
[ad_1]
Machine Learning (ML) has become one of most widely used AI techniques for several companies, institutions and individuals who are in the business of automation. This is because of considerable improvements in the access to data and increases in computational power, which allow practitioners to achieve meaningful results across several areas.
Today, when it comes to image data, ML algorithms can interpret images the same way our brains do. These are used almost everywhere, right from face recognition while capturing images on our smartphones, automating tedious manual work, self-driving cars and everything in between.
In this blog, we’ll be deep-diving into machine learning image processing fundamentals and discuss various technologies that we could leverage to build state-of-the-art algorithms on image data.
- What is Image Processing and Why is it Important
- Working of Machine Learning Image Processing
- Libraries and Frameworks for Machine Learning Image Processing
- Deep Neural Networks on Images
- Conclusion
What is Image Processing and Why is it Important
Image Processing (IP) is a computer technology applied to images that help us process, analyze and extract useful information from them.

It is among rapidly growing technologies and has evolved widely over the years. Today, several companies and organizations of different sectors use image processing for several applications such as visualization, image information extraction, pattern recognition, classification, segmentation, and many more!
Primarily, there are two methods for image processing: analogue and digital image processing. The analogue IP method is applied to hard copies like scanned photos and printouts, and the outputs here are usually images. In comparison, the Digital IP is used in manipulating digital images by using computers; the outputs here are usually information connected with that image, such as data on features, characteristics, bounding boxes, or masks.
As discussed with Machine Learning and Deep Learning image processing techniques can become more powerful.
Here are some familiar use cases that leverage ML image processing techniques:
- Medical Imaging / Visualization: Help medical professionals interpret medical imaging and diagnose anomalies faster.
- Law Enforcement & Security: Aid in surveillance & biometric authentication.
- Self-Driving Technology: Assist in detecting objects and mimicking human visual cues & interactions.
- Gaming: Improving augmented reality and virtual reality gaming experiences.
- Image Restoration & Sharpening: Improve the quality of images or add popular filters etc.
- Pattern Recognition: Classify and recognize objects/patterns in images and understand contextual information.Image Retrieval: Recognize images for faster retrieval from large datasets.
In the next section, we’ll learn some of the fundamentals behind working Machine Learning Image Processing.
Working of Machine Learning Image Processing
Typically, machine learning algorithms have a specific pipeline or steps to learn from data. Let’s take a generic example of the same and model a working algorithm for an Image Processing use case.
Firstly, ML algorithms need a considerable amount of high-quality data to learn and predict highly accurate results. Hence, we’ll have to make sure the images are well processed, annotated, and generic for ML image processing. This is where Computer Vision (CV) comes into the picture; it’s a field concerning machines being able to understand the image data. Using CV, we can process, load, transform and manipulate images for building an ideal dataset for the machine learning algorithm.
For example, say we want to build an algorithm that will predict if a given image has a dog or a cat. For this, we’ll need to collect images of dogs and cats and preprocess them using CV. The preprocessing steps include:
- Converting all the images into the same format.
- Cropping the unnecessary regions on images.
- Transforming them into numbers for algorithms to learn from them(array of numbers).
Computers see an input image as an array of pixels, and it depends on the image resolution. Based on the image resolution, it will see height * width * dimension. E.g., An image of a 6 x 6 x 3 array of a matrix of RGB (3 refers to RGB values) and an image of a 4 x 4 x 1 array of a matrix of the grayscale image.
These features (data that’s processed) are then used in the next phase: to choose and build a machine-learning algorithm to classify unknown feature vectors given an extensive database of feature vectors whose classifications are known. For this, we’ll need to choose an ideal algorithm; some of the most popular ones include Bayesian Nets, Decision Trees, Genetic Algorithms, Nearest Neighbors and Neural Nets etc.
Below is a screenshot of classic machine learning image processing workflow for image data:
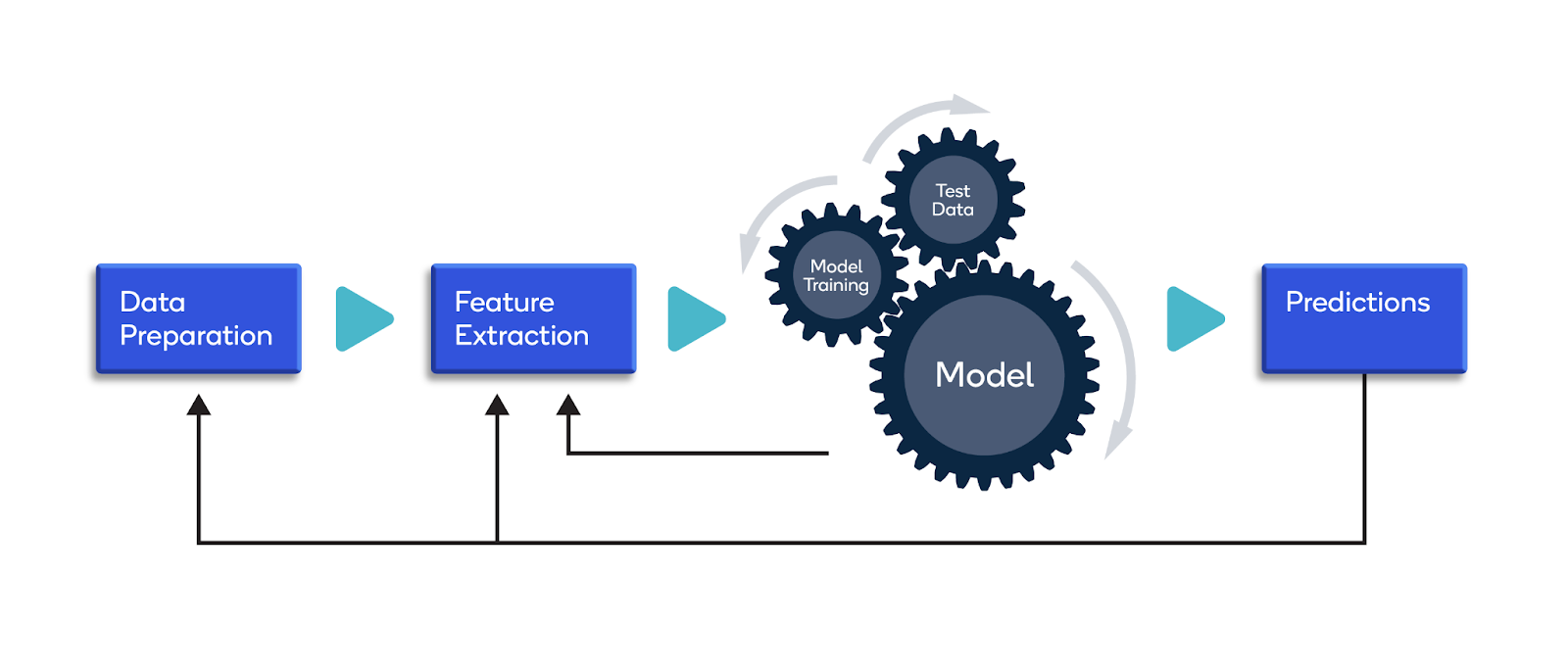
The algorithms learn from the patterns based on the training data with particular parameters. However, we can always fine-tune the trained model based on the performance metrics. Lastly, we can use the trained model to make new predictions on unseen data.
In the next section, we’ll review some of the technologies and frameworks we can utilise for building a Machine Learning image processing model.
Libraries and Frameworks for Machine Learning Image Processing
At present, there are more than 250 programming languages in existence, according to the TIOBE index. Out of these, Python is one of the most popular programming languages that’s heavily used by developers/practitioners for Machine Learning. However, we can always switch to a language that suits the use case. Now, we’ll look at some of the frameworks that we utilise for various applications.
OpenCV: OpenCV-Python is a library of Python bindings designed to solve computer vision problems. It’s simple and super easy to use.
Highlights:
- Huge library of image processing algorithms
- Open Source + Great Community
- Works on both images and videos
- Java API Extension
- Works with GPUs
- Cross-Platform
Tensorflow: Developed by Google, Tensorflow is one of the most popular end-to-end machine learning development frameworks.
Highlights:
- Wide range of ML, NN Algorithms
- Open Source + Great Community
- Work on multiple parallel processors
- GPU Configured
- Cross-Platform
PyTorch: PyTorch (by Facebook) is one of the most loved neural network frameworks for researchers. It’s more pythonic when compared with other ML libraries.
Highlights:
- Distribution Training
- Cloud Support
- Open Source + Great Community
- Works with GPUs
- Production Ready
Caffe: Caffe is a deep learning framework made with expression, speed, and modularity in mind. It is developed by Berkeley AI Research (BAIR) and by community contributors.
Highlights:
- Open Source + Great Community
- C++ Based
- Expressive Architecture
- Easy and Faster Execution
EmguCV: Emgu CV is a cross-platform .Net wrapper to the OpenCV image processing library.
Highlights:
- Open Source and Cross-Platform
- Working with .NET compatible languages – C #, VB, VC ++, IronPython, etc.
- Compatible with Visual Studio, Xamarin Studio and Unity
MATLAB Image Processing Toolbox: Image Processing Toolbox apps let you automate common image processing workflows. You can interactively segment image data, compare image registration techniques, and batch-process large data sets.
Highlights:
- Wide range of Deep Learning Image Processing Techniques
- CUDA Enabled
- 3D Image Processing Workflows
WebGazer: WebGrazer is a JS-based library for eye tracking that uses standard webcams to infer the eye-gaze locations of web visitors on a page in real-time.
Highlights:
- Multiple gaze prediction models
- Continually supported and Open Source for 4+ years
- No special hardware; WebGazer.js uses your webcam
Apache Marvin-AI: Marvin-AI is an open-source AI platform that helps deliver complex solutions supported by a high-scale, low-latency, language-agnostic and standardized architecture while simplifying exploitation and modelling.
Highlights:
- Open Source and Well documented
- Easy to use CLI
- Multi-threaded image processing
- Feature extraction from image components
MIScnn: An open-source deep-learning-based framework for Medical Image Segmentation.
Highlights:
- Open Source and Well Documented
- Creation of segmentation pipelines
- Decently pre-processing and post-processing tools
- CNN Implementation
Kornia: PyTorch based open-source differentiable computer vision library.
Highlights:
- Rich and low-level image processing techniques
- Open Source and Great Community
- Differentiable programming for large applications
- Production Ready, JIT Enabled
VXL: VXL (the Vision-something-Libraries) is a collection of C++ libraries designed for computer vision research and implementation.
Highlights:
- Open Source
- 3D Image Processing Workflows
- Designing a graphical user interface
Deep Learning Image Processing
Today, several machine learning image processing techniques leverage deep learning networks. These are a special kind of framework that imitates the human brain to learn from data and make models. One familiar neural network architecture that made a significant breakthrough on image data is Convolution Neural Networks, also called CNNs. Now let’s look at how CNNs are utilised on images with different image processing tasks to build state of the art models.
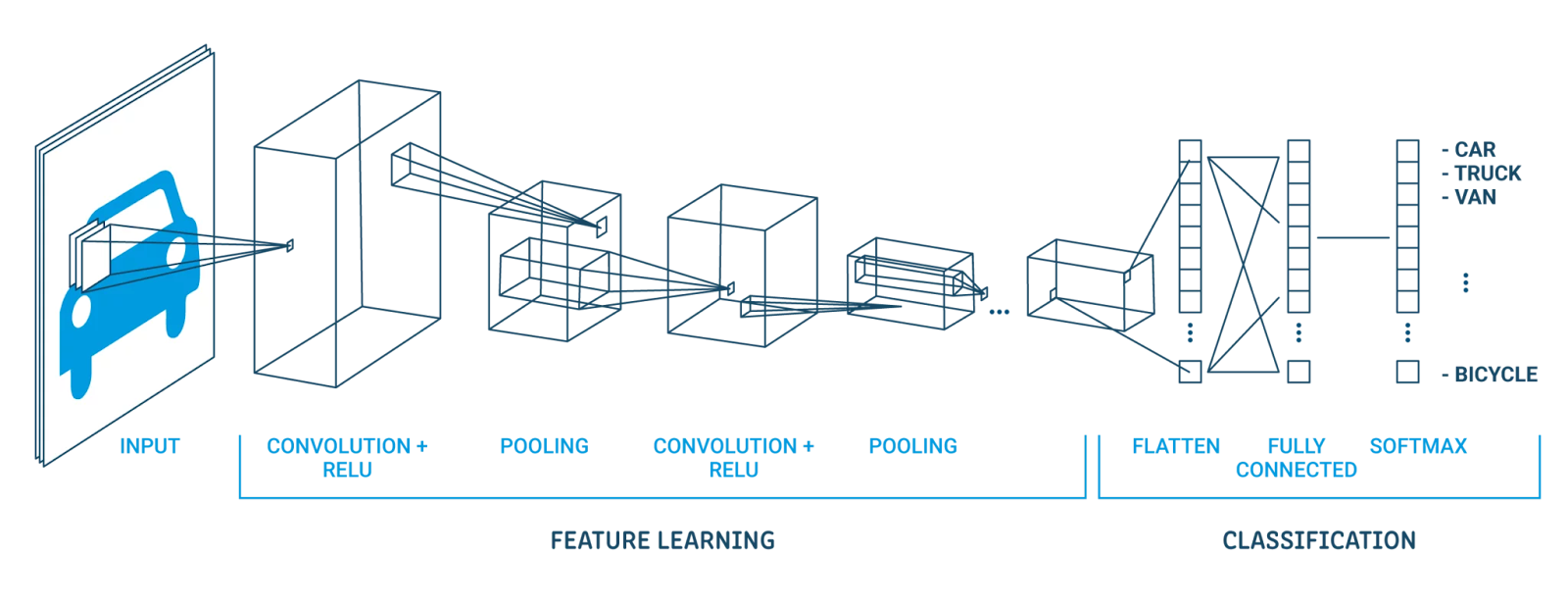
The convolutional neural network is built on three primary layers, which are:
- Convolutional Layer
- Pooling Layer
- Fully Connected Layer
Convolutional Layer: The convolutional layer is the heart of CNN’s, it does most of the work in identifying the features in the given image. Then in the convolution layer, we consider square blocks of some random size of the input image and apply the dot product with the filter(random filter size). If the two matrices(the patch and the filter) have high values in the same positions, the convolution layer output will be high(which gives the bright side of the image). If they don’t, it will be low(the dark side of the image). In this way, a single value of the output of the dot product can tell us whether the pixel pattern in the underlying image matches the pixel pattern expressed by our filter.
Let’s review this via an example, where we want to apply a filter to detect vertical edges from an image using convolution and see how the math works.

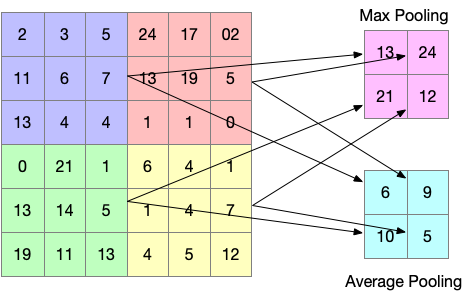
Pooling Layer: When we identify the features using the convolutional layers, we have multiple feature maps. These feature maps result when the convolutional operation is applied between the input image and the filter. Hence we need one more operation which downsamples the image. Hence to make the learning process easy for the network, the pixel values in the arrays are reduced by using the “pooling” operation. They operate autonomously on every depth slice of the input and resize it spatially, using the two different operations:
- Max Pooling – returns the maximum value from the array of the image covered by the Kernel
- Average Pooling – returns the average of all the values from the array of the image covered by the Kernel.
Below is an example of how a pooling operation is computed on the given pixel array.
Fully Connected Layer: The fully connected layer (FC) operates on a flattened input where each input is connected to all the neurons. These are usually used at the end of the network to connect the hidden layers to the output layer, which help in optimizing the class scores.
Here’s a screenshot of the entire CNN architecture of all three layers together:
Conclusion
In this blog, we’ve seen how machine learning and deep learning image processing techniques help build high-performing models at scale. We’ve reviewed some of the most familiar Python, C++, C# open source libraries that we can utilise for building Ml Image Processing pipelines to pre-process, analyse and extract information from the images. Lastly, we’ve reviewed CNNs, one of the most loved deep learning image processing architectures, to build state-of-the-art models on image data. These had a wide range of applications that include classification, segmentation, information extraction, style transfer and many more.
[ad_2]
Source link