
[ad_1]
In this article we will give you a brief overview of Named Entity Recognition (NER), its importance in information extraction, its brief history, latest approaches used to perform NER and at the end will also show you how to quickly use a latest NER model, on your dataset.
What is NER?
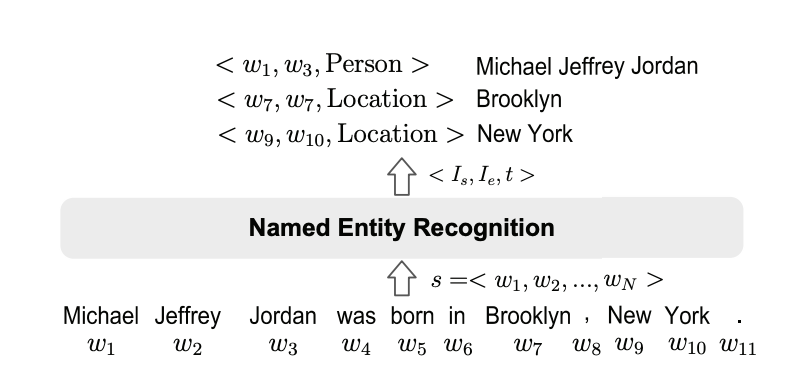
As per Wikipedia, a named entity is a real-world object (can be abstract or have a physical existence) such as persons, locations, organizations, products, etc. that can be denoted with a proper name e.g. in Ashish Vaswani et.al introduced Transformers architecture in 2017. Ashish Vaswani and 2017 could be considered named entities since Ashish Vaswani (physically exist) is the name of a person & 2017 (abstract) is a date.
And NER is a part of information extraction task where the goal is to locate and classify such named entities from unstructured text into predefined entity categories e.g. in Allen Turing was born on 23 June 1912. Allen Turing and 23 June 1912 could be considered a person entity belonging to the person category and 23 June 1912 could be considered a date entity belonging to the date category.
Formally, we can define NER as below,
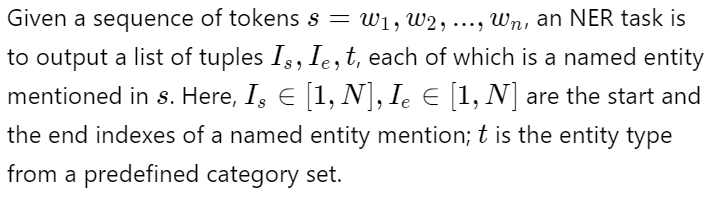
i.e.
In the above definition, we are assigning a single entity category to an entity, but in recent literature classifying entities into multiple categories using datasets like Wiki (Gold), BBN, etc. is also quite popular and classified as a fine-grained NER task. Another, popular variant of NER task is nested NER tasks, where some entity mentions are embedded in longer entity mentions. e.g. Bank of America where Bank of America and America both could be entities. Extracting such entities could be a bit tricky and we will look at a few architectures to handle that but let us first see where NER is useful.
Why or Where NER is useful?
Extracting named entities from the unstructured text could be a very useful step for a variety of downstream tasks and in supporting various applications. We will look at a few of the tasks and applications below.
- In chatbots extracting entities is very essential to understand the context and provide relevant recommendations/information based on the mentioned entity. In Rasa, a popular chatbot development framework, there is a separate NLU (Natural Language Understanding) pipeline for training an entity detection and intent classification model.
- Semantic text search can be improved by recognizing named entities in search queries which in turn enable search engines to understand the concepts, meaning, and intent behind the queries well.
- Categorizing news articles into pre-defined hierarchies using different entities related to sports, politics, etc.
- Extracted entities could be used as features in other downstream tasks like question answering, machine translation, etc.
This is not the exhaustive list of use cases of NER but you can understand that uses of NER are many.
Brief History of NER
Before jumping to the latest deep learning based techniques to perform NER it is important to get a brief overview of traditional approaches to NER. So let us see how it started.
The term “Named Entity” (NE) was first used at the Sixth Message Understanding Conference (MUC-6), as the task of identifying names of organizations, people, and geographic locations in the text, as well as currency, time, and percentage expressions in 1996. Since then there has been a lot of work and NER has become a very popular and important NLP task.
Rule-Based Methods
In the beginning, there were rule-based methods that relied on hand crafted rules. Rules are designed on domain-specific gazetteers (gazetteers are specialized names for a particular class of named entity e.g. India is in the location gazetteer) and syntactic-lexical patterns (e.g. lemmatization of words, POS tagging of words). They work very well when the lexicon is exhaustive.
Unsupervised Approaches
Some unsupervised approaches like clustering-based NER systems which extract named entities from the clustered groups based on context similarity, systems that use terminologies, corpus statistics (e.g. inverse document frequency), and shallow syntactic knowledge (e.g. noun phrase chunking), etc. have been made.
Supervised Approaches
While applying supervised machine learning approaches, the NER problem is cast to a multi-class classification or sequence labeling task. In this approach, features are carefully designed using word-level features, documents, corpus features, etc. to represent each training example. Machine learning algorithms are then utilized to learn a model to recognize similar patterns from unseen data.
Deep Learning Approaches
Deep Learning has revolutionized every field it has been applied to, and the same is the case in NER. The current state of the art models in NER is all powered by deep learning architectures. There are lots of reasons behind the success of deep learning models and we will look at a few of both general and specific reasons here.
- In classical machine learning problems, features are created manually or using domain expertise. And a machine learning algorithm like SVM, Random Forest, etc is applied to it. This could introduce bias specific to a dataset, and also sometimes creating good features (that can be classified easily) is not possible e.g. features of different objects in an image. On the other hand, deep learning models create necessary features on their own using only the raw data. The features or representations created by deep learning models capture a lot of complex semantic features which would be difficult for even an expert to design using logical rules. And this helps them in getting the overall performance.
- Another really important factor/choice which changed the NLP demography completely is the distributed representation of words or characters. In order to perform machine learning on textual data, it needs to be converted into some numerical representation, and previously one-hot encoded vectors were used to represent words i.e. a word ‘deep’ will be represented by a vector [0,0,0,…,1,0,…,0] where the size of the vector is equal to vocab size. While distributed word representations like word2vec, glove, etc. are low dimensional in comparison to one-hot encoded representations and capture semantic and syntactic properties of words. This successively helps deep learning models as well. Another popular and recent variant of this is contextual distributed representations. In contextual distributed representations, the context in which a word appears is also taken into consideration e.g. in I like to eat an apple. and I bought apple stocks word apple has different meanings so its vector representation should also be different depending on the context it appears in.
- Attention is one such idea in deep learning which makes almost anything work :P. It has made difficult problems like machine translation, question answering, etc. work really well in the real world. Though there is no popular NER model which uses attention, one popular neural network architecture, Transformers, which we will be discussed below, is based on a variant of attention called self-attention, and it has changed the way we do NLP a lot. If you are not familiar with attention and self-attention go through this article by Denny Britz and this article by Jay Alammar before proceeding. In brief, attention is a mechanism to dynamically assign coefficients (or weightage) in a linear combination of n different things (scalars, vectors, matrices, etc.). Intuitively it means while combining n things, attention helps us decide their individual contributions (or importance). Here dynamically means that the coefficients will change according to each fed example. Self-attention also serves the same purpose as attention with the only difference being the way it is calculated. Please refer to this Reddit thread to understand the difference better.
After going through some of the most important ideas in deep learning, let us go through some popular and latest deep learning architectures used for NER.
Bi-LSTM with CRF
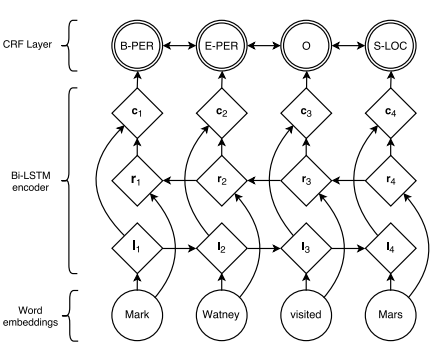
Sequence tagging using Bi-LSTM (or LSTM) has been explored before where a combination of forward and backward embeddings of each token is passed to a linear classifier (sometimes an additional linear transformation operation is added before linear classifier) which produces a probability distribution over all the possible entity-tags for each token. However, this approach doesn’t work well when there are strong dependencies across output labels.
NER is one such task since the “grammar” that characterizes interpretable sequences of tags imposes several hard constraints e.g., I-PER cannot follow B-LOC. Therefore, instead of modeling tagging decisions independently, modeling them jointly using a conditional random field works very well. The CRF layer could add some constraints to the final predicted labels to ensure they are valid. These constraints can be learned by the CRF layer automatically from the training dataset during the training process. Now let us try to understand the formulation.

A softmax over all possible tag sequences yields a probability for the sequence y:
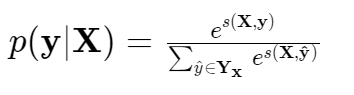
And during training log-probability of the correct tag sequence is maximized:
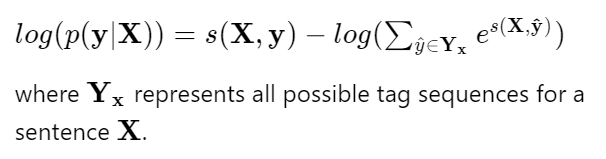
This formulation encourages the network to produce a valid sequence of output labels. During evaluation the sequence that obtains the maximum score is predicted:
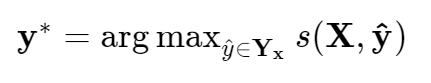
NER Using BERT Like Models
Doing NER with different BERT-like models like RoBERTa, Distill-BERT, ALBERT etc is very similar. We will see this approach here briefly since it has already been covered in detail before.
Basically, a linear classifier is added on top of BERT or BERT like models to classify each token into an entity category.
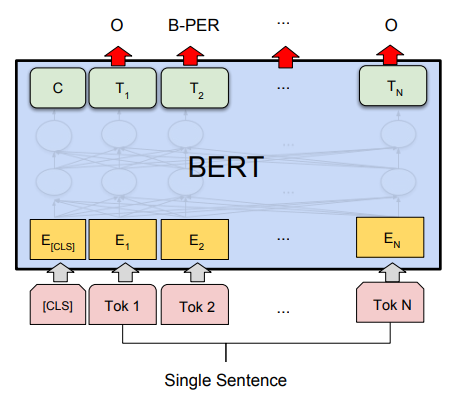

And the complete architecture with classifier head is finetuned on cross-entropy loss. During validation entity category with maximum probability is assigned to each token.
Now let us go through some latest techniques to do NER.
Named Entity Recognition as Machine Reading Comprehension
In recent years ( e.g. https://arxiv.org/pdf/2011.03023.pdf), we have seen formalizing NLP problems as question answering tasks has shown very good performance using relatively fewer data. In A Unified MRC Framework for Named Entity Recognition, the authors have tried to implement NER as an MRC problem and have been able to achieve very good results, even on nested NER datasets using very little finetuning of the BERT language model. So, let us dig into the model architecture and try to understand the training procedure.



In the next step each predicted start index needs to be matched with its corresponding predicted end index. A binary classification model is trained to predict the probability of a pair of start and end indices matching as follows:

The sum of cross-entropy loss (or binary cross-entropy loss) on P_start
& P_end and binary cross-entropy loss on P_{i_{start},j_{end}}
are calculated and gradients are backpropagated to train the complete architecture. In this method, more than one entity and even nested entities are extracted easily in comparison to traditional question answering architecture where only a single span is output given a query and passage pair. Another benefit of this approach is sample efficient training i.e. less training data is required to train a decent performing model.
LUKE
Using distributed entity representations just like word embeddings is another method that has been explored before to improve NLP tasks involving entities e.g. relation classification, entity typing, NER. LUKE (Language Understanding with Knowledge-based Embeddings) is an extension of this method by tweaking BERT’s Masked Language Model (MLM) and adding a new entity-aware self-attention mechanism. Let us start with the architecture.
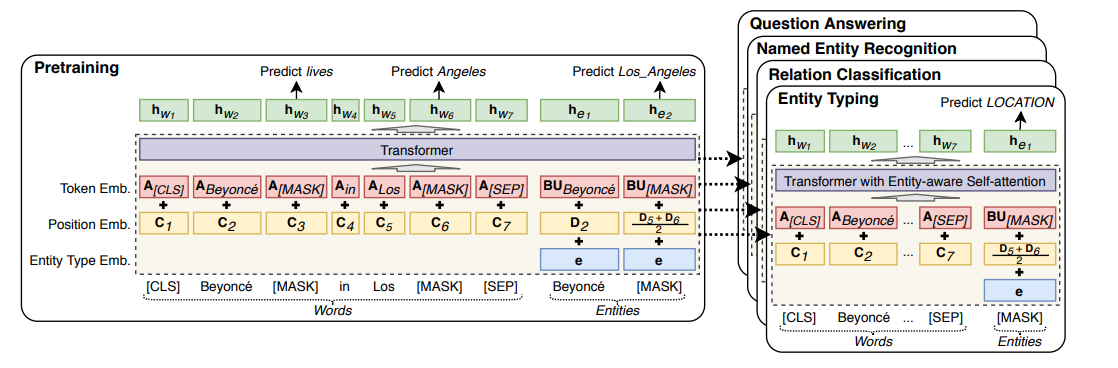
In LUKE the aim is to create contextual representations of entities just like contextual word representations. Hence, entities appended at the end of word tokens are fed to RoBERTa as shown in the figure above. In order to accommodate entities new embeddings, token embeddings for entities, position embeddings for entities, and entity type embeddings are introduced.

Another variation, is in the Query matrix of self-attention layer i.e. different query matrices for different types of tokens, is tried out and showed strong gains in ablation studies. Difference between standard self-attention and modified self-attention can be seen using below equations.
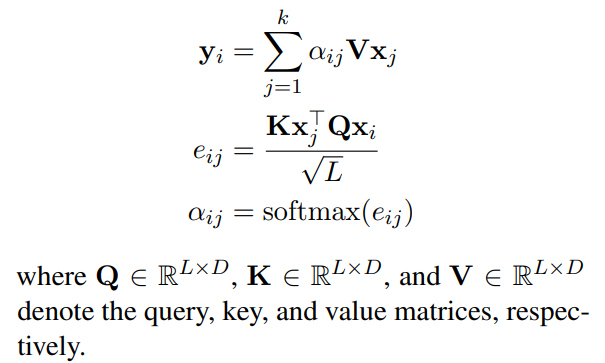


LUKE has been tested on different problems and showed SOTA results on many of those tasks.
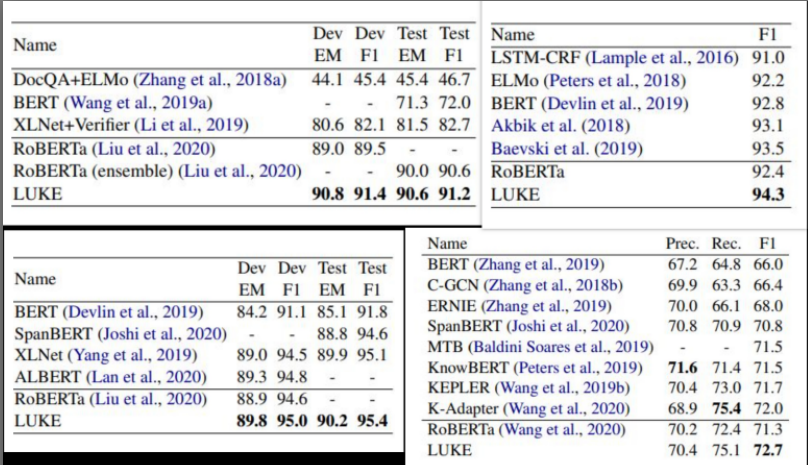
Though LUKE is showing very good results on many NLP tasks, a comparison of its contextual entity embeddings with previous static and contextual embeddings would be really interesting to see and may justify the additional space and time complexity.
Datasets
There are many NER datasets including domain-specific datasets freely available. I will briefly explain some of the popular datasets that are frequently used in current research papers.
- CoNLL-2003: It contains annotations for Reuters news in two languages: English and German. The English dataset has a large portion of sports news with annotations in four entity types (Person, Location, Organization, and Miscellaneous). The complete dataset can be downloaded from here.
- OntoNotes: The OntoNotes data is annotated on a large corpus, comprising of various genres (weblogs, news, talk shows, broadcast, usenet newsgroups, and conversational telephone speech) with structural information (syntax and predicate argument structure) and shallow semantics (word sense linked to an ontology and coreference). There are 5 versions, from Release 1.0 to Release 5.0. The texts are annotated with 18 entity types, consisting of 11 types (Person, Organization, etc) and 7 values (Date, Percent, etc). This dataset can be downloaded from here.
- ACE 2004 and ACE 2005: The corpus consists of data of various types of annotated entities and relations and was created by the Linguistic Data Consortium. The two datasets each contain 7 entity categories. For each entity type, there are annotations for both the entity mentions and mention heads. These datasets contain about 24% and 22% of the nested mentions. And it can be downloaded from here.

Metrics
Below are the most commonly used evaluation metrics for NER systems. There are other complex evaluation metrics also available but they are not intuitive and make error analysis difficult.

Train your own NER model
Now let us train our own NER model. We will be using the ACE 2004 dataset to train an MRC based NER model, as discussed above. So let us look at the different steps involved. We will be using this repository as a reference for our implementation and complete code can be found on the repo here.
Data Preparation
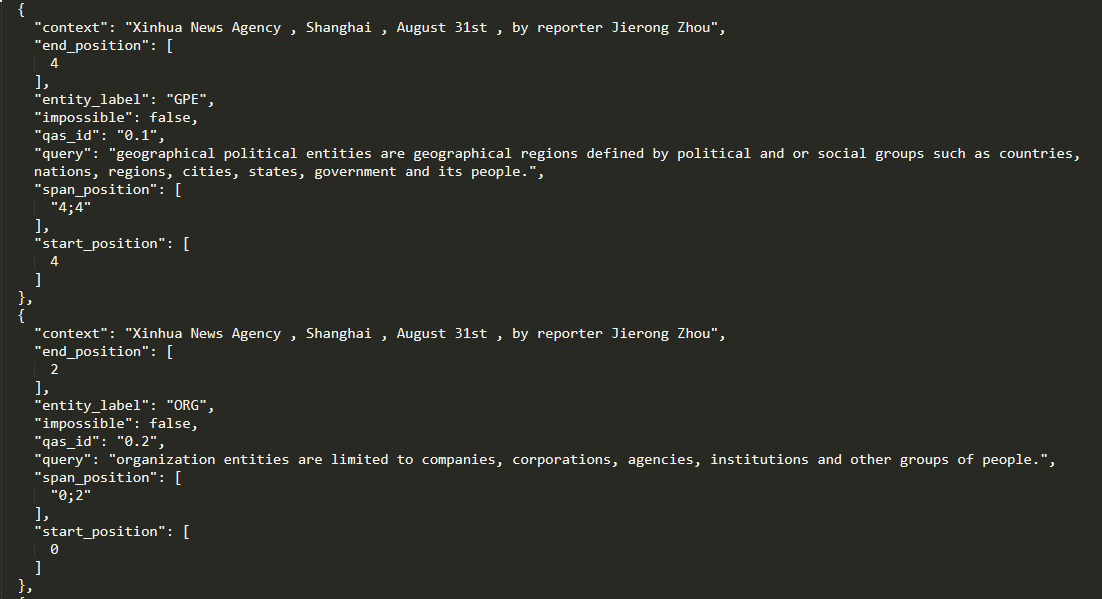
ACE 2004 dataset can be downloaded from here. It is structured in XML format like below and we need to process the data in order to convert it into a proper structure to feed to the underlying BERT model as a question answering problem. Fortunately, the processed version of data which looks like below can be downloaded from here. But if you want to use your own data make sure to convert it into a relevant format. A sample code to do so is provided here.
Training
We have already seen the architecture of the model and how it is trained above. So, here we will look at the code and different hyperparameters to start the training process. First clone this repository
git clone https://github.com/SKRohit/mrc-for-flat-nested-ner
cd mrc-for-flat-nested-ner
Then run the below command to start training the Hugging Face’s ‘bert-base-uncased’ implementation on ACE-2004 data present in `data` directory. One can play around with different parameters as well.
python trainer_new.py --data_dir "./data/ace2004"
--bert_config_dir "./data"
--max_length 128
--batch_size 4
--gpus="1"
--precision=16
--progress_bar_refresh_rate 1
--lr 3e-5
--distributed_backend=ddp
--val_check_interval 0.5
--accumulate_grad_batches 2
--default_root_dir "./outputs"
--mrc_dropout 0.1
--bert_dropout 0.1
--max_epochs 20
--span_loss_candidates "pred_and_gold"
--weight_span 0.1
--warmup_steps 0
--max_length 128
--gradient_clip_val 1.0
--model_name 'bert-base-uncased'
In the original repository, pre-trained BERT models by Google were used, which needed to be downloaded and converted into PyTorch models before being used. Hence, here I adapted the code to run any Huggingface’s BERT implementation by just providing the model name in model_name parameter in trainer.py.
Start using Nanonets for Automation
Try out the model or request a demo today!
TRY NOW

[ad_2]
Source link