
[ad_1]
With the world increasingly going digital, businesses have turned to OCR tools to keep pace with the rapid digitization we are witnessing. Many documents like invoices, receipts, forms etc that businesses deal with on a daily basis are still widely used in the physical form. With the use of an Optical Character Recognition (OCR) tool any image of a physical document or even electronically generated document formats like PDFs can be transformed into a readable, searchable, manipulatable database of information.
By using an OCR tool, tasks that were done manually at a huge cost of time, money and fraught with errors and mistakes can be automated at a fraction of the cost. That explains why many companies are jumping on the automation bandwagon with an OCR tool.
OCR tools can fit neatly into existing workflows as well as open up opportunities for new and smarter workflows with the speed and agility needed for today’s organizations.
OCR is a technology developed in the 1970s to help convert text or information found in digital documents into machine readable data. It saw widespread adoption as it was commercially viable and businesses found immense value it offered at an affordable cost.
An OCR tool can recognize and extract text from photos, images, or any scanned document. The extracted text can then be further processed for activities like data entry, information indexing, or creation of a database.
OCR tools can also help with the conversion of the extracted data into a different file formats like JSON, XML, CSV, XLSX etc,.
Nanonets™ online OCR tool has many interesting use cases that could optimize your business performance, save costs, and boost growth. Find out how Nanonets™ can apply to your product.
OCR tools used today are far superior to the ones we’ve had in the past and use advances in areas like Machine Learning and Artificial Intelligence. They also adopt techniques like Natural Language Processing which allow them to infer the context beyond just extracting text.
With these advances, OCR tools can perform operations like not just extraction of text but also understand the meanings behind it and enable functions like fraud detection and so on.
OCR tools are now capable of working on documents that non-standard and conform to any format. As they work on more and more documents the performance keeps improving as the AI algorithms behind these OCR tools are constantly learning and updating.
While there are many solutions in the market it’ll be worthwhile to spend some time understanding your business requirements not just for now but those that might occur in the future as well. This will help in adopting a stable solution that can seamlessly scale as your requirements increase.
- Choose a solution that can work on standard as well non-standard formats (AI based OCR tools work well here)
- Select a software that can work on all languages and is not limited to specific languages
- Avoid template based OCR solutions as they perform poorly even if the format changes a wee bit
- If the OCR tool can detect handwritten text that’ll be a plus
- Don’t settle for a tool that specializes only on certain verticals unless your business is entirely in that vertical
- Look at the total cost of using an OCR tool than just the fixed fee and the pricing gets cheaper as you use more
- Choose a SaaS based OCR tool over installed software as these tools improve over time and offer additional functionality/features as they improve
Here’s a review of some of the widely used OCR tools.
Nanonets
Nanonets™ AI-based OCR solution uses advanced machine learning and deep learning techniques to extract information from any document type in any language. With it’s fast, accurate, simple, intuitive, and easy-to-use interface, businesses can automate data extraction from invoices, receipts, ID cards, forms and more. Using Nanonets™ APIs, extracted data output can be easily integrated with everyday apps via a simple and intuitive interface.
Benefits of Nanonets AI based online OCR tool
Pros:
- Modern UI
- Handles large volumes of documents
- Reasonably priced
- Ease of use
- Cognitive capture of data – resulting in minimal intervention
- Requires no in-house team of developers
- Algorithm/models can be trained/retrained
- Great documentation & support
- Lots of customization options
- Wide choice of integration options
- Works with non-English or multiple languages
- Almost no post-processing required
- Seamless 2-way integration with multiple accounting software
- Great API for developers
Cons:
- Can’t handle very high volume spikes
- Table capture UI can be better
Looking for an OCR tool to extract information from documents? Give Nanonets™ a spin for higher accuracy, greater flexibility, post-processing, and a broad set of integrations!
ABBYY Finereader
ABBYY FineReader PDF is an OCR software with support for PDF file editing. The program allows the conversion of image documents into editable electronic formats.
Pros:
- Keyboard-friendly OCR editor for manual corrections
- Exceptionally clear interface
- Exports to multiple formats
- Unique document-compare feature
Cons:
- Lacks full-text indexing for fast searches
- Requires a learning curve
- Pricing can be prohibitive
- Inability to view the history of document changes
- Can’t merge several files into one
- Might require some post-processing
- The UI could be overwhelming at first
- Slow to process big files
ABBYY Flexicapture
FlexiCapture is a stable, scalable document imaging and data extraction software that automatically transforms documents of any structure, language or content into usable and accessible business-ready data.
Pros:
- Recognizes images very well
- Easy to store hard copy result in system
- Integrates well with ERP systems
- Automates data extraction from documents (to an extent)
Cons:
- Initial setup can be difficult and complex
- Automatic processing of invoices not set up
- No ready-made templates
- Difficult to customize
- No resources available
- Could have better integration with RPA solutions
- Low accuracy with low resolution images/documents
- Batch verifications are held up even if there’s an error just in a particular section
- Line item error messages pop up even for items that should be skipped
- RESTful API is not available in the on-prem version
Kofax Omnipage
Omnipage is a powerful PDF OCR software that can handle automation for high-volume corporate OCR tasks. This tool specialises in table extraction, line item matching, and smart extraction.
Pros:
- Has a robust set of tools for enhancing images
- Highly accurate
Cons:
- UI not intuitive
- Configuration for AP Automation is not straightforward
- API integration can be improved
IBM Datacap
Datacap streamlines the capture, recognition and classification of business documents to extract important information from them. Datacap has a strong OCR engine, multiple functions as well as customisable rules. It works across multiple channels, including scanners, mobile devices, multifunction peripherals and fax.
Pros:
- Configures complex applications in data capture
- Scanning mechanism
- Ease of use
Cons:
- Very little online support
- UI could be more intuitive
- Setup can be cumbersome
- Slow
- Creating a customized flow isn’t straightforward
- Batch commits take time
Google Document AI
One of the solutions in the Google Cloud AI suite, the Document AI (DocAI) is a document processing console that uses machine learning to automatically classify, extract, enrich data and unlock insights within documents.
Pros:
- Easy to set up
- Integrates very well with other Google services
- Storage of information
- Speed
Cons:
- AI modules lack proper documentation
- Customization of existing modules and libraries is hard
- Not suited for Python or other coding languages
- Outdated API documentation
- Expensive
- Not suited for hybrid cloud deployments
- Not suited for use cases that require custom AI algorithms
AWS Textract automatically extracts text and other data from scanned documents using machine learning and OCR. It is also used to identify, understand, and extract data from forms and tables. For more information check out this detailed breakdown of AWS Textract.
Pros:
- Pay-per-use billing model
- Ease of use
Cons:
- Can’t be trained
- Varying accuracy
- Not meant for handwritten documents
Docparser
Docparser is a cloud-based document processing and OCR software that can automate low-value tasks and workflows for businesses.
Pros:
- Easy setup
- Zapier integration
Cons:
- The webhooks occasionally fail
- Requires some deal of training to pick up the parsing rules
- Not enough templates
- Zonal OCR approach – can’t handle unknown templates
- UI could be better
- Slow to load pages
- Documentation could be better
Adobe Acrobat DC
Adobe provides a comprehensive PDF editor with an in-built OCR functionality.
Pros:
- Stability/compatibility.
- Ease of use
Cons:
- Expensive
- Not an exclusive OCR software
- Heavy on the system
- Takes up a lot of space on the hard disk
- Difficult to integrate with services like Sharepoint or Dropbox
- Requires an Adobe Creative Cloud license.
Klippa
Klippa provides automated document management, processing, classification and data extraction solutions to digitize paper documents in your organization.
Pros:
- Fast setup
- Great support
- Great API for developers
- Clear and concise API documentation
- Links well with accounting programs
- Competitively priced
- Integrations
Cons:
- OCR recognition can be better
- Limited template customizations
- Limited white-label customizations
- Bulk adjustments not supported
- The VAT is often not displayed correctly
- The app crashes often
- Can’t train the OCR model
- The selection process isn’t straightforward as there are a lot of options
Other notable mentions include Veryfi, Readiris, Infrrd, Rossum & Hypatos.
Here’s a quick comparison of all the OCR software listed above across some crucial OCR software features & parameters:
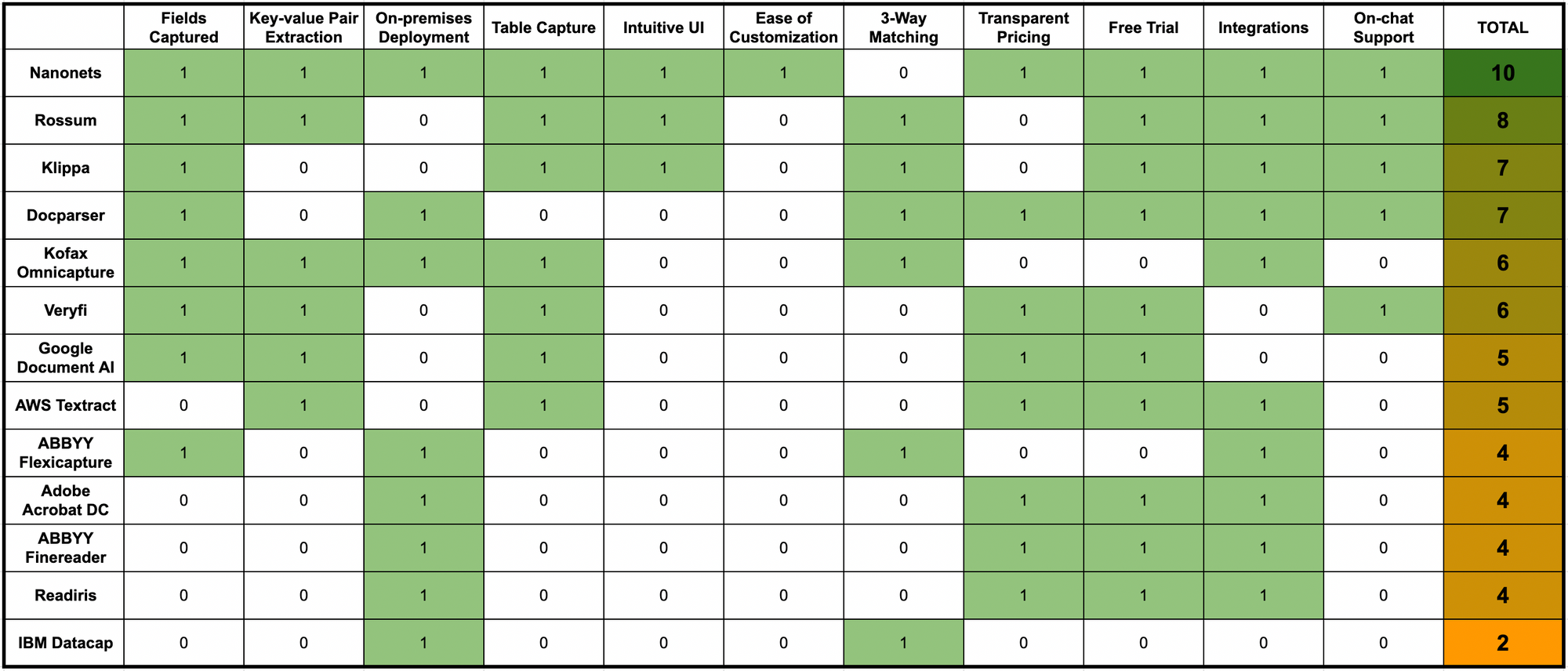
There are many benefits in using Nanonets™ for document automation needs:
- Easy and flexible to setup requiring just about a day to get going
- Handles unstructured data and common data constraints with ease
- Multi-page and multi-line documents are extracted without any additional set up
- High accuracy in extraction without/with minimal rework or revisions
- Customizable for any dataset while many solutions on the market are rigid on the template used
- Nanonets™ uses your own data and gets better as it meets the particular needs of your business
- It’s the easiest when it comes adding new custom fields or handling integrations
- Avoid post-processing work as Nanonets™ intelligently extracts only the fields of interest unlike other solutions that simply grab and dump all info
- Nanonets™ can handle handwritten text, blurred/low resolution images, images with cursive fonts/new fonts/shadowy text/tilted text/image noise etc,.
- Nanonets™ can handle any language or even multiple languages at once
- Easy to integrate Nanonets™ with most CRM, ERP, RPA software without any developer support
Looking for an OCR tool to extract information from documents? Give Nanonets™ a spin for higher accuracy, greater flexibility, post-processing, and a broad set of integrations!
Some users may choose free OCR tools that run on open source OCR engines like Tesseract. These are mostly suited for one-time needs and simple use cases like converting PDFs, Photos, TIFFs etc,. into editable text.
If you’re planning to process handwritten documents, low quality images, long line items or multi-column tables, a free OCR solution may not work. Also, while some free OCR solutions run as web-based applications other standalone solutions may require an installation.
Below, you’ll find a list of free OCR solution that you could consider for simple or one-time tasks:
- English OCR
- Photo Scan
- Adobe Scan
- OnlineOCR.net
- FreeOCR
- SimpleOCR
- GOCR
- Office Lens
- Easy Screen OCR
- Capture2Text
- A9t9
- Microsoft OneNote OCR
- OCR on Google Docs
[ad_2]
Source link