pre-processing steps is highly recommended.
- Setting up Hyperparameters: This part is crucial to train any machine learning or deep learning models; we’ll need to define all the critical parameters used for training the model. Primarily, determining the right cost function and optimizer is super essential. However, based on the metrics, we can fine-tune them to make the model much more accurate.
- Training the Model: The next step is to train the model after we load and set hyperparameters. If your model is based on classic machine learning algorithms, we can code the logic based on the algorithm or import the models from popular libraries. If the model is based on neural nets, we might need to define one based on the data, or fine-tune a model on popular architectures like VGG16, RESNET, etc. In case if you’re getting started, you can check out a few open-source python based ML/DL libraries like Tensorflow, PyTorch, Sklearn.
- Evaluating the Model: After the training process is complete, it’s essential to evaluate it on unseen data. For this, in most cases, the dataset will be initially divided into training and testing sets. We’ll be using the training dataset for training, and for evaluation purposes, we’ll use the test dataset; the average split is usually 7:3 for train and test datasets, respectively. A few frequently considered metrics include precision-recall score, confusion matrix, and mean squared error.
Here are the different steps that are involved in developing and training a deep neural network:
Nanonets Document Classifier
In this blog, we’ve learned many things about document classification and talked about a few use-cases on how document classification can help automate manual tasks. Furthermore, we’ve discussed a deep learning-based workflow that can help us build a document classifier entirely from scratch. But what if we tell you that there’s a way where you can train custom document classification models on your data without writing any code?
Nanonets is a no-code AI-based OCR platform that can help automate your manual data entry document processing use cases. Build/train OCR models on your own data and export them as JSON/CSV or any desired formats.
Building a Document Classifier on Nanonets
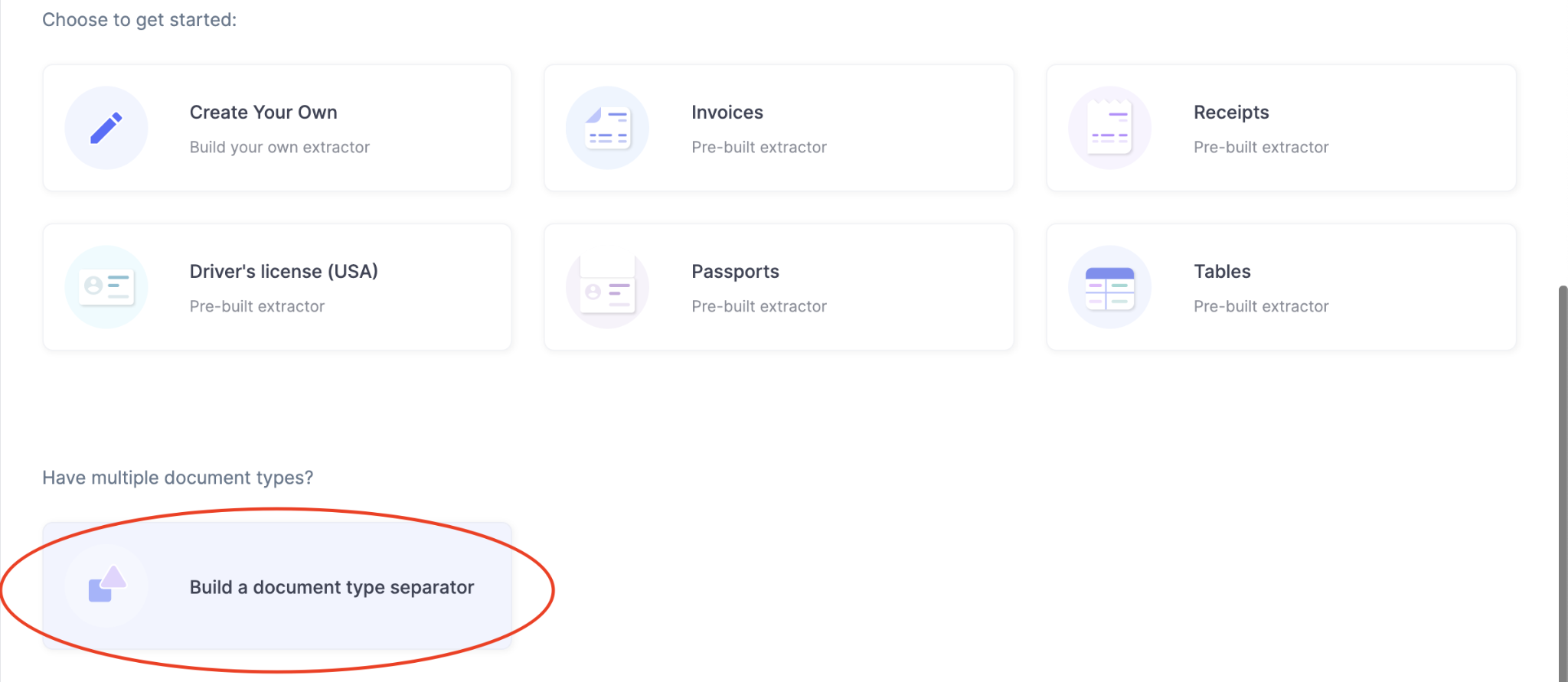
If you’re looking to build a document classifier, you could get started with the Nanonets pre-trained document type separator or document categorizer.
- Signup or sign in to Nanonets.
- Now choose “Build a document type separator” under the dashboard.
- Next, specify the different document types or classes you want to classify. For example, let’s say we are looking to organize three documents: airway bills, invoices, and salary slips. We can set the categories to airway_bills, invoices, salary_slips.
- Next, upload sample documents based on the classes and hit the train button. After the training is complete, the evaluation metrics are displayed. Based on the metrics, either re-train or continue with the existing model.
- You can also upload unseen data and use APIs or webhooks to infer the trained model!
And just like that, without writing any piece of code, we have a high performing document classification model!
Why Use Nanonets
Here are some of the advantages of using Nanonets as a document classifier.
Simple UI: Nanonets provides a simple and easy to use UI to train state of the art machine learning models. All we need to do is to upload the documents, annotate and train them without writing a single line of code inside the platform.
Add Custom Rules and Params: While training models on Nanonets, it provides us with the ease to customise the models. Using this, we can choose particular fields on our documents to extract. For example, if your business documents have 100 fields and you just want to extract around 30 fields, Nanonet can help you do that by just selecting the necessary fields on the model. This applies to all the documents by just configuring a single model.
High Accuracy, Less Processing Time: Nanonets is very well known for its state of the art models as it delivers more than 95% accuracy in identifying text, tables, and key-value pairs anywhere across the documents. All the extracted data can be evaluated on the GUI, in case of any errors, the correct value can be mentioned and the model rectifies itself within no time.
Post Processing Features: Nanonets provides the ability to add post-processing rules even after the model is trained. So we can add additional information to the output without re-training the model.
Integrate Applications: Nanonets can easily integrate with any kind of data sources such as Excel, Google Sheets and Databases using automation tools such as Zapier. Using these in our workflows will help us run tasks in the background without any human intervention!
APIs and Webhooks: Nanonets provides a wide range of APIs with great supporting documentation. Using these we can easily utilise trained models inside web-based projects without worrying about any infrastructure. Additionally, webhooks can be utilised to power one-way data sharing based on triggers.
[ad_2]
Source link