
[ad_1]
Automated invoice processing is the process of seamlessly extracting data from invoices entering your system and pushing it into your ERP so that processing a payment is a process of a few clicks. This blog is a comprehensive overview of the latest technologies that can enable you to do that.
Processing payments for finance departments is a chaotic process with invoices coming from in every format possible: paper invoices, PDFs, scanned PDFs, emails, etc. The volumes also fluctuate with seasons where peaks become extremely hectic for finance personnel. Manual data entry into systems during these times lead to common issues like lost documents and tally mismatches.
In this blog we talk about what an ideal automated invoice processing system looks like and what are the pros and cons of such a system.
Want to build your custom Automated invoice processing workflow? Head over to Nanonets and get started for free!
Invoice Automation Software
The Procure to Pay cycle typically involves the following steps:
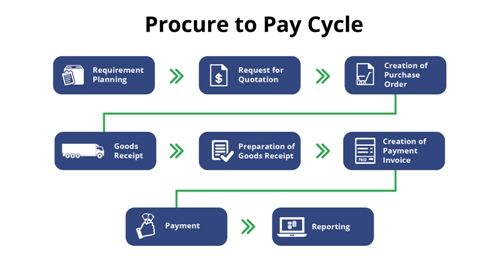
There are 3 steps in any invoice processing:
– Scanning the physical invoice
– Interpreting the invoice data according to business rules
– Filing of data into any ERP
Now there are two kinds of invoice processing softwares in the market :
- Rule-based OCR softwares like Kofax, Tipalti, Abby
- Intelligent OCR softwares like Nanonets, Rossum
The software should intelligently extract the required information and validate it according to business rules like mapping to a Purchase order number before pushing the final details into the ERP for payment processing. The rule-based systems don’t scale well as businesses keep adding/churning vendors and writing new rules everytime is an inefficient process.
These softwares also offer integration with most ERP softwares like SAP, Oracle, Microsoft Dynamics 365.
Automated Invoice Processing Workflow
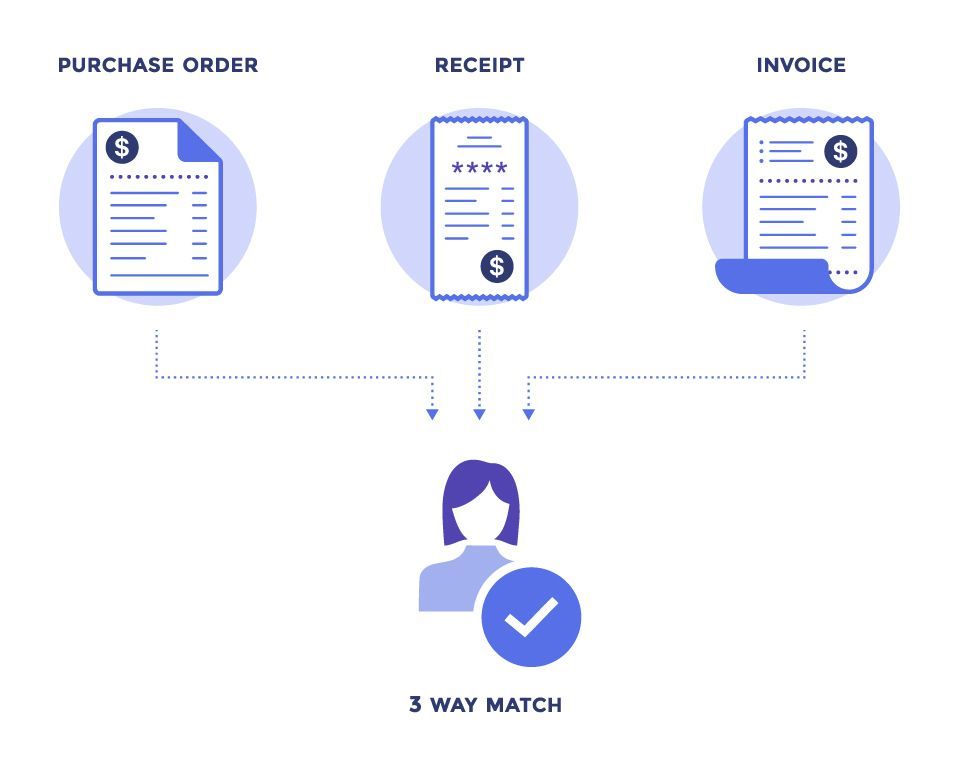
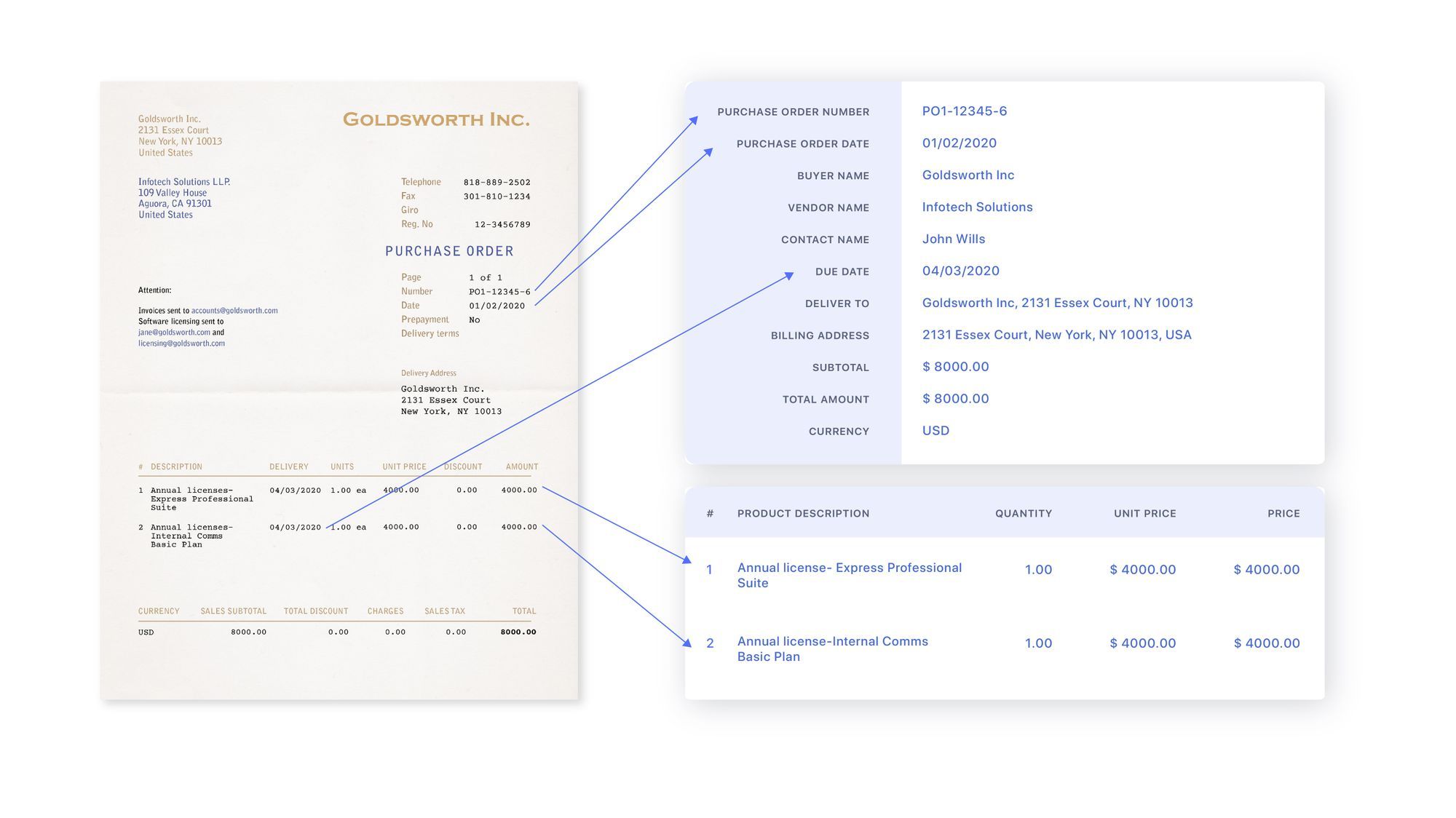
Any automated invoice processing software needs to run a 3-way match purchase order generated, invoices received against purchase order and receipts generated against invoice. Each of these documents has a unique number which needs to mapped against each other.
Here is an example of an automated invoice processing flow:
- Invoice arrives in specific email folder as an attachment (JPEG, PDF, EDI, PNG etc)
- The document enters under “Review” tab
- Invoice automation software extracts data from attachment
- Validate extracted data of vendor invoices with business rules from Master Vendor file
- If extracted values pass all validation rules, move to “Verified”
- If extracted values don’t pass validation rules, documents remain in “Review” section unless they are manually reviewed and moved to “Verified”
- Final report is generated containing all invoice data
- Export as .csv or integrate API with ERP system
Start using Nanonets for Automation
Try out the model or request a demo today!
TRY NOW

Invoice Cognitive Capture

Using the latest advances in artificial intelligence coupled with the reduction in compute costs, Nanonets invoice OCR solution is able to capture invoice data regardless of the format. You no longer need to setup rules
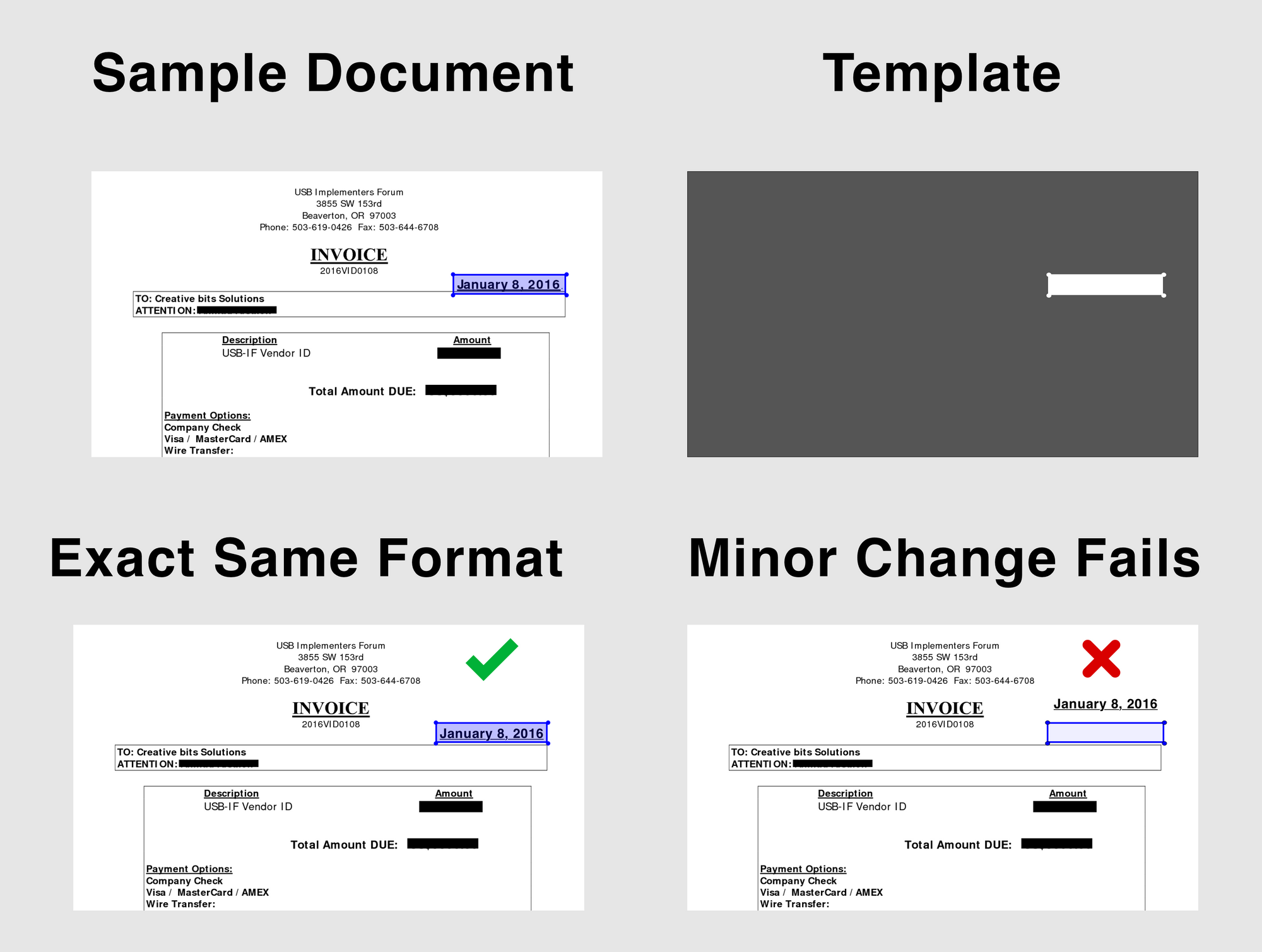
This is the phase where the information is extracted after the tables are identified. There are a lot of factors regarding how the content is structured and what content is present in the table. Hence it’s important to understand all the challenges before one builds an algorithm.
- Dense Content: The content of the cells can either be numeric or textual. However, the textual content is usually dense, containing ambiguous short chunks of text with the use of acronyms and abbreviations. In order to understand tables, the text needs to be disambiguated, and abbreviations and acronyms need to be expanded.
- Different Fonts and Formats: Fonts are usually of different styles, colors, and heights. We need to make sure that these are generic and easy to identify. Few font families especially the ones that fall under cursive or handwritten, are a bit hard to extract. Hence using good font and proper formatting helps the algorithm to identify the information more accurately.
- Multiple Page PDFs and Page Breaks: The text line in tables is sensitive to a predefined threshold. Also with spanning cells across multiple pages, it becomes difficult to identify the tables. On a multi-table page, it is difficult to distinguish different tables from each other. Sparse and irregular tables are hard to work with. Therefore, graphic ruling lines and content layout should be used together as important sources for spotting table regions.
Benefits
- Costs: Reduce actual keystrokes typed by almost 90% and take advantage of discounts on early payments
- Productivity: By removing the task manual tiresome data entry, your finance team does the more important tasks 75% faster
- Analytics: Using machines you can now extract a lot more data a lot faster leading to deep analytics into business processes inefficiencies and bottlenecks
- On-premises: We understand this is sensitive data to your business. Nanonets AP Automation software can run on-prem
Evolution of the invoicing process
The process of reviewing invoices has evolved a lot over time. The growth in technology has seen the process of invoice processing move through three major phases.
Phase 1: Manual Reviewing
Consider a use case where an organisation is going through it’s process of reimbursing its regular vendors for the expenses of the month.

The following steps are followed to process invoices –
- People are expected to submit several invoices in person to the concerned organisation’s point of contact.
- This person would in turn forward all the invoices to a reviewer who will review every document entirely. This includes writing down or entering each detail into a software like name of the person making the purchase, name of the store purchased from, date and time of purchase, items purchased, their costs, discounts and taxes.
- The sum total of each invoice calculated, again manually or if the data entry software is specifically designed for accounting purposes, using said software.
- A final bill/receipt is made with the final figures and the payments are processed.
Phase 2: Invoice Scanning and Manual Reviewing
With the advent of OCR techniques, much time was saved by automatically extracting the text out of a digital image of any invoice or a document. This is where most organisations that use OCR for any form of automation are currently.
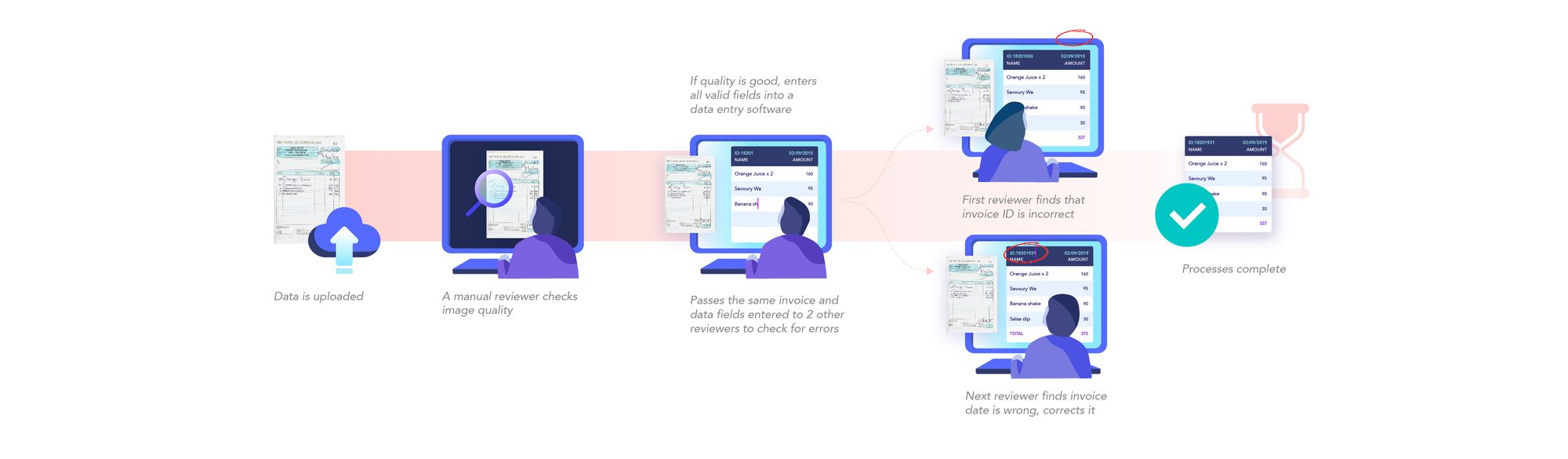
- Digital copies of invoices are obtained by scanning invoices or taking pictures using a camera.
- The text is extracted from these invoices using OCR. This is able to provide digital text that makes data entry a little easier. But a lot of work still needs to be done manually.
- The OCR results of each invoice have to be parsed appropriately to find the relevant data and discard the irrelevant data.
- Once this is done, the data has to be entered into a software which provides the reviewer with a template to make his task easier. This template is unique to each use case, organisation and mostly for each different kind of invoice. While the OCR process helps the invoice processing, it doesn’t solve many tedious parts due to the unstructured results of OCR.
- The data entered is put through manual review to correct errors. This process takes some time since it goes through multiple reviewers due to poor performance of currently available OCR tools.
- Finally, the calculations are done and the payment details are forwarded to the finance division.
How to digitize invoices better?
By using OCR and deep learning, we have enabled machines to perform as well and in some cases even better than humans.
Digitizing invoices involves several human moderated steps :
- Digital images of invoices taken and uploaded by the user.
- Image verified to be fit for further processing – good resolution, all data visible in the image, dates verified, etc.
- Images checked for fraud.
- Text in these images extracted and put in the right format.
- Text data entered into tables, spreadsheets, databases, balance sheets, etc.
Phase 3: Deep Learning and OCR

Deep learning approaches have seen advancement in the particular problem of reading the text and extracting structured and unstructured information from images. By merging existing deep learning methods with optical character recognition technology, companies and individuals have been able to automate the process of digitizing documents and enabled easier manual data entry procedures, better logging and storage, lower errors and better response times.
Several tools are available in the market and the open-source community for such tasks, all with their pros and cons. Some of them are Google Vision API, Amazon Rekognition and Microsoft Cognitive Services. The most commonly used open-source tools are Attention-OCR and Tesseract.
All these tools fall short in the same manner – bad accuracy which requires manual error correction and the need for rule-based engines following the text extraction to actually be able to use the data in any meaningful manner. We will talk more about these problems and more in the coming sections.
Validation
The data extracted from any invoice needs to be verified to ensure proper sums, VAT rates, VAT IDs, currencies, seller details and more. Most companies have workflows of multiple levels of approvals to ensure that an error doesn’t slip through it’s cracks where reconciliation later is a very painful process. A good invoice processing automation software allows you to setup some of these basic rules and in case any extracted value violates that, it raises a flag for a manual review. So now you’re adding a layer of Artificial intelligence led checks. In these redundant repetitive processes, machines have been said to been humans hands down.
Handling mismatches
In case there is a discrepancy in the information extracted against said business rules, one can create a resolution handling workflow where there is manual verification of this data. You can set confidence score thresholds to handle such automation – if a value is below a pre-decided confidence score number you route to a manual workflow, else push it to the automated payment workflow.
How Nanonets can help you
Nanonets is an artificial intelligence based OCR engine that helps business across the world automate manual extraction. Our AP Automation software makes monthly invoice processing a hassle-free process. Using invoice OCR API you can cut down upto 90% of manual tasks of data entry into your accounting softwares. We are a valued partner of over 20,000 businesses in 4 continents.

The Nanonets OCR API allows you to build OCR models with ease. You do not have to worry about pre-processing your images or worry about matching templates or build rule based engines to increase the accuracy of your OCR model.
You can upload your data, annotate it, set the model to train and wait for getting predictions through a browser based UI without writing a single line of code, worrying about GPUs or finding the right architectures for your deep learning models. You can also acquire the JSON responses of each prediction to integrate it with your own systems and build machine learning powered apps built on state of the art algorithms and a strong infrastructure.
Using the GUI: https://app.nanonets.com/
You can also use the Nanonets-OCR API by following the steps below:
Step 1: Clone the Repo, Install dependencies
git clone https://github.com/NanoNets/nanonets-ocr-sample-python.git
cd nanonets-ocr-sample-python
sudo pip install requests tqdm
Step 2: Get your free API Key
Get your free API Key from http://app.nanonets.com/#/keys
Step 3: Set the API key as an Environment Variable
export NANONETS_API_KEY=YOUR_API_KEY_GOES_HERE
Step 4: Create a New Model
python ./code/create-model.py
Note: This generates a MODEL_ID that you need for the next step
Step 5: Add Model Id as Environment Variable
export NANONETS_MODEL_ID=YOUR_MODEL_ID
Note: you will get YOUR_MODEL_ID from the previous step
Step 6: Upload the Training Data
The training data is found in images (image files) and annotations (annotations for the image files)
python ./code/upload-training.py
Step 7: Train Model
Once the Images have been uploaded, begin training the Model
python ./code/train-model.py
Step 8: Get Model State
The model takes ~2 hours to train. You will get an email once the model is trained. In the meanwhile you check the state of the model
python ./code/model-state.py
Step 9: Make Prediction
Once the model is trained. You can make predictions using the model
python ./code/prediction.py ./images/151.jpg
Update: Invoice Capture using Nanonets has never been easier. Head over to https://app.nanonets.com today and start extracting data from invoices!
[ad_2]
Source link