
[ad_1]
Introduction
Optical Character Recognition (OCR), the method of converting handwritten/printed texts into machine-encoded text, has always been a major area of research in computer vision due to its numerous applications across various domains — Banks use OCR to compare statements; Governments use OCR for survey feedback collections.

Due to the diversity in handwriting and printed text styles, recent approaches of OCR incorporate deep learnings to gain a higher accuracy. As deep learning requires vast quantities of data for model training, companies like Google take an edge in producing promising results with their OCR services.
This article dives into the details of the Google Cloud Vision OCR, including a simple tutorial in python, the range of applications, pricing, and other alternatives.
What is Google Cloud Vision?

Google Cloud Vision OCR is part of the Google cloud vision API to extract text from images. Specifically, there are two annotations to help with the character recognition:
- Text_Annotation: It extracts and outputs machine-encoded texts from any image (e.g., photos of street views or sceneries). Since it was initially designed to be usable under different lighting situations, the model is in some sense more robust in reading words of different styles, but only at a more sparse level. The JSON file returned includes the entire strings as well as the individual words and their corresponding bounding boxes.
- Document_Text_Annotation: This is particularly designed for densely-presented text documents (e.g., scanned books). Thus, while it supports reading smaller and more concentrated texts, it is less adaptable to in-the-wild images. Information such as paragraphs, blocks, and breaks are included in the output JSON file.
A Simple Tutorial
The following section introduces a simple tutorial in getting started with Google Vision API, particularly on how to use it for the Google Cloud Vision OCR service.
Simple Overview
The idea behind this is very intuitive and simple.
1) You essentially send an image (remote or from your local storage) to the Google Cloud Vision API.
2) The image is processed remotely on Google Cloud and produces the corresponding JSON formats with respect to the function you called.
3) The JSON file is returned as the output after the function is called.

Setting up Google Cloud Vision API
To use any services provided by the Google Vision API, one must configure the Google Cloud Console and perform a series of steps for authentication. The following is a step-by-step overview of how to set up the entire Vision API service.
- Create a Project in Google Cloud Console — A project needs to be created in order to begin using any Vision service. The project organizes resources such as collaborators, APIs, and pricing information.
- Enable Billing — To enable the vision API, you must first enable billing for your project. The details of pricing will be addressed in later sections.
- Enable Vision API
- Create Service Account — Create a service account and link to the project created, then create a service account key. The key will be output and downloaded as a JSON file onto your computer.
- Set Up Environment Variable GOOGLE_APPLICATION_CREDENTIALS: To set up this environment variable, run this on Mac/Linux or Windows:
- Code blocks for Mac/Linux
- Code blocks for Windows
A more detailed procedure of the aforementioned steps can be found from the official documentation given by Google Cloud from here:
https://cloud.google.com/vision/docs/quickstart-client-libraries
Simple Google Vision OCR Function in Python
The Google Cloud Vision API works with numerous popular languages, ranging from Java, Node.js, Python, to Google’s own language Go. For simplicity, we introduce a simple calling method in Python.
def detect_text(path):
"""Detects text in the file."""
from google.cloud import vision
import io
client = vision.ImageAnnotatorClient()
with io.open(path, 'rb') as image_file:
content = image_file.read()
image = vision.Image(content=content)
response = client.text_detection(image=image)
texts = response.text_annotations
print('Texts:')
for text in texts:
print('n"{}"'.format(text.description))
vertices = (['({},{})'.format(vertex.x, vertex.y)
for vertex in text.bounding_poly.vertices])
print('bounds: {}'.format(','.join(vertices)))
In other words, the method consequently calls the function text_annotation, then further extract the responses and print the information out. document_text_annotation can also be called using the same way to retrieve dense texts. One can also detect images remotely by setting the image via :
image.source.image_uri = uriwhere the uri is the image’s uri.
More details of the codes can be retrieved here:
https://cloud.google.com/vision
Level of Output Offered
To assist in further data analysis of the text, the two Google OCR functions provide various levels of output for users to use: for text_annotation, both the entire strings (if considered by Google as one sentence or phrase) and the individual words within; for document_text_annotation, as the model is optimized for dense text, page, block, paragraph, word, and break are all offered as a part of the output.
How well does it work though?
How robust are the models?
As mentioned previously, Google offers two functions for OCR in two different situations. The following describes the capability of two functions in retrieving different types of data.
Printed Data
The easiest type of data to interpret is printed text data, i.e., computer-written text printed and scanned. OCR is required when we only have the printed copy of these data instead of the original machine-encoded texts. As most of these texts are tight and packed in pages, document_text_annotation would be a better option.
Hand-written Data
Content may contain handw-written text and styles of hand-written data can vary drastically. Nevertheless, Google Vision OCR provides decent accuracy as long as the handwritten notes are not too messy. Depending on how packed the medium of the hand-written data is presented, we use one of the two functions on a case-to-case basis.
Rotated/In-The-Wild Data
When the images or the scanned photos are presented in unorthodox or unaligned angles, we consider them as in-the-wild data. Texts could potentially be more difficult to be detected in the first place, and hence we usually use the text_annotation function which was designed to process in-the-wild data in the first place. Based on some experiments of passing through vertical texts and road signs captured at different angles, we show that Google Vision OCR actually performs decently on data from various environments.
Why OCR?
Many of the data we have today is in unstructured format. For instance, given an image, a scanned document, or a photograph, while humans can quickly recognize the texts and further interpret meanings, all the text data are merely pixels with colors, providing no real meaning to machines.

When companies or large corporations are dealing with massive amounts of paperwork, the large data volume would make it impossible for any classifications or data processing to be done with solely human effort — this is when machine-encoded text becomes handy.
After OCR conversion, information can then be analyzed with multiple different methods depending on the nature of the data:
- For numerical data, statistical methods could be directly applied to analyze for any correlations. We could also adopt traditional machine learning methods (e.g., KNN, K-Means, Linear Regression) or deep learning approaches to create predictive models for regression and/or classification.
- For text data, more stages of processing may be required. The process of analyzing and interpreting text data into meaningful statistics is often referred to as natural language processing (NLP). Specifically, we could extract numbers or even semantics/atmosphere based on given content.
All these analyses could allow companies, especially the ones with vast amounts of new data every day, to create robust models and even automate a lot of processes and replace the traditional labor-intensive and error-packed approaches. The following section digs into some detailed examples of how OCR can be used.
Example Use Cases
License Plate Reading

Perhaps one of the most common usages of OCR nowadays is the application in license plate reading. In developed countries, parking lots are often accompanied by license plate reading models to determine the entry time, exit time, and even the exact parked location per car. Some parking lots are even connected to the governmental network to charge the parking fees directly to families — all of which alleviates redundant human efforts.
The license plate OCR models can also be adopted for detections in traffic violations, easing the time for police to manually key in the data of the violating car.
Receipt and Invoice Scanning

Financial projections and balancing the assets and liabilities of companies are important activities for any firm. As large companies make large-quantity purchases from multiple sectors throughout the year, they’re required to meticulously gather and process all the invoices and receipts when creating financial statements.
With the help of OCR, we can create automated pipelines that recognize a number of invoice formats and convert them into numbers. Labor efforts are only required for checking, and the structured data and numbers can allow the company to quickly balance out the inflows and outflows, create financial projections, as well as watch out for any malicious manipulations of the company’s finances.
Electrical Medical Records

Patients’ data are often scattered around a region, country, or even across countries depending on the lifestyle of the individuals. Due to the different styles of clinics and hospitals (large hospitals may have organized databases while doctors in smaller clinics may just write down the records by hand), age of patients (older patients may be inserted into a particular database before the renovation and incorporation of computers), and the locations of individuals (people may move to a different city or even abroad), keeping a universal medical may actually be very difficult.
A well-trained OCR thus becomes handy when transferring the EMR from one hospital to another, or transforming hand-written data into machine text — both of which can expedite the process of understanding patients’ medical history in a fast and concise manner.
Forms and Surveys

Organizations (whether governmental or non-governmental) may often require feedback from customers or citizens to improve on their current promotional plans and products. Since forms are usually written by hand, it would be potentially difficult to perform any direct statistical analysis. Therefore, the process of converting unstructured data and handwritten surveys into numerical figures to facilitate calculations could be assisted and accelerated by the OCR.
Cloud Vision Pricing
According to the Google website, both text_annotation and document_text_annotation are offered at the same price level as the following:
For every month, the first 1000 units are given free, with the 1000-5000000 charged at $1.5 per 1000 units. After hitting the 5000000 mark, the price decreases to $0.6 per 1000 units (Each image sent via the Google Vision API is considered as one unit).
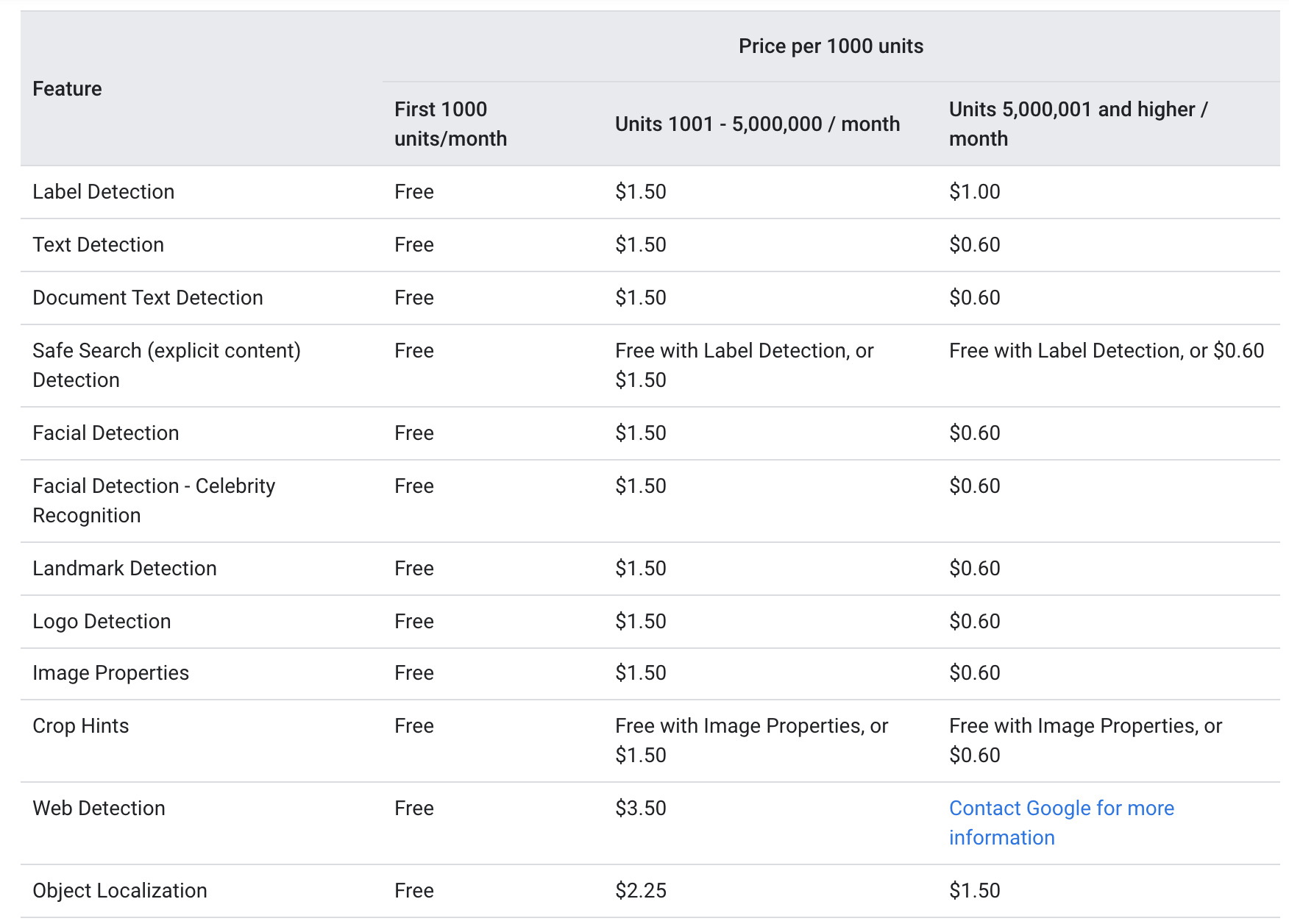
The above pricing suggests that the OCR service is relatively affordable for both small companies with less frequent usages as well as large corporations where the service is required a lot more than 5000000 times per month.
Salient Features of Google Cloud Vision OCR
Google OCR has various benefits, here we describe some of the most significant benefits:
- Robust — The two functions, serving two types of text documents dependent on the users’ decision, make the Google Vision OCR comparatively more robust than single-model OCR engines.
- Language support — With perhaps the largest language database, Google has advised that its OCR is applicable to more than 60 languages, experimenting on a few dozens more, and maps many of the rest to another language code or general language recognizer.
- Ease of use — The model itself is part of the in-built Google Vision library. After the slightly more vexing process of configuring the API key (which is required by almost all OCR engines), the function-calling method can be used in numerous languages in a very straightforward manner.
- Scalability — Google’s pricing strategy encourages users to scale up the usage of the API, as more usage leads to a cheaper average price.
- Speed — Google Cloud’s storage platform wonderfully accompanies the API usage. By uploading the images into the drive, the response time of API can be very fast and scalable.

Alternatives
The following are some alternative OCR services other than the Google Vision API, along with the advantages and disadvantages of each service.
ABBYY
ABBYY FineReader PDF is an OCR developed by ABBYY, which focuses particularly on pdf reading.
- Pros: ABBYY is much more cost-friendly for individual users as the pricing is segmented into smaller sectors (1000, 2000 pages, etc.). It is also directed towards non-engineering customers as it is a commercialized app.
- Cons: The software focuses on PDF format only, and the price becomes very expensive when doing large-scale OCR.
- When to use: For individual users who just want to quickly handle PDFs, ABBYY may be a more viable option than Google Vision API which gives more flexibility but requires extra codes.
Microsoft
Microsoft Azure also offers Read API for OCR.
- Pros: Microsoft provides a cheaper price for an even larger number of data to be used. Azure cloud storage offers similar services as Google Cloud.
- Cons: There’s no free tier, whereas other options provide free API calls for low usage.
- When to use: Very-large-scale OCR production pipelines could be benefit from the Microsoft’s pricing.
Kofax
Similar to ABBYY, Kofax also offers OCR reading of PDFs
- Pros: Price is fixed for individual usage, and discounts are offered for enterprises. 24/7 customer support is also provided.
- Cons: The quality is claimed to be not as high as ABBYY’s.
- When to use: Small enterprises with low usage requirements.
AWS Textract serves a very similar role compared to Google Vision API. Their services and pricing are very similar, and so which one to adopt is completely based on customer preferences.
Nanonets
Unlike the previously discussed services, Nanonets’ OCRs are further categorized into specific categories, with robust models trained on each data type (e.g., receipts, invoices, driving licenses).
- Pros: Category-specific OCRs, hence providing even better results in terms of accuracy when firms require OCR for target-specific applications.
- Cons: The Nanonets OCR may be less applicable to in-the-wild settings due to the highly specific and tailored models
- When to use: If firms require OCR for a specific type of data such as invoices, Nanonets may be a cost-friendly and highly accurate option.
Common Issues with Cloud Vision
In this final section, we aim to address some questions from Stackoverflow regarding the document scanning and OCR
Recognizing documents using neural networks
Link: https://stackoverflow.com/questions/63844251/how-to-detect-and-recognize-information-on-documents-using-neural-networks/63844363#63844363
This is the exact usage of Google OCR! Follow the steps above to scan in documents and perform text retrieval.
Grabbing the Most Important Details after OCR
Link: https://stackoverflow.com/questions/64621684/how-to-parse-name-phone-number-email-from-name-card-after-using-google-cloud-vi
The idea of parsing the most meaningful contents inside any documents is called natural language processing. As every document contains such information in different formats, it would be recommended to adopt some ML approaches to do so. Of course, if all cards are in the same format, rule-based methods to retrieve the texts with certain key characters (e.g., if it contains @ it is an email) should work too.
Can it run offline?
Link: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
Unfortunately, no. The API calls the Google Cloud OCR remotely, and you cannot work offline as the API costs money.
Can it detect if a text is in bold or italics?
Link: https://stackoverflow.com/questions/62947592/does-google-cloud-vision-api-detect-formatting-in-ocred-text-like-bold-italics/63098644#63098644
No. Google OCR will most likely detect the text content even when its in bold or italics but the OCR model isn’t designed to understand font types.
[ad_2]
Source link