
[ad_1]
Want to extract information from PDF documents and convert/add them into a Google Sheets document? Check out Nanonets™ PDF to Google Sheets converter for free and automate export of any information from any PDF document into Google Sheets!
Do you know how successful businesses are able to improve their profits with ease? Turns out, it all boils down to one factor: Automation! If your business can automate processes, you can take your mind off peripheral tasks and focus on making those crucial business decisions.
In this blogpost, let’s run through an example of how your organization can automate the process of extracting data from PDF documents and converting them into a Google Sheets document.

Before we look at how we can convert PDF documents to Google Sheets, let’s take a look at why it’s important to do this.
According to this Google blog post from the official Google blog page, more than 5 million businesses are using their G Suite solution. At the same time, a large number of companies have also started using Google Sheets integrations to automate tasks.
Let’s consider a typical use case. Your Accounts Payable team receives an invoice, in the standard PDF format. Someone manually goes through the invoice and keys in the required information into a Google Sheets document before forwarding it to the Finance section. The Finance section pays your supplier and makes an entry in the company’s ledger.
Apart from being a long drawn out process, this is error prone and it would make much more sense to simply automate it.
Now that the need for converting PDFs to a Google sheet form is clear, let’s take a look at how PDF documents are structured and what the challenges are in parsing them.
Want to extract information from PDF documents and convert/add them into a Google Sheets document? Check out Nanonets™ to automate export of any information from any PDF document into Google Sheets!

The portable document format was a file format initially developed by Adobe and was later released as an open standard. It has since been widely adopted as it is agnostic to the underlying operating system.
So, why is it so challenging to parse a PDF and convert its contents to another format? The following images speak a thousand words and will drive the point home.

The above image shows the screenshot of a PDF document which is opened using a PDF reader. Let’s try opening the same PDF document using a text editor.
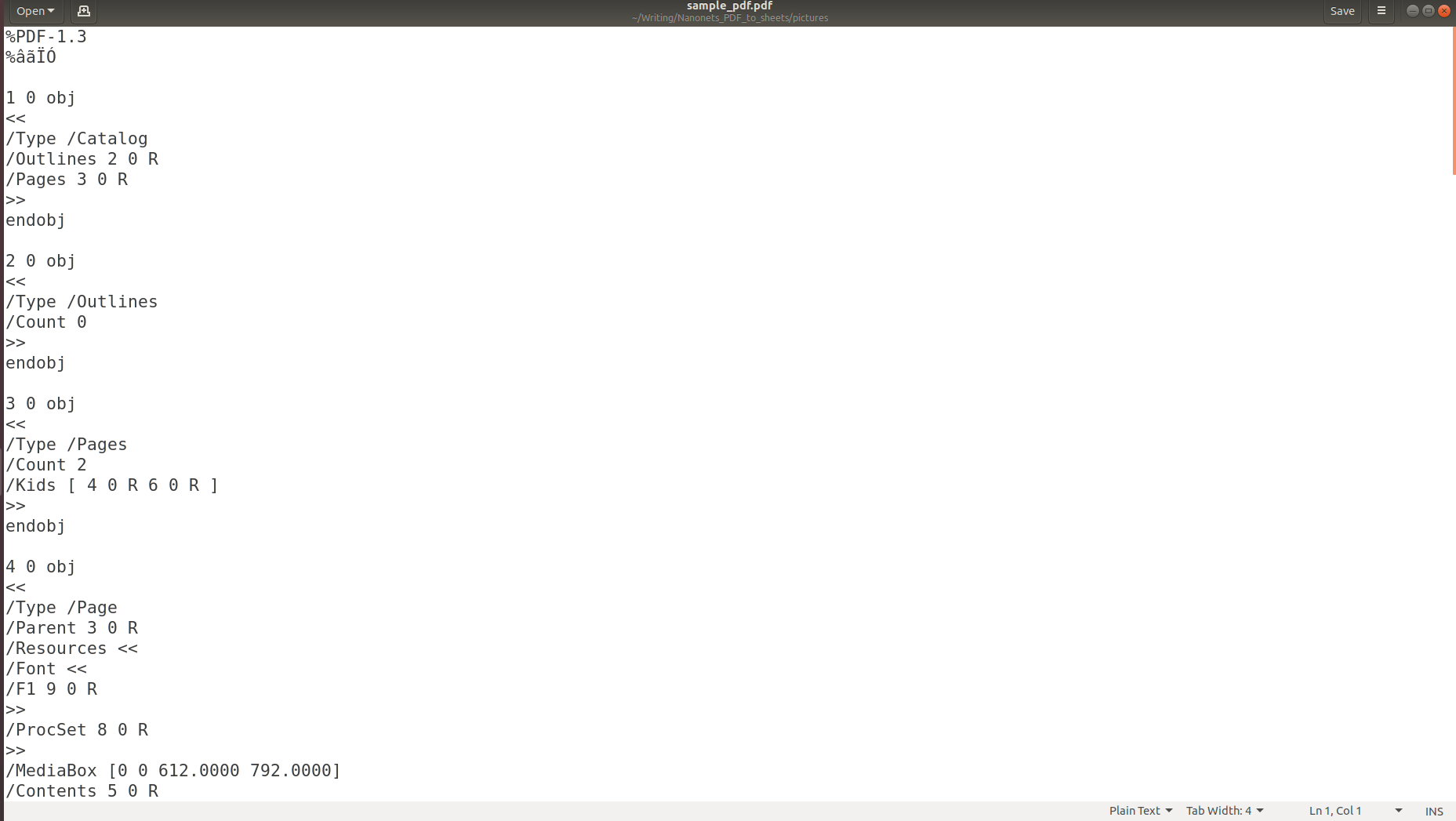
The above pictures make it clear that when information is stored in a PDF, its original structure is completely lost. This is because the PDF format simply consists of instructions on how to print/draw a sequence of characters on a page.
If you think that text extraction is difficult, extracting the data present in tables is even more challenging owing to widely varying tabular formats which are used.
Hopefully, you are convinced that converting a PDF document into a Google Sheets form is no walk in the park. The next section talks about the approach taken by most modern PDF parsers to recognize/parse information from a PDF document.
Most modern PDF parsers make use of the flow described below to parse unstructured data from PDF documents.
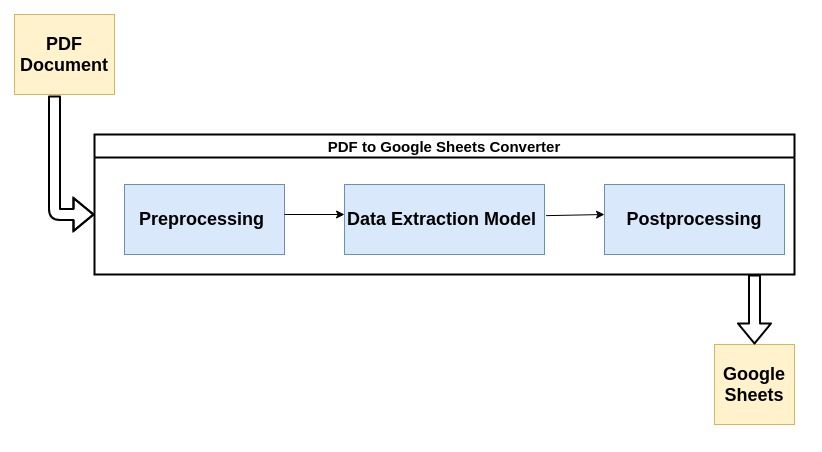
Let’s briefly take a look at each step of the process:
1. Preprocessing or Data Cleaning:

The better your PDF looks, the easier it will be for your Machine Learning model to extract data from it. For example, if the PDF document has been scanned, it is bound to contain some scan artifacts which could affect the performance of the converter.
Noise removal by using appropriate filters, binarization, skew correction etc are some of the most common preprocessing steps. The following Nanonets post Nanonets Tesseract Post contains some great examples of how documents can be preprocessed before Optical Character Recognition(OCR) is run on them.
This is where most of the magic happens. Data extraction is usually carried out by a Machine Learning(ML) model. Most ML models used for data extraction from PDFs contain a combination of optical character recognition tools, text and pattern recognition tools etc.
For the purpose of this post, we can treat the model as a black box which takes your PDF document as an input and spits out the parsed information. Also, since it employs ML at its core, it can be retrained with custom data to fit your company’s use case.
3. Post Processing:
In this step, the extracted data is converted into the required format such as CSV, XML, JSON etc,. Also, additional user-defined rules are added on top of the predictions made by AI. This could include rules for formatting the output, additional constraints on information that is extracted etc.
The following section looks at some metrics that we could use to measure the performance of a PDF parser.
Want to extract information from PDF documents and convert/add them into a Google Sheets document? Check out Nanonets™ to automate export of any information from any PDF document into Google Sheets!
Since most PDF converters will be used for invoice processing or related tasks, the accuracy and speed of table extraction from a PDF document is a critical factor in judging the performance of the PDF converter.
2. Multilingual Capability:
Most large companies are bound to receive invoices in a number of different languages. The PDF parser should either support multilingual parsing out of the box or it should provide an option by which users can train the model using custom data.
3. Integration with Accounting Software:
The ideal PDF converter should be a plug and play module that can easily be added to your existing workflow. It should support integration with popular accounting software such as QuickBooks, Xero, Wave etc.
4. Easy and Intuitive:
The tool will most likely be operated by non-technical users. It would be advantageous if it can be operated with minimal technical knowledge.
1.Directly Using Google Drive:
Google Drive has some in-built capability to recognize tables and text within PDF documents. You simply need to upload your PDF file to your Google Drive account and open it using Google docs.
If the layout of your PDF document is simple, Google docs does a good job of recognizing the data in the document and parsing it.
The following picture is a screenshot of a simple PDF document opened using the default PDF viewer in google drive.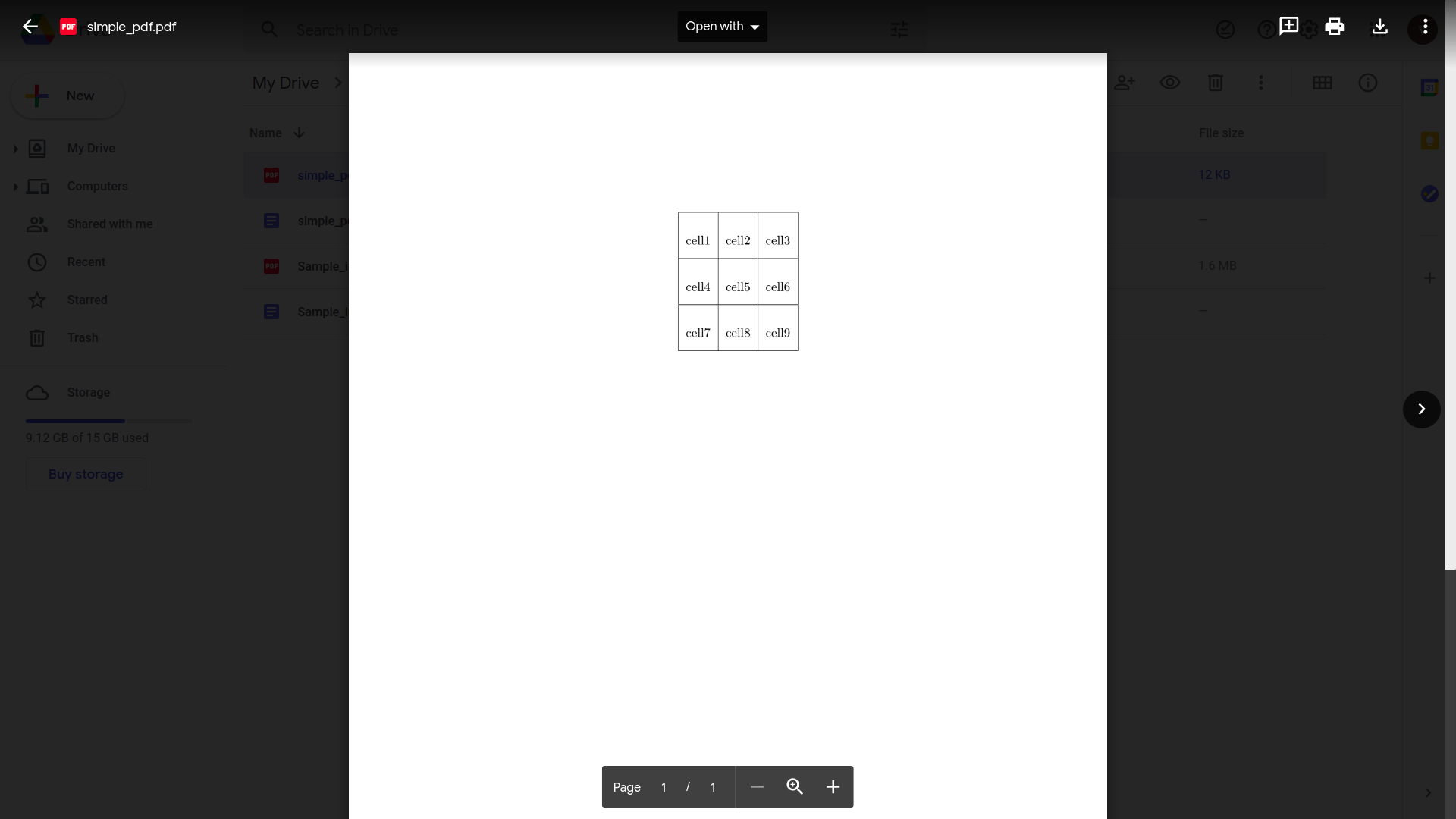
The same document can be opened from google drive using the google docs application. The following figure illustrates this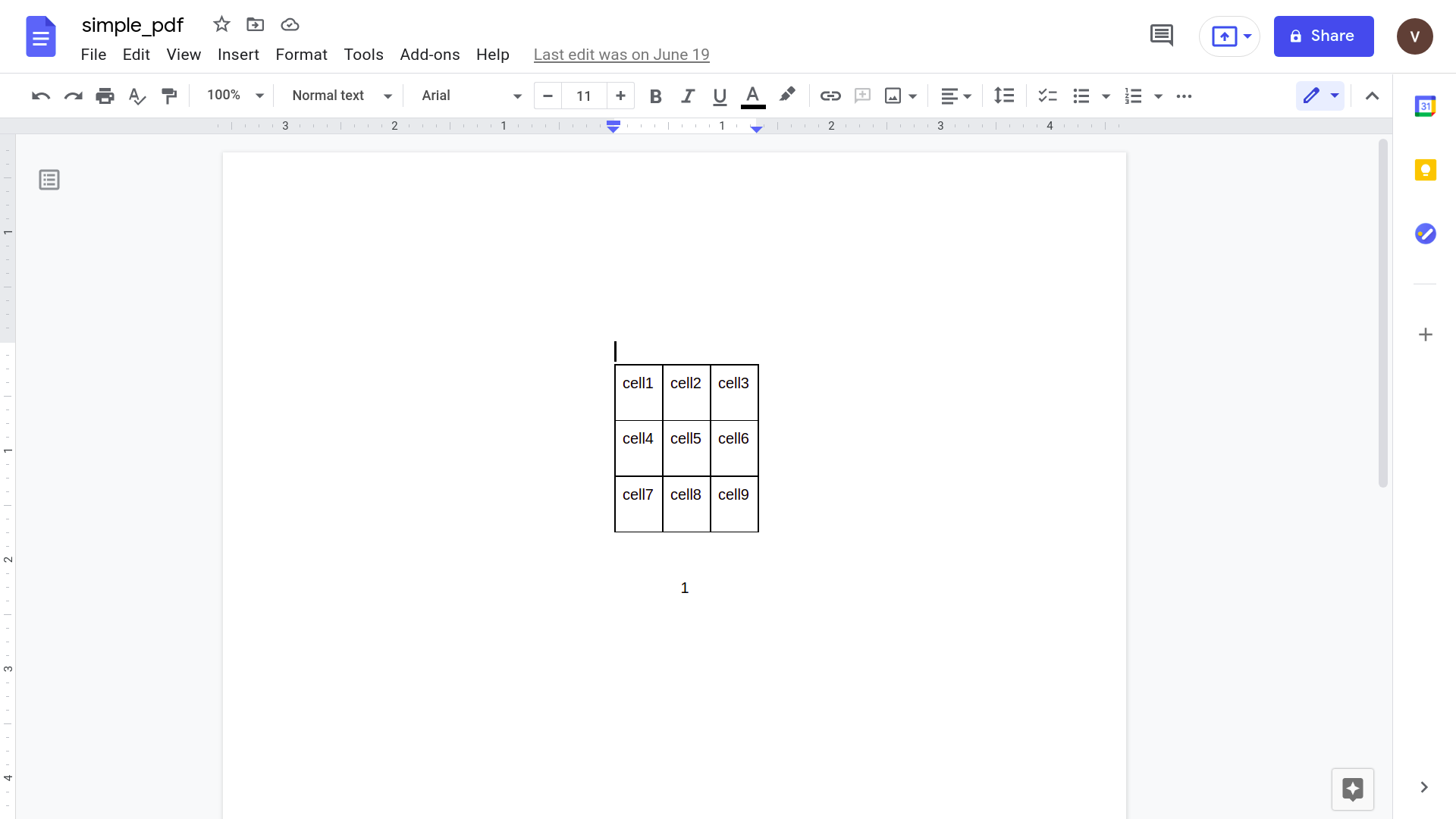
Finally, the table can be selected and pasted into a Google Sheets form.
Although that seems to work well, let’s try something a bit more practical. Consider this simple invoice that has to be parsed.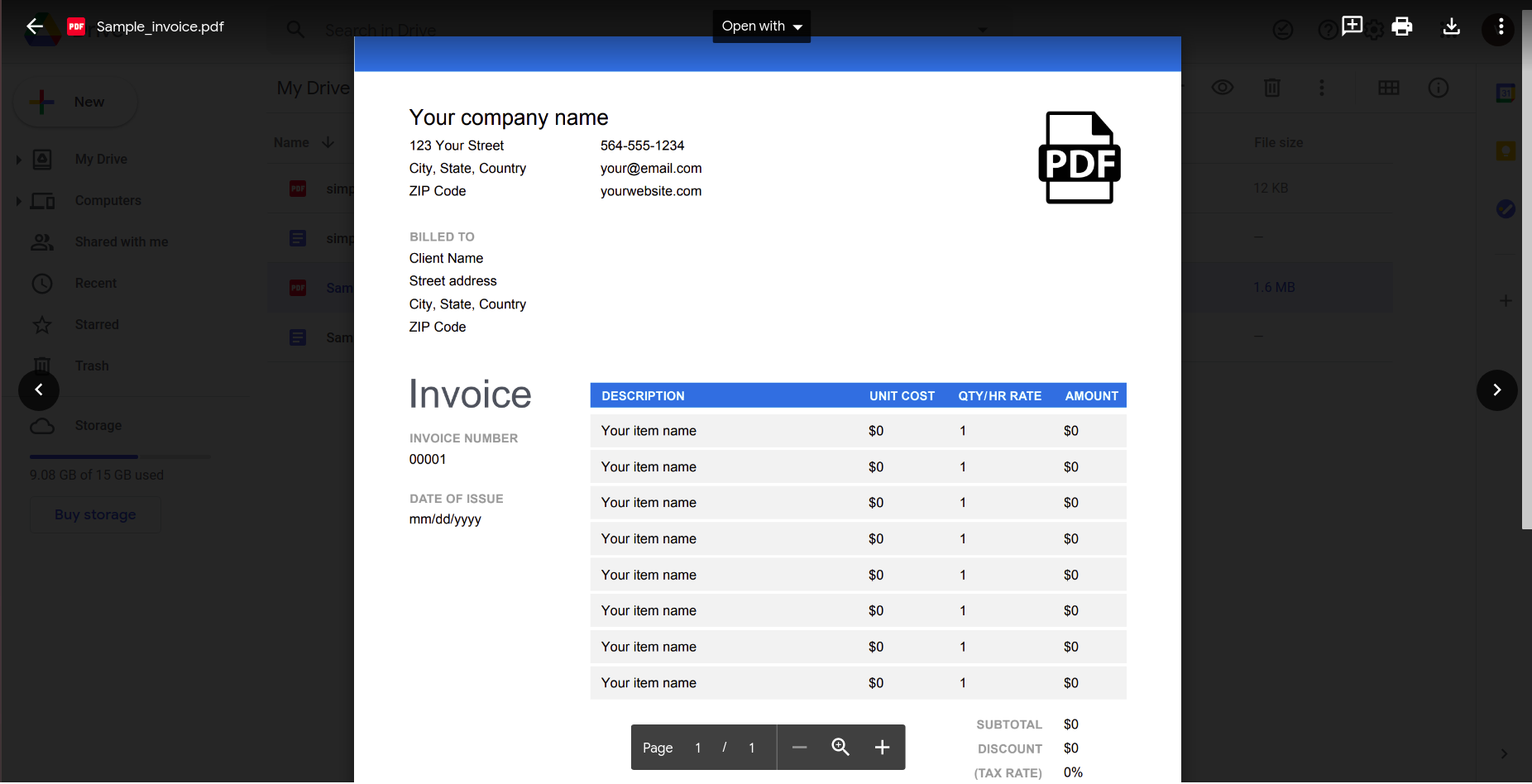
Opening this using the Google docs application gives the following result.
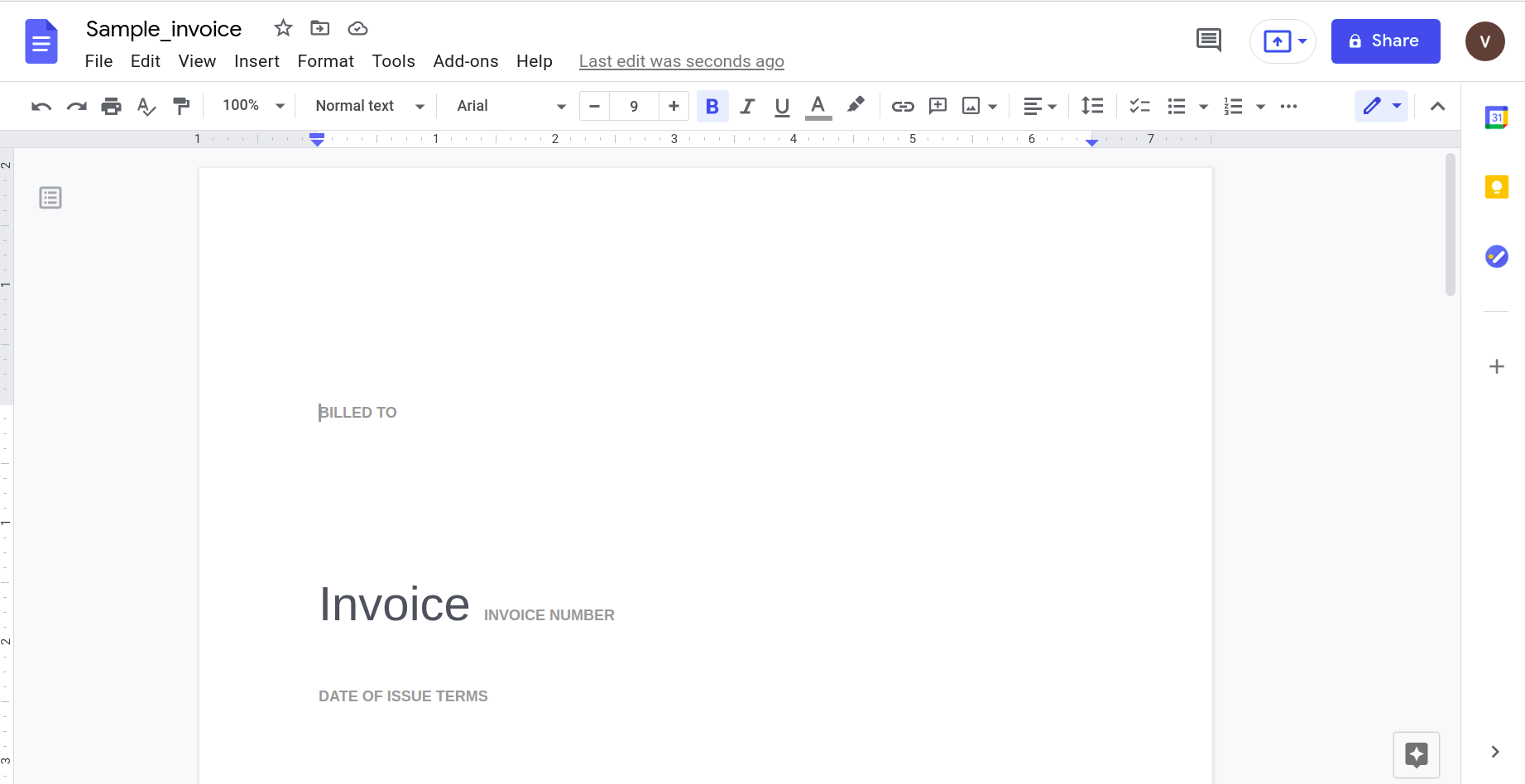
Clearly, as the complexity of the problem increases, we need to rely on more sophisticated tools for parsing.
2. Using Online tools:
Several online tools such as PDF tables extractor, Online2PDF etc, directly integrate with Google Drive and provide out of the box capability to convert PDF documents to Google Sheets. However, when these tools were tested using the sample invoice PDF shown above, the tables weren’t detected in majority of the cases.
Want to extract information from PDF documents and convert/add them into a Google Sheets document? Check out Nanonets™ to automate export of any information from any PDF document into Google Sheets!
We can completely automate the process of parsing the PDF and extracting the data into a Google Sheets form by using the following tools.
1. Using Webhooks:
Webhooks are custom defined HTTP requests. They are usually triggered on an event i.e. when an event occurs, the application sends information to a predefined URL.
How can you use this for automating your workflow? Let’s consider the typical use case of invoice processing. You receive a number of invoices from your suppliers and feed them into your PDF to Google Sheets converter which resides on the cloud. How do you know when the model has finished processing the documents?
Instead of manually checking if the conversion has been completed, you could simply make use of a webhook that notifies you when the data in the PDF has been extracted to a Google Sheets document.
2. Using APIs
API stands for Application Programming Interface. Using the appropriate API calls, converting PDF documents to Google Sheets might turn out to be as easy as writing the following lines of code:
#Feed the PDF documents into the PDF to Google sheets converter
Success_code, unique_id = NanonetsAPI.uploaddata(PDF_documents)
If your company has already setup the integration with Webhooks, you will receive a notification when your PDF documents have been converted successfully. You can then download the Google Sheets form using the API shown below.
#Download Google Sheets forms
Google_sheets_data = NanonetsAPI.downloaddata(unqiue_id)
The Nanonets PDF parser makes parsing and conversion easy and accurate. The PDF parser was used to parse a sample invoice. This section demonstrates the easy of use and the accuracy of the tool. Rather than talking about how great it is, the following images aptly illustrate the point.
The image shown below is a screenshot of the sample invoice which was fed to the Nanonets PDF parser.
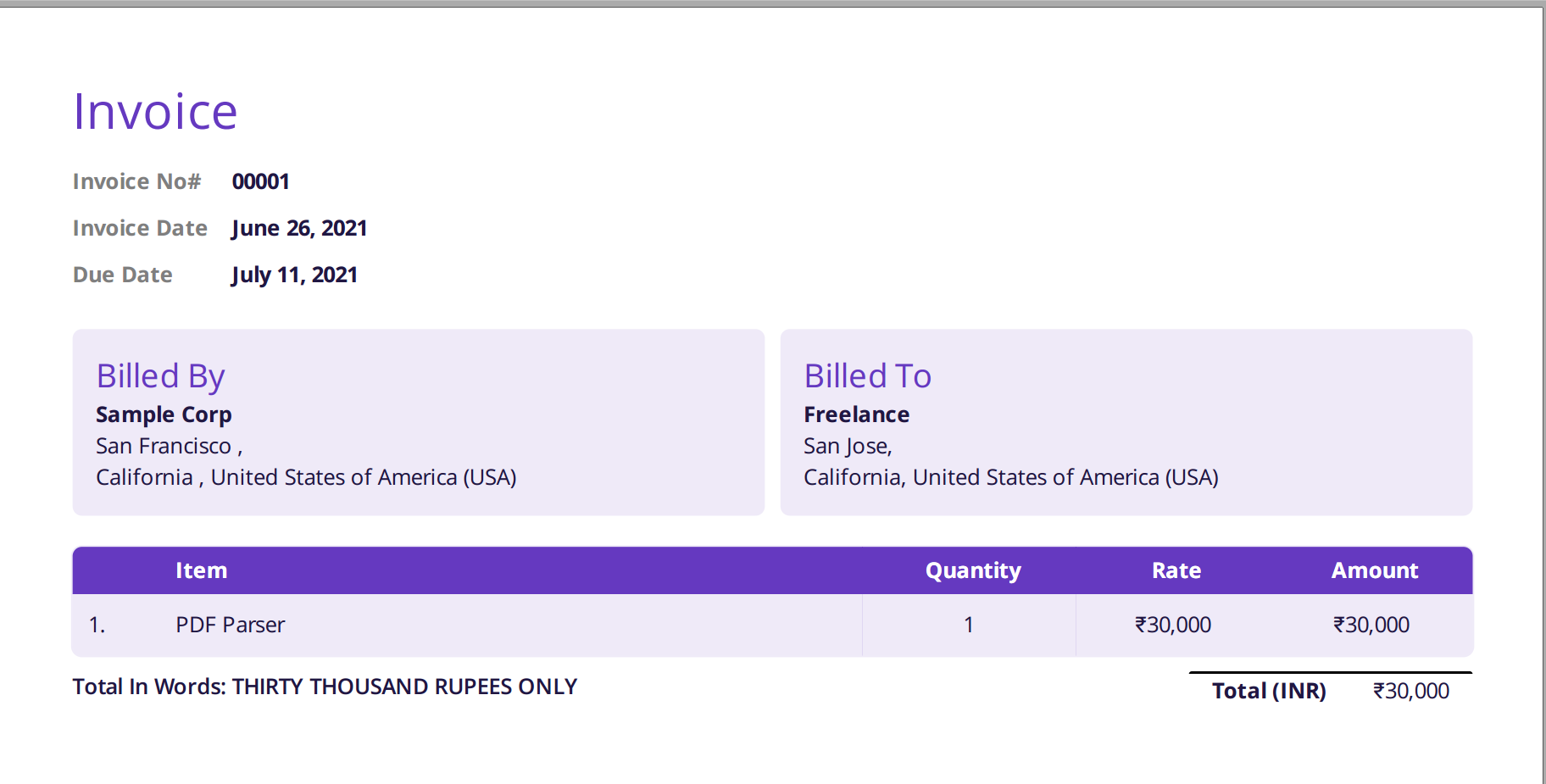
Simply navigate to the Nanonets website and upload the invoice. Conversion takes only a few seconds following which the parsed data can be download in a variety of formats such as CSV, XLSX etc.
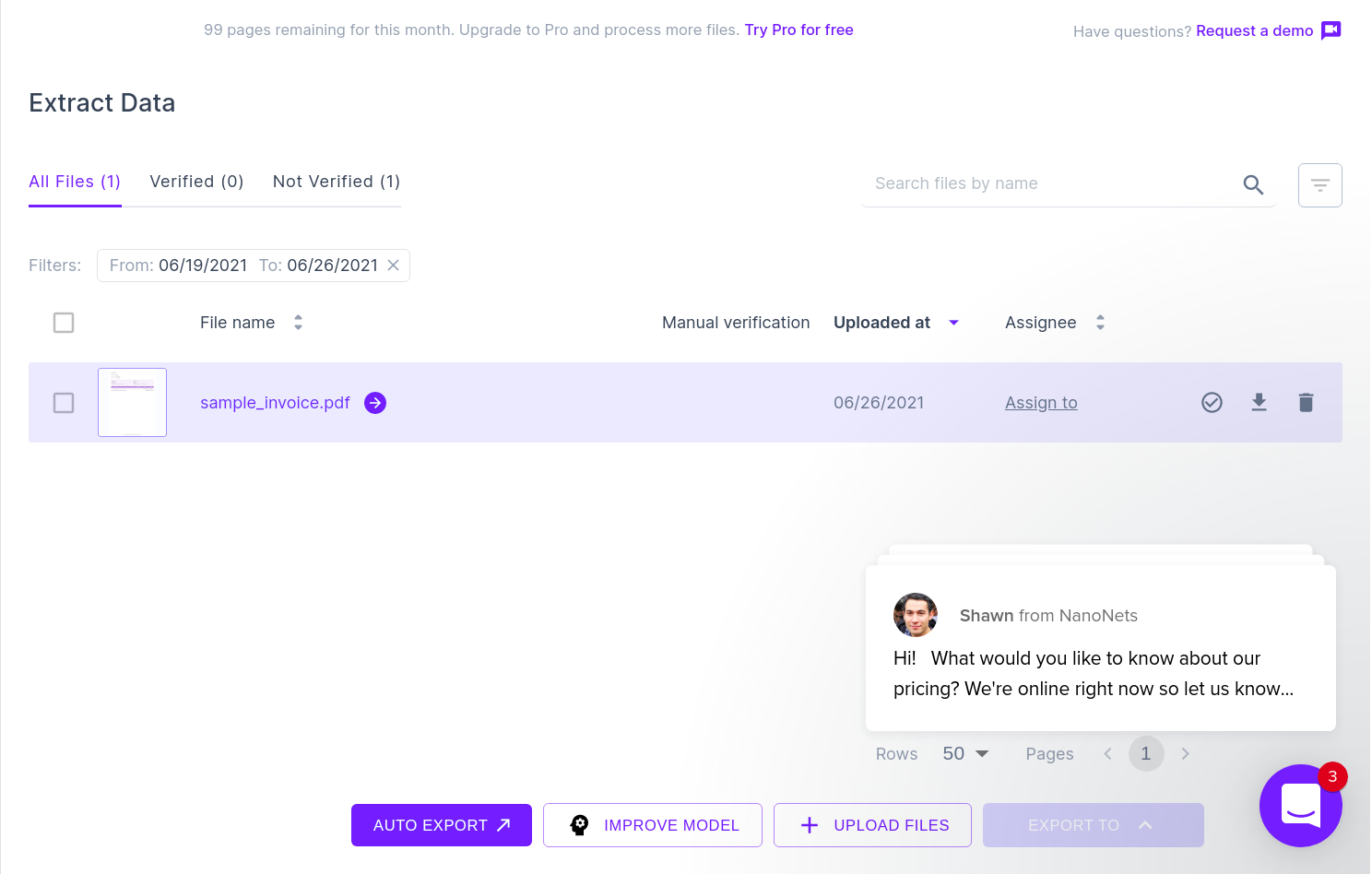
The next image shows a screenshot of the CSV file that contains the parsed data from the PDF document.

Finally, to convert the CSV file to a google sheets form, it’s simply a matter of uploading the XLSX/CSV file into your google drive. This step can be automated by making use of Google drive APIs.
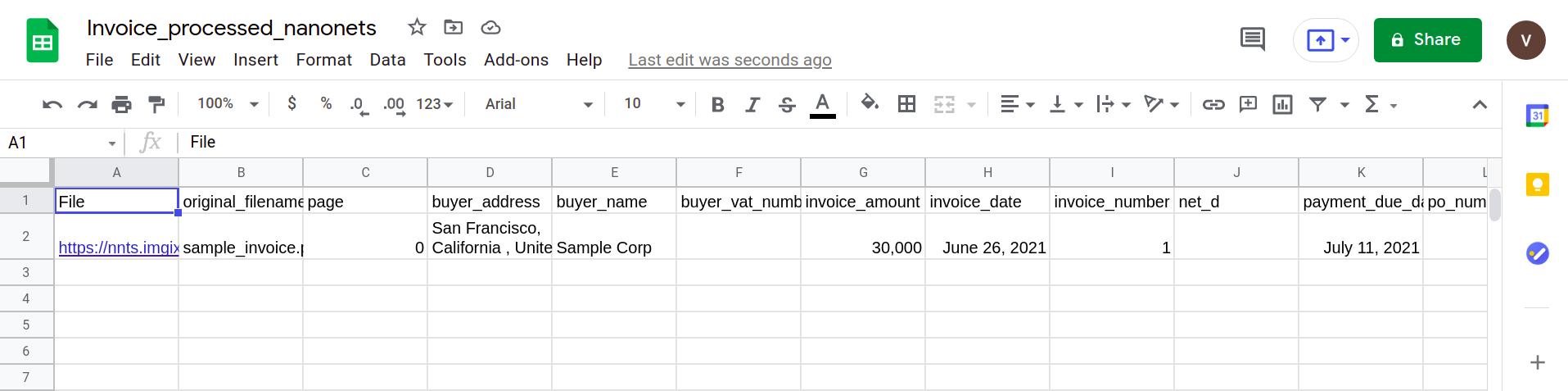
The following section shows how a simple pipeline can be created by making use of the Nanonets PDF parser.
Want to extract information from PDF documents and convert/add them into a Google Sheets document? Check out Nanonets™ to automate export of any information from any PDF document into Google Sheets!
1. Automatically upload your PDF documents using the Nanonets API
The Nanonets API allows you to automatically upload your documents which have to be parsed. The following code snippet shows how this can be done using python.
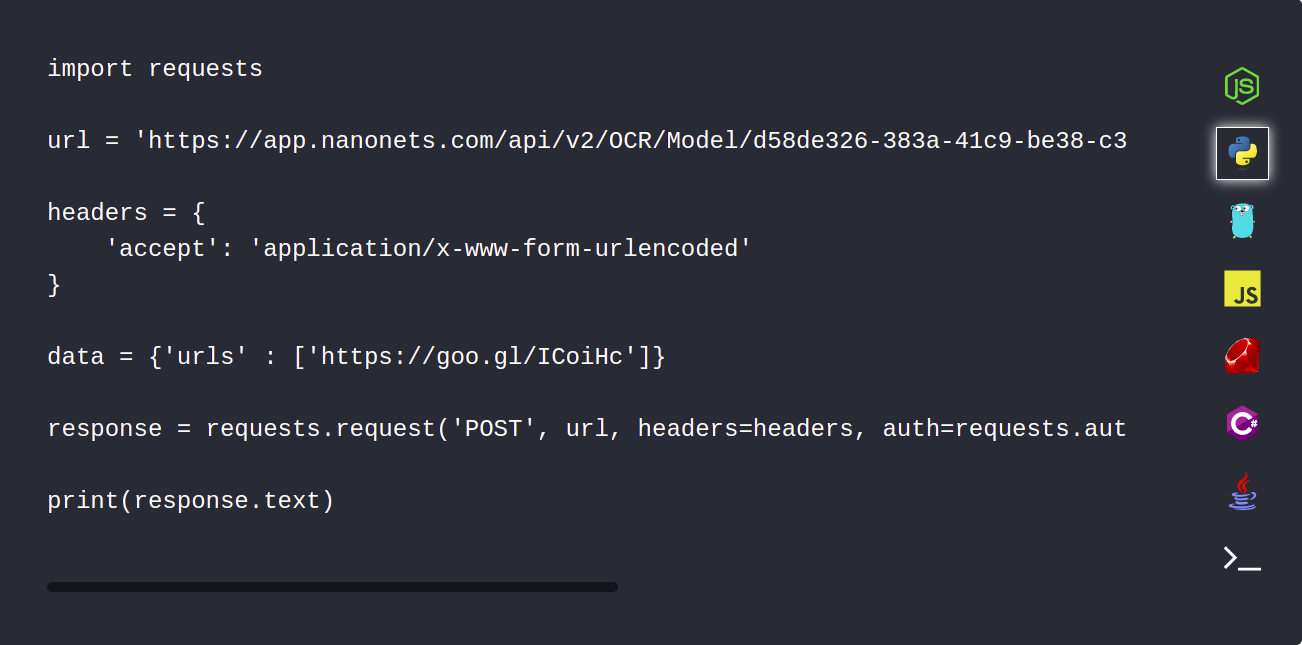
2. Use webhooks integration to receive a notification upon completion of parsing
Webhooks can be configured to automatically notify you once the documents have been parsed.
3. Review and upload to Google Sheets
Download and review the CSV files to make sure that everything is in order and upload the data to Google Sheets using the Google drive API.
Here are some features of the Nanonets PDF Parser that makes it the ideal tool for your business.
1.External Integrations:
The nanonets model can easily be integrated with MySql, Quickbooks, Salesforce etc. This means that your current workflow remains undisturbed and the nanonets converter can simply be plugged in as an additional module.
2. High Accuracy and Low Processing Times:
The Nanonets PDF parser tool has an accuracy of over 95%+ which is much higher when compared to its competitors.
3. Cool Post-processing Features:
Assume that your database has been integrated with the the nanonets model. The model automatically fills in some fields (with data from your database) based on the data extracted from the document. For example:
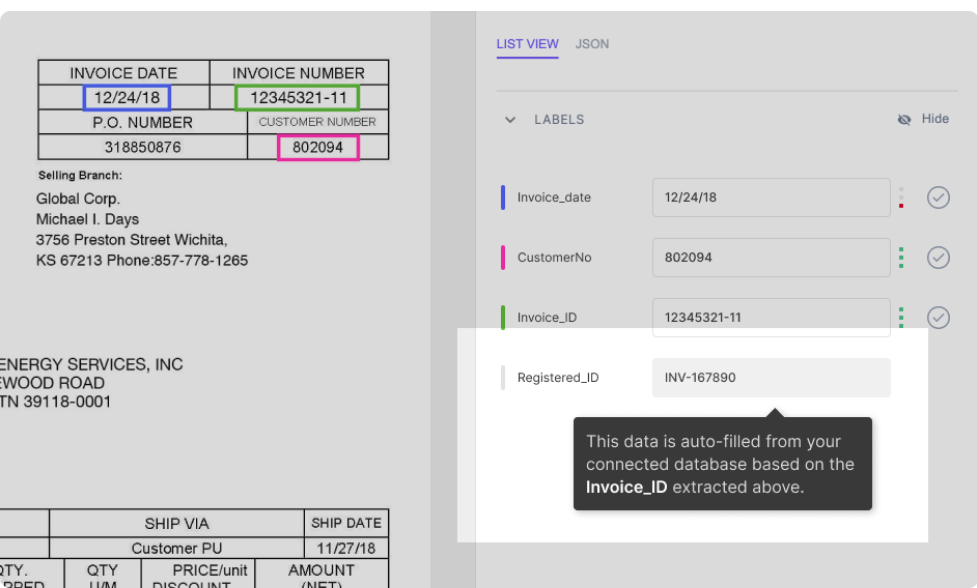
As shown in the figure, the Registered_ID field is filled automatically (by a database lookup) based on the Invoice_ID that is extracted from the PDF.
4. Simple and Intuitive Interface
While this feature is underrated, I found the UI and UX to be spot on. The entire process of signing up, uploading the document and parsing the data took less than 5 minutes. That’s almost equal to the time my laptop takes to boot up!
5. Huge Customer Base
In case you still have reservations about using Nanonets for automating your workflow, just take a look at some of the companies that use their services.
- Deloitte
- Sherwin Williams
- DoorDash
- P&G
Want to extract information from PDF documents and convert/add them into a Google Sheets document? Check out Nanonets™ to automate export of any information from any PDF document into Google Sheets!

In this post we took a look at how you can automate your workflow by using a PDF to Google Sheets converter. Initially, we learned about the need for converting PDF documents to Google Sheets followed by the challenges faced during this process. We then dived into the approaches taken by modern parsers for parsing PDF documents and also implemented some of the common approaches. We also learned how we can completely automate the conversion using external integrations such as webhooks and APIs. Finally we used the Nanonets tool for parsing a sample invoice, extracting the data into a Google Sheets form and also explored some of its cool post-processing features.
Have you given the Nanonets model a shot? If so, please leave a comment below regarding your experience with the tool. If not, go ahead and try it out. It might just make your day!
[ad_2]
Source link