
[ad_1]

This Machine Learning tutorial provides basic and intermediate concepts of machine learning. It is designed for students and working professionals who are complete beginners. At the end of this tutorial, you won’t be an expert at Machine Learning but you will be able to make machine learning models that can perform complex tasks such as predicting the price of a house or recognising the species of an Iris from the dimensions of its petal and sepal lengths. If you are not a complete beginner and are a bit familiar with Machine Learning, I would suggest starting with subtopic eight i.e, Types of Machine Learning.
Before jumping into the tutorial, you should be familiar with Pandas and NumPy. This is important to understand the implementation part. There are no prerequisites for understanding the theory of it. Here are the subtopics that we are going to discuss in this tutorial:
Table of Machine Learning Tutorial
- What is Machine learning?
- How is it different from traditional programming?
- Why do we need Machine Learning?
- History of Machine Learning
- Machine Learning at Present
- Features of Machine Learning
- Types of machine learning
-
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
- Machine Learning Algorithms
- Steps in Machine learning
- Evaluation of Machine learning Model
- Python for Machine Learning?
- Implementation of Machine Learning with Python
- Advantages of Machine Learning
- Disadvantages of Machine Learning
- Machine Learning in Future
What is Machine Learning?
Arthur Samuel coined the term Machine Learning in the year 1959. He was a pioneer in Artificial Intelligence and computer gaming, and defined Machine Learning as “Field of study that gives computers the capability to learn without being explicitly programmed”.
In simple terms, Machine Learning is an application of Artificial Intelligence (AI) which enables a program(software) to learn from the experiences and improve their self at a task without being explicitly programmed. For example, how would you write a program that can identify fruits based on their various properties, such as colour, shape, size or any other property?
One approach is to hardcode everything, make some rules and use them to identify the fruits. This may seem the only way and work but one can never make perfect rules that apply on all cases. This problem can be easily solved using machine learning without any rules which makes it more robust and practical. You will see how we will use machine learning to do this task in the coming sections.
Thus, we can say that Machine Learning is the study of making machines more human-like in their behaviour and decision making by giving them the ability to learn with minimum human intervention, i.e., no explicit programming. Now the question arises, how can a program attain any experience and from where does it learn? The answer is data. Data is also called the fuel for Machine Learning and we can safely say that there is no machine learning without data.
You may be wondering that the term Machine Learning has been introduced in 1959 which is a long way back, then why haven’t there been any mention of it till recent years? You may want to note that Machine Learning needs a huge computational power, a lot of data and devices which are capable of storing such vast data. We have only recently reached a point where we now have all these requirements and can practice Machine Learning.
How is it different from traditional programming?
Are you wondering how is Machine Learning different from traditional programming? Well, in traditional programming, we would feed the input data and a well written and tested program into a machine to generate output. When it comes to machine learning, input data along with the output associated with the data is fed into the machine during the learning phase, and it works out a program for itself. To understand this better, refer to the illustration below:

Don’t worry if you are not able to understand this completely, in the coming sections you will get a better understanding. You may want to come back to this figure once we discuss the steps that are involved in machine learning to clear all your doubts.
Why do we need Machine Learning?
Machine Learning today has all the attention it needs. Machine Learning can automate many tasks, especially the ones that only humans can perform with their innate intelligence. Replicating this intelligence to machines can be achieved only with the help of machine learning.
With the help of Machine Learning, businesses can automate routine tasks. It also helps in automating and quickly create models for data analysis. Various industries depend on vast quantities of data to optimize their operations and make intelligent decisions. Machine Learning helps in creating models that can process and analyze large amounts of complex data to deliver accurate results. These models are precise and scalable and function with less turnaround time. By building such precise Machine Learning models, businesses can leverage profitable opportunities and avoid unknown risks.
Image recognition, text generation, and many other use-cases are finding applications in the real world. This is increasing the scope for machine learning experts to shine as a sought after professionals.
How Does Machine Learning Work?
A machine learning model learns from the historical data fed to it and then builds prediction algorithms to predict the output for the new set of data the comes in as input to the system. The accuracy of these models would depend on the quality and amount of input data. A large amount of data will help build a better model which predicts the output more accurately.
Suppose we have a complex problem at hand that requires to perform some predictions. Now, instead of writing a code, this problem could be solved by feeding the given data to generic machine learning algorithms. With the help of these algorithms, the machine will develop logic and predict the output. Machine learning has transformed the way we approach business and social problems. Below is a diagram that briefly explains the working of a machine learning model/ algorithm. our way of thinking about the problem. The below block diagram explains the working of Machine Learning algorithm:
History of Machine Learning
Nowadays, we can see some amazing applications of ML such as in self-driving cars, Natural Language Processing and many more. But Machine learning has been here for over 70 years now. It all started in 1943, when neurophysiologist Warren McCulloch and mathematician Walter Pitts wrote a paper about neurons, and how they work. They decided to create a model of this using an electrical circuit, and therefore, the neural network was born.
In 1950, Alan Turing created the “Turing Test” to determine if a computer has real intelligence. To pass the test, a computer must be able to fool a human into believing it is also human. In 1952, Arthur Samuel wrote the first computer learning program. The program was the game of checkers, and the IBM computer improved at the game the more it played, studying which moves made up winning strategies and incorporating those moves into its program.
Just after a few years, in 1957, Frank Rosenblatt designed the first neural network for computers (the perceptron), which simulates the thought processes of the human brain. Later, in 1967, the “nearest neighbour” algorithm was written, allowing computers to begin using very basic pattern recognition. This could be used to map a route for travelling salesmen, starting at a random city but ensuring they visit all cities during a short tour.
But we can say that in the 1990s we saw a big change. Now work on machine learning shifted from a knowledge-driven approach to a data-driven approach. Scientists began to create programs for computers to analyze large amounts of data and draw conclusions or “learn” from the results.
In 1997, IBM’s Deep Blue became the first computer chess-playing system to beat a reigning world chess champion. Deep Blue used the computing power in the 1990s to perform large-scale searches of potential moves and select the best move. Just a decade before this, in 2006, Geoffrey Hinton created the term “deep learning” to explain new algorithms that help computers distinguish objects and text in images and videos.

Machine Learning at Present
The year 2012 saw the publication of an influential research paper by Alex Krizhevsky, Geoffrey Hinton, and Ilya Sutskever, describing a model that can dramatically reduce the error rate in image recognition systems. Meanwhile, Google’s X Lab developed a machine learning algorithm capable of autonomously browsing YouTube videos to identify the videos that contain cats. In 2016 AlphaGo (created by researchers at Google DeepMind to play the ancient Chinese game of Go) won four out of five matches against Lee Sedol, who has been the world’s top Go player for over a decade.
And now in 2020, OpenAI released GPT-3 which is the most powerful language model ever. It can write creative fiction, generate functioning code, compose thoughtful business memos and much more. Its possible use cases are limited only by our imaginations.
Features of Machine Learning
Automation: Nowadays in your Gmail account, there is a spam folder that contains all the spam emails. You might be wondering how does Gmail know that all these emails are spam? This is the work of Machine Learning. It recognises the spam emails and thus, it is easy to automate this process. The ability to automate repetitive tasks is one of the biggest characteristics of machine learning. A huge number of organizations are already using machine learning-powered paperwork and email automation. In the financial sector, for example, a huge number of repetitive, data-heavy and predictable tasks are needed to be performed. Because of this, this sector uses different types of machine learning solutions to a great extent.
Improved customer experience: For any business, one of the most crucial ways to drive engagement, promote brand loyalty and establish long-lasting customer relationships is by providing a customized experience and providing better services. Machine Learning helps us to achieve both of them. Have you ever noticed that whenever you open any shopping site or see any ads on the internet, they are mostly about something that you recently searched for? This is because machine learning has enabled us to make amazing recommendation systems that are accurate. They help us customize the user experience. Now coming to the service, most of the companies nowadays have a chatting bot with them that are available 24×7. An example of this is Eva from AirAsia airlines. These bots provide intelligent answers and sometimes you might even not notice that you are having a conversation with a bot. These bots use Machine Learning, which helps them to provide a good user experience.
Automated data visualization: In the past, we have seen a huge amount of data being generated by companies and individuals. Take an example of companies like Google, Twitter, Facebook. How much data are they generating per day? We can use this data and visualize the notable relationships, thus giving businesses the ability to make better decisions that can actually benefit both companies as well as customers. With the help of user-friendly automated data visualization platforms such as AutoViz, businesses can obtain a wealth of new insights in an effort to increase productivity in their processes.
Business intelligence: Machine learning characteristics, when merged with big data analytics can help companies to find solutions to the problems that can help the businesses to grow and generate more profit. From retail to financial services to healthcare, and many more, ML has already become one of the most effective technologies to boost business operations.
Python provides flexibility in choosing between object-oriented programming or scripting. There is also no need to recompile the code; developers can implement any changes and instantly see the results. You can use Python along with other languages to achieve the desired functionality and results.
Python is a versatile programming language and can run on any platform including Windows, MacOS, Linux, Unix, and others. While migrating from one platform to another, the code needs some minor adaptations and changes, and it is ready to work on the new platform.
Here is a summary of the benefits of using Python for Machine Learning problems:

Types of Machine Learning
Machine learning has been broadly categorized into three categories
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
What is Supervised Learning?
Let us start with an easy example, say you are teaching a kid to differentiate dogs from cats. How would you do it?
You may show him/her a dog and say “here is a dog” and when you encounter a cat you would point it out as a cat. When you show the kid enough dogs and cats, he may learn to differentiate between them. If he is trained well, he may be able to recognise different breeds of dogs which he hasn’t even seen.
Similarly, in Supervised Learning, we have two sets of variables. One is called the target variable, or labels (the variable we want to predict) and features(variables that help us to predict target variables). We show the program(model) the features and the label associated with these features and then the program is able to find the underlying pattern in the data. Take this example of the dataset where we want to predict the price of the house given its size. The price which is a target variable depends upon the size which is a feature.
| Number of rooms | Price |
| 1 | $100 |
| 3 | $300 |
| 5 | $500 |
In a real dataset, we will have a lot more rows and more than one features like size, location, number of floors and many more.
Thus, we can say that the supervised learning model has a set of input variables (x), and an output variable (y). An algorithm identifies the mapping function between the input and output variables. The relationship is y = f(x).
The learning is monitored or supervised in the sense that we already know the output and the algorithm are corrected each time to optimise its results. The algorithm is trained over the data set and amended until it achieves an acceptable level of performance.
We can group the supervised learning problems as:
Regression problems – Used to predict future values and the model is trained with the historical data. E.g., Predicting the future price of a house.
Classification problems – Various labels train the algorithm to identify items within a specific category. E.g., Dog or cat( as mentioned in the above example), Apple or an orange, Beer or wine or water.
What is Unsupervised Learning?
This approach is the one where we have no target variables, and we have only the input variable(features) at hand. The algorithm learns by itself and discovers an impressive structure in the data.
The goal is to decipher the underlying distribution in the data to gain more knowledge about the data.
We can group the unsupervised learning problems as:
Clustering: This means bundling the input variables with the same characteristics together. E.g., grouping users based on search history
Association: Here, we discover the rules that govern meaningful associations among the data set. E.g., People who watch ‘X’ will also watch ‘Y’.
What is Reinforcement Learning?
In this approach, machine learning models are trained to make a series of decisions based on the rewards and feedback they receive for their actions. The machine learns to achieve a goal in complex and uncertain situations and is rewarded each time it achieves it during the learning period.
Reinforcement learning is different from supervised learning in the sense that there is no answer available, so the reinforcement agent decides the steps to perform a task. The machine learns from its own experiences when there is no training data set present.
In this tutorial, we are going to mainly focus on Supervised Learning and Unsupervised learning as these are quite easy to understand and implement.
Machine learning Algorithms
This may be the most time-consuming and difficult process in your journey of Machine Learning. There are many algorithms in Machine Learning and you don’t need to know them all in order to get started. But I would suggest, once you start practising Machine Learning, start learning about the most popular algorithms out there such as:
Here, I am going to give a brief overview of one of the simplest algorithms in Machine learning, the K-nearest neighbour Algorithm (which is a Supervised learning algorithm) and show how we can use it for Regression as well as for classification. I would highly recommend checking the Linear Regression and Logistic Regression as we are going to implement them and compare the results with KNN(K-nearest neighbour) algorithm in the implementation part.
You may want to note that there are usually separate algorithms for regression problems and classification problems. But by modifying an algorithm, we can use it for both classifications as well as regression as you will see below
K-Nearest Neighbour Algorithm
KNN belongs to a group of lazy learners. As opposed to eager learners such as logistic regression, SVM, neural nets, lazy learners just store the training data in memory. During the training phase, KNN arranges the data (sort of indexing process) in order to find the closest neighbours efficiently during the inference phase. Otherwise, it would have to compare each new case during inference with the whole dataset making it quite inefficient.
So if you are wondering what is a training phase, eager learners and lazy learners, for now just remember that training phase is when an algorithm learns from the data provided to it. For example, if you have gone through the Linear Regression algorithm linked above, during the training phase the algorithm tries to find the best fit line which is a process that includes a lot of computations and hence takes a lot of time and this type of algorithm is called eager learners. On the other hand, lazy learners are just like KNN which do not involve many computations and hence train faster.
K-NN for Classification Problem
Now let us see how we can use K-NN for classification. Here a hypothetical dataset which tries to predict if a person is male or female(labels) on the base of the height and weight(features).
| Height(cm) -feature | Weight(kg) -feature. | Gender(label) |
| 187 | 80 | Male |
| 165 | 50 | Female |
| 199 | 99 | Male |
| 145 | 70 | Female |
| 180 | 87 | Male |
| 178 | 65 | Female |
| 187 | 60 | Male |
Now let us plot these points:

Now we have a new point that we want to classify, given that its height is 190 cm and weight is 100 Kg. Here is how K-NN will classify this point:
- Select the value of K, which the user selects which he thinks will be best after analysing the data.
- Measure the distance of new points from its nearest K number of points. There are various methods for calculating this distance, of which the most commonly known methods are – Euclidian, Manhattan (for continuous data points i.e regression problems) and Hamming distance (for categorical i.e for classification problems).
- Identify the class of the points that are more closer to the new point and label the new point accordingly. So if the majority of points closer to our new point belong to a certain “a” class than our new point is predicted to be from class “a”.
Now let us apply this algorithm to our own dataset. Let us first plot the new data point.

Now let us take k=3 i.e, we will see the three closest points to the new point:

Therefore, it is classified as Male:

Now let us take the value of k=5 and see what happens:

As we can see four of the points closest to our new data point are males and just one point is female, so we go with the majority and classify it as Male again. You must always select the value of K as an odd number when doing classification.
K-NN for a Regression problem
We have seen how we can use K-NN for classification. Now, let us see what changes are made to use it for regression. The algorithm is almost the same there is just one difference. In Classification, we checked for the majority of all nearest points. Here, we are going to take the average of all the nearest points and take that as predicted value. Let us again take the same example but here we have to predict the weight(label) of a person given his height(features).
| Height(cm) -feature | Weight(kg) -label |
| 187 | 80 |
| 165 | 50 |
| 199 | 99 |
| 145 | 70 |
| 180 | 87 |
| 178 | 65 |
| 187 | 60 |
Now we have new data point with a height of 160cm, we will predict its weight by taking the values of K as 1,2 and 4.
When K=1: The closest point to 160cm in our data is 165cm which has a weight of 50, so we conclude that the predicted weight is 50 itself.
When K=2: The two closest points are 165 and 145 which have weights equal to 50 and 70 respectively. Taking average we say that the predicted weight is (50+70)/2=60.
When K=4: Repeating the same process, now we take 4 closest points instead and hence we get 70.6 as predicted weight.
You might be thinking that this is really simple and there is nothing so special about Machine learning, it is just basic Mathematics. But remember this is the simplest algorithm and you will see much more complex algorithms once you move ahead in this journey.
At this stage, you must have a vague idea of how machine learning works, don’t worry if you are still confused. Also if you want to go a bit deep now, here is an excellent article – Gradient Descent in Machine Learning, which discusses how we use an optimization technique called as gradient descent to find a best-fit line in linear regression.
How To Choose Machine Learning Algorithm?
There are plenty of machine learning algorithms and it could be a tough task to decide which algorithm to choose for a specific application. The choice of the algorithm will depend on the objective of the problem you are trying to solve.
Let us take an example of a task to predict the type of fruit among three varieties, i.e., apple, banana, and orange. The predictions are based on the colour of the fruit. The picture depicts the results of ten different algorithms. The picture on the top left is the dataset. The data is classified into three categories: red, light blue and dark blue. There are some groupings. For instance, from the second image, everything in the upper left belongs to the red category, in the middle part, there is a mixture of uncertainty and light blue while the bottom corresponds to the dark category. The other images show different algorithms and how they try to classified the data.
Steps in Machine Learning
I wish Machine learning was just applying algorithms on your data and get the predicted values but it is not that simple. There are several steps in Machine Learning which are must for each project.
- Gathering Data: This is perhaps the most important and time-consuming process. In this step, we need to collect data that can help us to solve our problem. For example, if you want to predict the prices of the houses, we need an appropriate dataset that contains all the information about past house sales and then form a tabular structure. We are going to solve a similar problem in the implementation part.
- Preparing that data: Once we have the data, we need to bring it in proper format and preprocess it. There are various steps involved in pre-processing such as data cleaning, for example, if your dataset has some empty values or abnormal values(e.g, a string instead of a number) how are you going to deal with it? There are various ways in which we can but one simple way is to just drop the rows that have empty values. Also sometimes in the dataset, we might have columns that have no impact on our results such as id’s, we remove those columns as well.We usually use Data Visualization to visualise our data through graphs and diagrams and after analyzing the graphs, we decide which features are important.Data preprocessing is a vast topic and I would suggest checking out this article to know more about it.
- Choosing a model: Now our data is ready is to be fed into a Machine Learning algorithm. In case you are wondering what is a Model? Often “machine learning algorithm” is used interchangeably with “machine learning model.” A model is the output of a machine learning algorithm run on data. In simple terms when we implement the algorithm on all our data, we get an output which contains all the rules, numbers, and any other algorithm-specific data structures required to make predictions. For example, after implementing Linear Regression on our data we get an equation of the best fit line and this equation is termed as a model.The next step is usually training the model incase we don’t want to tune hyperparameters and select the default ones.
- Hyperparameter Tuning: Hyperparameters are crucial as they control the overall behaviour of a machine learning model. The ultimate goal is to find an optimal combination of hyperparameters that gives us the best results. But what are these hyper-parameters? Remember the variable K in our K-NN algorithm. We got different results when we set different values of K.The best value for K is not predefined and is different for different datasets. There is no method to know the best value for K, but you can try different values and check for which value do we get the best results. Here K is a hyperparameter and each algorithm has its own hyperparameters and we need to tune their values to get the best results. To get more information about it,check out this article –Hyperparameter Tuning Explained.
- Evaluation: You may be wondering, how can you know if the model is performing good or bad.What better way than testing the model on some data. This data is known as testing data and it must not be a subset of the data(training data) on which we trained the algorithm. The objective of training the model is not for it to learn all the values in the training dataset but to identify the underlying pattern in data and based on that make predictions on data it has never seen before. There are various evaluation methods such as K-fold cross-validation and many more. We are going to discuss this step in detail in the coming section.
- Prediction: Now that our model has performed well on the testing set as well, we can use it in real-world and hope it is going to perform well on real-world data.

Evaluation of Machine learning Model
For evaluating the model, we hold out a portion of data called test data and do not use this data to train the model. Later, we use test data to evaluate various metrics.
The results of predictive models can be viewed in various forms such as by using confusion matrix, root-mean-squared error(RMSE), AUC-ROC etc.
A confusion matrix used in classification problems is a table that displays the number of instances that are correctly and incorrectly classified in terms of each category within the attribute that is the target class as shown in the figure below:

TP (True Positive) is the number of values predicted to be positive by the algorithm and was actually positive in the dataset. TN represents the number of values that are expected to not belong to the positive class and actually do not belong to it. FP depicts the number of instances misclassified as belonging to the positive class thus is actually part of the negative class. FN shows the number of instances classified as the negative class but should belong to the positive class.
Now in Regression problem, we usually use RMSE as evaluation metrics. In this evaluation technique, we use the error term.
Let’s say you feed a model some input X and the model predicts 10, but the actual value is 5. This difference between your prediction (10) and the actual observation (5) is the error term: (f_prediction – i_actual). The formula to calculate RMSE is given by:
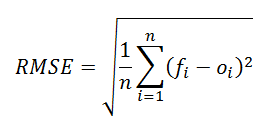
Where N is a total number of samples for which we are calculating RMSE.
In a good model, the RMSE should be as low as possible and there should not be much difference between RMSE calculated over training data and RMSE calculated over the testing set.
Python for Machine Learning?
Although there are many languages that can be used for machine learning, according to me, Python is hands down the best programming language for Machine Learning applications. This is due to the various benefits mentioned in the section below. Other programming languages that could to use for Machine Learning Applications are R, C++, JavaScript, Java, C#, Julia, Shell, TypeScript, and Scala. R is also a really good language to get started with machine learning.
Python is famous for its readability and relatively lower complexity as compared to other programming languages. Machine Learning applications involve complex concepts like calculus and linear algebra which take a lot of effort and time to implement. Python helps in reducing this burden with quick implementation for the Machine Learning engineer to validate an idea. You can check out the Python Tutorial to get a basic understanding of the language. Another benefit of using Python in Machine Learning is the pre-built libraries. There are different packages for a different type of applications, as mentioned below:
- Numpy, OpenCV, and Scikit are used when working with images
- NLTK along with Numpy and Scikit again when working with text
- Librosa for audio applications
- Matplotlib, Seaborn, and Scikit for data representation
- TensorFlow and Pytorch for Deep Learning applications
- Scipy for Scientific Computing
- Django for integrating web applications
- Pandas for high-level data structures and analysis
Implementation of algorithms in Machine Learning with Python
Before moving on to the implementation part, you need to download some important software and libraries. For this, you can refer to this article where you will know how to install anaconda on your PC and basics of Python. Anaconda is an open-source distribution that makes it easy to perform Python/R data science and machine learning on a single machine.It contains all most all the libraries that are needed by us. In this tutorial, we are mostly going to use the scikit-learn library which is a free software machine learning library for the Python programming language.
Now, we are going to implement all that we learnt till now. We will solve a Regression problem and then a Classification problem using the seven steps mentioned above.
Implementation of a Regression problem
We have a problem of predicting the prices of the house given some features such as size, number of rooms and many more. So let us get started:
- Gathering data: We don’t need to manually collect the data for past sales of houses. Luckily there are some good people who do it for us and make these datasets available for us to use. Also let me mention not all datasets are free but for you to practice, you will find most of the datasets free to use on the internet.
The dataset we are using is called the Boston Housing dataset. Each record in the database describes a Boston suburb or town. The data was drawn from the Boston Standard Metropolitan Statistical Area (SMSA) in 1970. The attributes are defined as follows (taken from the UCI Machine Learning Repository).
- CRIM: per capita crime rate by town
- ZN: proportion of residential land zoned for lots over 25,000 sq.ft.
- INDUS: proportion of non-retail business acres per town
- CHAS: Charles River dummy variable (= 1 if tract bounds river; 0 otherwise)
- NOX: nitric oxides concentration (parts per 10 million)
- RM: average number of rooms per dwelling
- AGE: the proportion of owner-occupied units built prior to 1940
- DIS: weighted distances to five Boston employment centers
- RAD: index of accessibility to radial highways
- TAX: full-value property-tax rate per $10,000
- PTRATIO: pupil-teacher ratio by town
- B: 1000(Bk−0.63)2 where Bk is the proportion of blacks by town
- LSTAT: % lower status of the population
- MEDV: Median value of owner-occupied homes in $1000s
Here is a link to download this dataset.
Now after opening the file you can see the data about House sales. This dataset is not in a proper tabular form, in fact, there are no column names and each value is separated by spaces. We are going to use Pandas to put it in proper tabular form. We will provide it with a list containing column names and also use delimiter as ‘s+’ which means that after encounterings a single or multiple spaces, it can differentiate every single entry.
We are going to import all the necessary libraries such as Pandas and NumPy.Next, we will import the data file which is in CSV format into a pandas DataFrame.
import numpy as np
import pandas as pd
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX','PTRATIO', 'B', 'LSTAT', 'MEDV']
bos1 = pd.read_csv('housing.csv', delimiter=r"s+", names=column_names)

2. Preprocess Data: The next step is to pre-process the data. Now for this dataset, we can see that there are no NaN (missing) values and also all the data is in numbers rather than strings so we won’t face any errors when training the model. So let us just divide our data into training data and testing data such that 70% of data is training data and the rest is testing data. We could also scale our data to make the predictions much accurate but for now, let us keep it simple.
bos1.isna().sum()

from sklearn.model_selection import train_test_split X=np.array(bos1.iloc[:,0:13]) Y=np.array(bos1["MEDV"]) #testing data size is of 30% of entire data x_train, x_test, y_train, y_test =train_test_split(X,Y, test_size = 0.30, random_state =5)
3. Choose a Model: For this particular problem, we are going to use two algorithms of supervised learning that can solve regression problems and later compare their results.One algorithm is K-NN (K-nearest Neighbor) which is explained above and the other is Linear Regression.I would highly recommend to check it out in case you haven’t already.
from sklearn.linear_model import LinearRegression from sklearn.neighbors import KNeighborsRegressor #load our first model lr = LinearRegression() #train the model on training data lr.fit(x_train,y_train) #predict the testing data so that we can later evaluate the model pred_lr = lr.predict(x_test) #load the second model Nn=KNeighborsRegressor(3) Nn.fit(x_train,y_train) pred_Nn = Nn.predict(x_test)
4. Hyperparameter Tuning: Since this is a beginners tutorial, here, I am only going to turn the value ok K in the K-NN model. I will just use a for loop and check results of k ranging from 1 to 50. K-NN is extremely fast on small dataset like ours so it won’t take any time.There are much more advanced methods of doing this which you can find linked in the steps of Machine Learning section above.
import sklearn
for i in range(1,50):
model=KNeighborsRegressor(i)
model.fit(x_train,y_train)
pred_y = model.predict(x_test)
mse = sklearn.metrics.mean_squared_error(y_test, pred_y,squared=False)
print("{} error for k = {}".format(mse,i))
Output:

From the output, we can see that error is least for k=3, so that should justify why I put the value of K=3 while training the model
5. Evaluating the model: For evaluating the model we are going to use the mean_squared_error() method from the scikit-learn library. Remember to set the parameter ‘squared’ as False, to get the RMSE error.
#error for linear regression
mse_lr= sklearn.metrics.mean_squared_error(y_test, pred_lr,squared=False)
print("error for Linear Regression = {}".format(mse_lr))
#error for linear regression
mse_Nn= sklearn.metrics.mean_squared_error(y_test, pred_Nn,squared=False)
print("error for K-NN = {}".format(mse_Nn))

Now from the results, we can conclude that Linear Regression performs better than K-NN for this particular dataset. But It is not necessary that Linear Regression would always perform better than K-NN as it completely depends upon the data that we are working with.
6. Prediction: Now we can use the models to predict the prices of the houses using the predict function as we did above. Make sure when predicting the prices that we are given all the features that were present when training the model.
Here is the whole script:
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.neighbors import KNeighborsRegressor
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
bos1 = pd.read_csv('housing.csv', delimiter=r"s+", names=column_names)
X=np.array(bos1.iloc[:,0:13])
Y=np.array(bos1["MEDV"])
#testing data size is of 30% of entire data
x_train, x_test, y_train, y_test =train_test_split(X,Y, test_size = 0.30, random_state =54)
#load our first model
lr = LinearRegression()
#train the model on training data
lr.fit(x_train,y_train)
#predict the testing data so that we can later evaluate the model
pred_lr = lr.predict(x_test)
#load the second model
Nn=KNeighborsRegressor(12)
Nn.fit(x_train,y_train)
pred_Nn = Nn.predict(x_test)
#error for linear regression
mse_lr= sklearn.metrics.mean_squared_error(y_test, pred_lr,squared=False)
print("error for Linear Regression = {}".format(mse_lr))
#error for linear regression
mse_Nn= sklearn.metrics.mean_squared_error(y_test, pred_Nn,squared=False)
print("error for K-NN = {}".format(mse_Nn))
Implementation of a Classification problem
In this section, we will solve the population classification problem known as Iris Classification problem. The Iris dataset was used in R.A. Fisher’s classic 1936 paper, The Use of Multiple Measurements in Taxonomic Problems, and can also be found on the UCI Machine Learning Repository.
It includes three iris species with 50 samples each as well as some properties about each flower. One flower species is linearly separable from the other two, but the other two are not linearly separable from each other. The columns in this dataset are:

- SepalLengthCm
- SepalWidthCm
- PetalLengthCm
- PetalWidthCm
- Species
We don’t need to download this dataset as scikit-learn library already contains this dataset and we can simply import it from there. So let us start coding this up:
from sklearn.datasets import load_iris iris = load_iris() X=iris.data Y=iris.target print(X) print(Y)

As we can see, the features are in a list containing four items which are the features and at the bottom, we got a list containing labels which have been transformed into numbers as the model cannot understand names that are strings, so we encode each name as a number. This has already done by the scikit learn developers.
from sklearn.model_selection import train_test_split
#testing data size is of 30% of entire data
x_train, x_test, y_train, y_test =train_test_split(X,Y, test_size = 0.3, random_state =5)
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
#fitting our model to train and test
Nn = KNeighborsClassifier(8)
Nn.fit(x_train,y_train)
#the score() method calculates the accuracy of model.
print("Accuracy for K-NN is ",Nn.score(x_test,y_test))
Lr = LogisticRegression()
Lr.fit(x_train,y_train)
print("Accuracy for Logistic Regression is ",Lr.score(x_test,y_test))

Advantages of Machine Learning
1. Easily identifies trends and patterns
Machine Learning can review large volumes of data and discover specific trends and patterns that would not be apparent to humans. For instance, for e-commerce websites like Amazon and Flipkart, it serves to understand the browsing behaviors and purchase histories of its users to help cater to the right products, deals, and reminders relevant to them. It uses the results to reveal relevant advertisements to them.
2. Continuous Improvement
We are continuously generating new data and when we provide this data to the Machine Learning model which helps it to upgrade with time and increase its performance and accuracy. We can say it is like gaining experience as they keep improving in accuracy and efficiency. This lets them make better decisions.
3. Handling multidimensional and multi-variety data
Machine Learning algorithms are good at handling data that are multidimensional and multi-variety, and they can do this in dynamic or uncertain environments.
4. Wide Applications
You could be an e-tailer or a healthcare provider and make Machine Learning work for you. Where it does apply, it holds the capability to help deliver a much more personal experience to customers while also targeting the right customers.
Disadvantages of Machine Learning
1. Data Acquisition
Machine Learning requires a massive amount of data sets to train on, and these should be inclusive/unbiased, and of good quality. There can also be times where we must wait for new data to be generated.
2. Time and Resources
Machine Learning needs enough time to let the algorithms learn and develop enough to fulfill their purpose with a considerable amount of accuracy and relevancy. It also needs massive resources to function. This can mean additional requirements of computer power for you.
3. Interpretation of Results
Another major challenge is the ability to accurately interpret results generated by the algorithms. You must also carefully choose the algorithms for your purpose. Sometimes, based on some analysis you might select an algorithm but it is not necessary that this model is best for the problem.
4. High error-susceptibility
Machine Learning is autonomous but highly susceptible to errors. Suppose you train an algorithm with data sets small enough to not be inclusive. You end up with biased predictions coming from a biased training set. This leads to irrelevant advertisements being displayed to customers. In the case of Machine Learning, such blunders can set off a chain of errors that can go undetected for long periods of time. And when they do get noticed, it takes quite some time to recognize the source of the issue, and even longer to correct it.
Future of Machine Learning
Machine Learning can be a competitive advantage to any company, be it a top MNC or a startup. As things that are currently being done manually will be done tomorrow by machines. With the introduction of projects such as self-driving cars, Sophia(a humanoid robot developed by Hong Kong-based company Hanson Robotics) we have already started a glimpse of what the future can be. The Machine Learning revolution will stay with us for long and so will be the future of Machine Learning.
Machine Learning Tutorial FAQs
Q: How do I start learning Machine Learning?
A: You first need to start with the basics. You need to understand the prerequisites, which include learning Linear Algebra and Multivariate Calculus, Statistics, and Python. Then you need to learn several ML concepts, which include terminology of Machine Learning, types of Machine Learning, and Resources of Machine Learning. The third step is taking part in competitions.
Q: Is Machine Learning easy for beginners?
A: Machine Learning is not the easiest. The difficulty in learning Machine Learning is the hard debugging problem.
Q: What is a simple example of Machine Learning?
A: Recommendation Engines (Netflix); Sorting, tagging and categorizing photos (Yelp); Customer Lifetime Value (Asos); Self-Driving Cars (Waymo); Education (Duolingo); Determining Credit Worthiness (Deserve); Patient Sickness Predictions (KenSci); and Targeted Emails (Optimail).
Q: Can I learn Machine Learning in 3 months?
A: Machine Learning is vast and consists of several things. Therefore, it will take you around six months to learn it, provided you spend at least 5-6 days every day. Also, the time taken to learn Machine Learning depends a lot on your mathematical and analytical skills.
Q: Does Machine Learning require coding?
A: If you are learning traditional Machine Learning, it would require you to know software programming as it will help you to write machine learning algorithms. However, through some online educational platforms, you do not need to know coding to learn Machine Learning.
Q: Is Machine Learning a good career?
A: Machine Learning is one of the best careers at present. Whether it is for the current demand, job, and salary growth, Machine Learning Engineer is one of the best profiles. You need to be very good at data, automation, and algorithms.
Q: Can I learn Machine Learning without python?
A: To learn Machine Learning, you need to have some basic knowledge of Python. A version of Python that is supported by all Operating Systems such as Windows, Linux, etc., is Anaconda. It offers an overall package for machine learning, including matplotlib, scikit-learn, and NumPy.
Q: Where can I practice Machine Learning?
A: The online platforms where you can practice Machine Learning include CloudXLab, Google Colab, Kaggle, MachineHack, and OpenML.
Q: Where can I learn Machine Learning for free?
A: You can learn the basics of Machine Learning from online platforms like Great Learning. You can enroll in the Beginners Machine Learning course and get the certificate for free. The course is easy and perfect for beginners to start with.
This brings us to the end of this tutorial. Take up a machine learning course that will help you gain all the required knowledge to build a successful machine learning career and power ahead.
Further Reading
- Clustering algorithms in Machine Learning
- Overfiting and underfitting in Machine Learning
- Bagging and Boosting Methods to enhance Machine learning algorithms
- An introduction to Gradient Descent algorithm
- Ensemble method
13
[ad_2]
Source link