
[ad_1]
Introduction
This article will take you through how these companies can automate several procedures like menu digitization or invoice processing that are traditionally done manually to save time and operational costs.
We have all had moments when we suddenly crave a good dessert. Getting that big tub of ice-cream after a long day at work would’ve been an inconvenience a few years ago. But food delivery apps can get it to you at a lightning fast speed. With companies like DoorDash, DeliveryHero, GrubHub, FoodPanda, Swiggy, Zomato and Uber Eats competing for a greater market share in the food delivery market, adopting technology that aids companies to scale up their operations has become a necessity to stay relevant.
Analyzing digitization workflows
Digitization has changed how restaurants or food delivery services function. In the food delivery market, digitization has helped these companies make their onboarding processes more efficient with higher accuracy. Restaurants are using digital menus, interactive table-tops, on-table tablets and augmented reality menus, among other innovations like these guys at Yeppar –
Traditionally, this process was mostly done manually or with the help of some OCR software. Often, this process would not be very accurate, requiring humans to review the outputs several times at several stages of the pipeline.
Here’s how a menu digitization workflow would normally look –
- Images of the menu are taken
- The images of the menu are submitted to said delivery service along with details like the restaurant’s name, contact, address, etc.
- The submitted data is verified and the menu is sent for digitization and entry.
- The food items, their costs, ingredients, descriptions, etc are extracted from the images and entered into a data entry software manually.
- These entries are manually reviewed and the errors are corrected before it is all finally pushed to the database.
The above mentioned workflow is getting replaced with workflows that incorporate OCR to reduce the data entry work and run the OCR results through multiple manual reviews for minimal errors, but this process is far from perfect. A more efficient process can be designed to reduce time taken, manual labor expended and costs of getting this done. The next section will run you through what a modern workflow looks like and what can be done better.
How it ought to be done
The process of manual data entry and review are in the past. These processes have been replaced with faster workflows aided by digitization. Here’s what a modern workflow for menu card digitization would look like –
- Images of the menu are taken
- The images are processed, corrected for orientation, blur, noise, etc. If the image quality is low, the vendor is notified about the bad quality and is requested to re-upload the images.
- Once the images are pre-processed, they are sent through an OCR software and the text is extracted from the images.
- The extracted text is cleaned, put into a structure and entered into a data entry software automatically (template based or non template based).
- The entered data is checked for errors finally by manual reviewers.
This sort of automated workflow wasn’t possible with our traditional OCR methods because of the lack of accuracy in these methods, their susceptibility to failure in extreme cases, and the high variability in the structure of different menu cards. But with deep learning aided OCR solutions, we can do away with OCR solutions that are rule or template based and can automate not just text recognition but also information extraction.
Imagine, if a vendor uploaded images of the menu card along with some extra details and the process of finding names of the items sold, their prices, their descriptions and their categories automatically extracted and put into a table. All you need is a reviewer at the end of this loop, who looks for errors in OCR text, corrects whatever found and pushes it to the database. Your food delivery services can drive higher onboarding rates with fewer errors, can reduce the money spent on hiring manual reviewers and people for data entry and also increase customer satisfaction.
Challenges in implementation

The current OCR technology available to us through open source tools or commercially available products do not hit a high enough accuracy to completely automate this process. This is due to several factors:
- Too many different templates of menus
Having a model that can extract text as well as the structure and fields of the menu like categories, dishes, descriptions, prices, etc requires non-template based solutions. - Orientation of the menu in images
The model needs to be trained on augmented images in different orientations or the original images need to be transformed effectively to not hurt model performance. - Multiple languages in a menu
Making a generalised model for multiple languages either requires a lot of data or separate models working together to identify language and then apply the appropriate model for OCR. - Multiple fonts and font sizes in a menu
A model might encounter a completely new and difficult to read font. This requires us to re-train our models periodically with new data to continuously improve our models over time. - Character accuracy vs sequence accuracy
Drop in sequence accuracy due to a mediocre character accuracy can be remedied by coupling convolutional layers with recurrent layers and attention mechanisms. - Noise or blur in the menu images
Noise and blur in images leads to bad accuracy and noise, blur removal and super-resolution of images become necessary steps in the pre-processing of images. - Difficulty in finding adequate training data
Data that will represent different templates, fonts, font sizes, resolutions, languages, noise, lighting and blur conditions can’t be found in a single or a few open source datasets. - Lack of tools and services that allow easy custom model building
Many open source or paid services do not allow users to build their models on custom data. This limits the use-cases OCR technology can be applied in.
Chalking out the solution
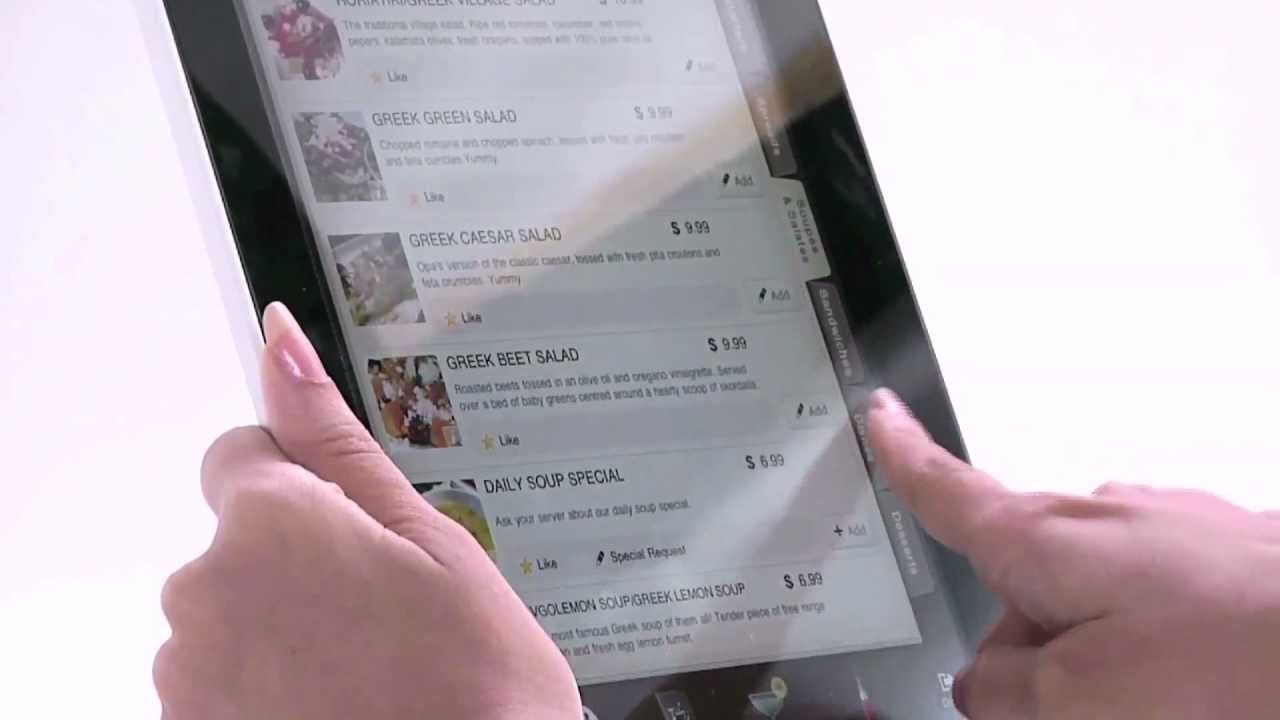
As you saw above, building a workflow that can work efficiently at scale comes with a long list of challenges and finding the solution requires us to apply several areas of OCR, deep learning and computer vision to our problem of menu digitization.
Understanding the problem
We have seen where our software can fall short in terms of some technical challenges that your deep learning engineers will have to deal with. Trying to place these challenges in a more generalised pipeline for menu digitization should help us pin down which parts of the current tech need to be improved, which ones need to be removed and what needs to be added.
A menu digitization workflow would look like this –
- Image pre-processing – challenges related to quality of images, orientation, noise, blur and variety in backgrounds.
- OCR – challenges related to character recognition like fonts, font sizes, languages, training data and sequence accuracy.
- Information extraction – here you consider template vs non-template based solutions and table extraction.
- Information review – once the information is extracted and put into the required structure, we get our reviewers to correct errors or fill in missing information.
Understanding the tech

Addressing these challenges on a technical level as well as on a product level can be done by using the state of the art in the field of OCR and digitization.
- Image pre-processing – to get good OCR results, it is important to make sure your images are processed appropriately. A review of the challenges and the open source tools available for this can be found here. There are several things one needs to take care of when trying to do this –
- scaling images to the right size
- increase contrast
- binarizing the image
- removing noise and scanning artifacts
- deskew the image
- OCR – moving from traditional OCR methods to deep learning based methods can help increase accuracy of our extracted text. Using deep learning based methods can also help us automatically learn the structure. Services offered by OCR tools are limited in their usage as they do not allow building custom models and limit our flexibility with respect to templating our OCR results as well. There are several deep learning methods that have been applied to the problem and have performed differently on different datasets.
Several open source tools are available for OCR like Tesseract, KrakenOCR, and Attention OCR. A tutorial on building a model using Attention OCR can be found here and one using Tesseract and OpenCV can be found here and here. What kind of data you will be dealing with in the end decides what kind of images you deal with, what language the menus are in, the fonts, etc. The performance of different pre-trained models will vary accordingly. You also need to fine-tune these models to make it work for your use-case.
- Information extraction – the process of information extraction can be template based or non-template based. A template based solution can’t be used for menu digitization due to the variety of menu designs your data will include and having a different template made for each vendor you work with doesn’t sound practical. A non template based solution is required to deploy models at scale, something that requires carefully designed machine learning models trained on a lot of different data. It requires us to use deep learning methods like table extraction and graph convolutional networks that are trained on a wide variety of data that covers as many fields as possible.
- Information review – by automating the steps above with OCR and non template based solutions, the only place that requires human intervention is this final step. A human in the loop can review all the extracted information and correct the errors and fill in missing data. Retraining models on corrected data can reduce model bias and increase accuracies over time. Depending on what the use-case is, you could also chose the threshold confidence to put predictions up for review.
Enter Nanonets
With Nanonets you do not have to worry about finding machine learning talent, building models, understand cloud infrastructure or deployment. If you have a menu digitization problem that needs to be solved, NanoNets can provide an end-to-end solution that will resolve all the issues mentioned above and deliver a smooth and reliable automated workflow for the process.
Easy to use web-based GUI
Nanonets offers an easy to use web-based GUI that communicates with their API and lets you create models, train them on your data, get important metrics like precision and accuracy and run inference on your images, all without writing any code.
Cloud-hosted models
Besides providing several models that can be used out of the box directly to get solutions, users can build their models that are hosted on the cloud and can be accessed with an API request for inference purposes. No need to worry about getting a GCP instance or GPUs for training.
State-of-the-art algorithms
The models built use state-of-the-art algorithms to get you the best results. These models constantly evolve to become better with more and better data and better technology, better architecture design, and more robust hyperparameter settings.
The greatest challenge in building an invoice digitization product is to give structure to the extracted text. This is made easier by our OCR API that automatically extracts all the necessary fields with the values and puts them in a table or a JSON format for you to access and build upon easily.
Automation driven
We at Nanonets believe that automating processes like invoice digitization can create a massive impact on your organization in terms of monetary benefits, customer satisfaction, and employee satisfaction. Nanonets strives to make machine learning ubiquitous and to that end, our goal remains to make any business problem you have solved in a way that requires minimal human supervision and budgets in the future.
OCR with Nanonets
The Nanonets OCR API allows you to build OCR models with ease. You can upload your data, annotate it, set the model to train and wait for getting predictions through a browser based UI without writing a single line of code, worrying about GPUs or finding the right architectures for your deep learning models.
Digitization in 15 mins
You can upload your own data and train a model, acquire the JSON responses of each prediction to integrate it with your own systems and build machine learning powered apps built on state of the art algorithms and a strong infrastructure.
Here’s a demo for ID card digitization to give you an idea –
Using the GUI: https://app.nanonets.com/
You can also use the Nanonets-OCR API by following the steps below:
Step 1: Clone the Repo, Install dependencies (repo link)
git clone https://github.com/NanoNets/nanonets-id-card-digitization.git
cd nanonets-id-card-digitization
sudo pip install nanonets
Step 2: Get your free API Key
Get your free API Key from http://app.nanonets.com/#/keys
Step 3: Set the API key as an Environment Variable
export NANONETS_API_KEY=YOUR_API_KEY_GOES_HERE
Step 4: Upload Images For Training
The training data is found in images (image files) and annotations (annotations for the image files)
python ./code/training.py
Note: This generates a MODEL_ID that you need for the next step
Step 5: Add Model Id as Environment Variable
export NANONETS_MODEL_ID=YOUR_MODEL_ID
Note: you will get YOUR_MODEL_ID from the previous step
Step 6: Upload the Training Data
python ./code/training.py
Step 7: Get Model State
The model takes ~2 hours to train. You will get an email once the model is trained. In the meanwhile you check the state of the model
python ./code/model-state.py
Step 8: Make Prediction
Once the model is trained. You can make predictions using the model
python ./code/prediction.py PATH_TO_YOUR_IMAGE.jpg
Nanonets and humans in the loop
The ‘Moderate’ screen aids the correction and entry processes and reduce the manual reviewer’s workload by almost 90% and reduce the costs by 50% for the organisation.

Features include
- Track predictions which are correct
- Track which ones are wrong
- Make corrections to the inaccurate ones
- Delete the ones that are wrong
- Fill in the missing predictions
- Filter images with date ranges
- Get counts of moderated images against the ones not moderated
All the fields are structured into an easy to use GUI which allows the user to take advantage of the OCR technology and assist in making it better as they go, without having to type any code or understand how the technology works.
Update:
We’re seeing more interest on this topic in light of COVID led broader digital transformation across industries and we’ll be following up with a post on why restaurants need to embrace menu-card digitization sooner than later.
[ad_2]
Source link