
[ad_1]
Receipt digitization addresses the challenge of automatically extracting information from a receipt. In this article, I cover the theory behind receipt digitization and implement an end-to-end pipeline using OpenCV and Tesseract. I also review a few important papers that do Receipt Digitization using Deep Learning.
What is Receipt Digitization?
Receipts carry the information needed for trade to occur between companies and much of it is on paper or in semi-structured formats such as PDFs and images of paper/hard copies. In order to manage this information effectively, companies extract and store the relevant information contained in these documents. Traditionally this has been achieved by manually extracting the relevant information and inputting it into a database which is a labor-intensive and expensive process.
Receipt digitization addresses the challenge of automatically extracting information from a receipt.
Extracting key information from receipts and converting them to structured documents can serve many applications and services, such as efficient archiving, fast indexing and document analytics. They play critical roles in streamlining document-intensive processes and office automation in many financial, accounting and taxation areas.

Who will find Receipt Digitization useful?
Here are a few areas where Receipt Digitization can make a huge impact:
Accounts payable and receivables automation
Computing Accounts payable (AP) and Accounts Receivables (ARs) manually is costly, time-consuming and can lead to confusion between managers, customers and vendors. With digitization, companies can eliminate these drawbacks and can have more advantages – Increased Transparency, Data Analytics, Improved working capital and easier tracking.
Supply chain optimization
Supply chains are the backbone of many a company’s proper functioning. Managing tasks, information flows, and product flows is the key to ensuring complete control of supply and production. This is essential if organizations are to meet delivery times and control production costs.
The companies that are truly thriving these days have something significant in common: a digitized supply chain. 89% of companies with digital supply chains receive perfect orders from international suppliers, ensuring on-time delivery. One of the key elements of realising the next generation digital Supply Chain 4.0, is automating data capturing and management and a lot of this data is the form of receipts and invoices. Manual entry of receipts acts as a bottleneck across the supply chain and leads to unnecessary delays. If this receipt processing is digitized it can lead to substantial gains in time and efficiency.
Have an OCR problem in mind? Want to digitize invoices, PDFs or number plates? Head over to Nanonets and build OCR models for free!
Why is it a difficult problem?
Receipt digitization is difficult since receipts have a lot of variations and are sometimes of low quality. Scanning receipts also introduces several artifacts into our digital copy. These artifacts pose many readability challenges.

Here’s is a list of the a few things that make it a difficult problem to crack
- Handwritten text
- Small fonts
- Noisy images
- Faded images
- Camera motion and shake
- Watermarkings
- Wrinkles
- Faded text
A Traditional Receipt Digitization Pipeline
A typical pipeline for this kind of an end-to-end approach involves:
- Preprocessing
- Optical Character Recognition
- Information Extraction
- Data dump
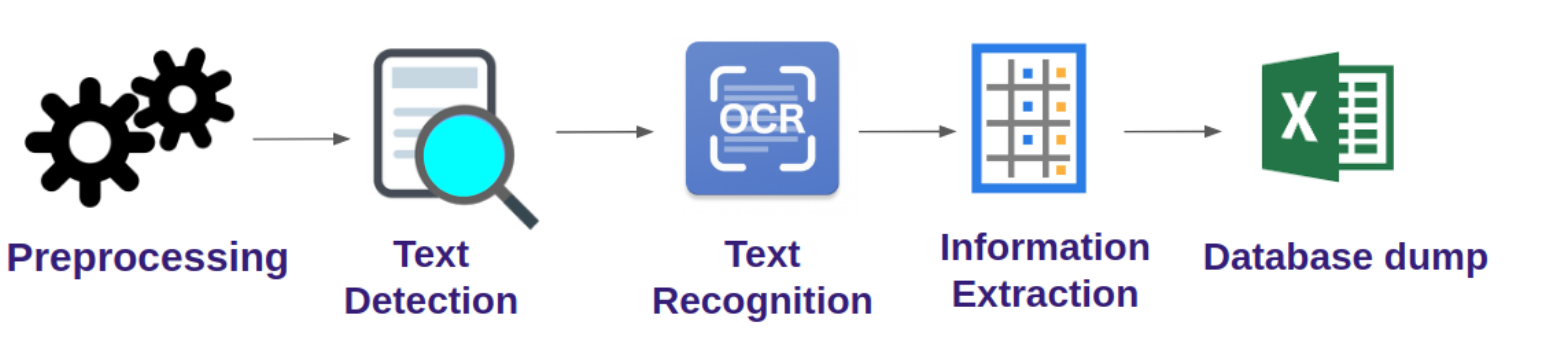
Let’s dive deeper into each part of the pipeline. The first step of the process is Preprocessing.
Preprocessing
Most scanned receipts are noisy and have artefacts and thus for the OCR and information extraction systems to work well, it is necessary to preprocess the receipts. Common preprocessing methods include – Greyscaling, Thresholding (Binarization) and Noise removal.
Grayscaling is simply converting a RGB image to a grayscale image.
Noise removal typically involves removing Salt and Pepper noise or Gaussian noise.
Most OCR engines work well on Black & White images. This can be achieved by thresholding, which is the assignment of pixel values in relation to the threshold value provided. Each pixel value is compared with the threshold value. If the pixel value is smaller than the threshold, it is set to 0, otherwise, it is set to a maximum value (generally 255).
OpenCV provides various thresholding options – Simple Thresholding, Adaptive Thresholding

Optical Character Recognition
The next step in the pipeline is OCR. It is used to read text from images such as a scanned document or a picture. This technology is used to convert, virtually any kind of images containing written text (typed, handwritten or printed) into machine-readable text data. OCR involves 2 steps – text detection and text recognition.

There are a number of approaches to OCR. The conventional computer Vision approach is to
- Using filters to separate the characters from the background
- Apply contour detection to recognize the filtered characters
- Use mage classification to identify the characters
Applying filters and image classification is pretty straightforward, (think MNIST Classification using SVN), but contour matching is a very difficult problem and requires a lot of manual effort and is not generalizable.
Next come the Deep Learning approaches. Deep Learning generalizes very well. One of the most popular approaches for text detection is EAST. EAST ( Efficient accurate scene text detector) is a simple yet powerful approach for text detection. The EAST network is actually a version of the well known U-Net, which is good for detecting features of different sizes.
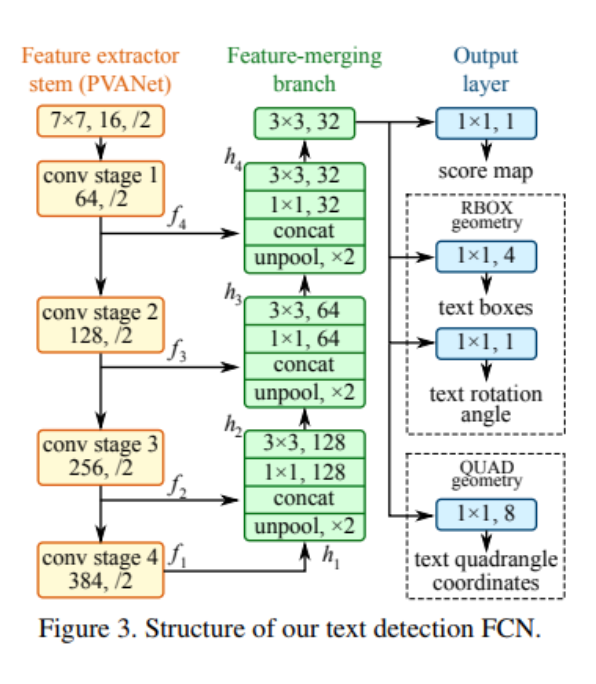
CRNN and STN-OCR (Spatial Transformer Networks) are other popular papers that perform OCR.
The most common approach to the problem of Information Extraction is rule-based, where rules are written post OCR to extract the required information. This is a powerful and accurate approach, but it requires you to write new rules or templates for a new type of document.
Several rule-based invoice analysis systems exist in literature.
- Intellix by DocuWare requires a template annotated with relevant fields.
- SmartFix employs specifically designed configuration rules for each template
The rule-based methods rely heavily on the predefined template rules to extract information from specific invoice layouts
One approach that has become very common in the past few years is to use a standard Object Detection framework like YOLO, Faster R-CNN to recognize fields. So instead of pure text detection, field recognition and text detection are performed simultaneously. This makes the pipeline smaller (Text Detection→ Recognition → Extraction to Detection → Recognition). There is no need to write any rules since the object detector’s learn to recognize these fields.
Data Dump
Once you have your information extracted, the data dump can be done as our use case requires. Often a JSON format to store the fields information is convenient. These JSON files can readily be converted into XML files, Excel sheets, CSV files or plaintext files depending on who wants to work with the data and how.
Receipt Digitization using Tesseract
Now that we have an idea of the pipeline, let’s implement it on an example receipt. This is the receipt we’ll be working with. Our goal at the end of this is to extract the Restaurant name, Items purchased with their quantity and cost, date of purchase, and the total.

Preprocessing
Since our receipt is already in greyscale and there’s not a lot of noise, I’m only going to do thresholding by applying a threshold of 210. You can tweak the value to get the right output. Too less and you will miss out on a lot. Too close to 255 will make everything black.
We’ll need to install OpenCV first.
pip install opencv-pythonHere’s the code for thresholding.
import cv2
import numpy as np
from matplotlib import pyplot as plt
# Read the image
img = cv2.imread('receipt.jpg',0)
# Simple thresholding
ret,thresh1 = cv2.threshold(img,210,255,cv2.THRESH_BINARY)
cv2.imshow(thresh1,’gray’)This is what the output looks like.

Text Detection
For text detection I will be using an open-source library called Tesseract. It’s the definitive OCR library and has been developed by Google since 2006. The latest release of Tesseract (v4) supports deep learning-based OCR that is significantly more accurate. The underlying OCR engine itself utilizes a Long Short-Term Memory (LSTM) network.
First let’s install the latest version of Tesseract.
For ubuntu
sudo apt install tesseract-ocrFor macOS
brew install tesseract --HEADFor windows, you can download the binaries from this page
Verify your tesseract version.
tesseract -vOutput –
tesseract 4.0.0-beta.3
leptonica-1.76.0
libjpeg 9c : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11
Found AVX512BW
Found AVX512F
Found AVX2
Found AVX
Found SSEInstall your Tesseract + Python bindings
Now that we have the Tesseract binary installed, we now need to install the Tesseract + Python bindings so our Python scripts can communicate with Tesseract. We also need to install the german language pack since the receipt is in german.
pip install pytesseract
sudo apt-get install tesseract-ocr-deuNow that we’ve installed Tesseract let’s start detecting the text boxes.Tesseract has in built functionality to detect text boxes.
import pytesseract
from pytesseract import Output
import cv2
img = cv2.imread('receipt.jpg')
d = pytesseract.image_to_data(img, output_type=Output.DICT)
n_boxes = len(d['level'])
for i in range(n_boxes):
(x, y, w, h) = (d['left'][i], d['top'][i], d['width'][i], d['height'][i])
img = cv2.rectangle(img, (x, y), (x + w, y + h), (0, 0, 255), 2)
cv2.imshow(img,'img')Here’s the output of the text detection code.

Text Recognition
We will Tesseract to perform OCR. Tesseract 4 uses a deep learning approach that performs significantly better than most other open-source implementations.
Here’s the code of text recognition. Although it is a very simple one-liner, there’s a lot that goes under the hood.
extracted_text = pytesseract.image_to_string(img, lang = 'deu')Here’s the raw output.
'BerghotelnGrosse Scheideggn3818 GrindelwaldnFamilie R.MüllernnRech.Nr. 4572 30.07.2007/13:29: 17nBar Tisch 7/01n2xLatte Macchiato &ä 4.50 CHF 9,00n1xGloki a 5.00 CH 5.00n1xSchweinschnitzel ä 22.00 CHF 22.00nIxChässpätz 1 a 18.50 CHF 18.50nnTotal: CHF 54.50nnIncl. 7.6% MwSt 54.50 CHF: 3.85nnEntspricht in Euro 36.33 EURnEs bediente Sie: UrsulannMwSt Nr. : 430 234nTel.: 033 853 67 16nFax.: 033 853 67 19nE-mail: grossescheidegs@b luewin. ch'Here’s the formatted output
Berghotel
Grosse Scheidegg
3818 Grindelwald
Familie R.Müller
Rech.Nr. 4572 30.07.2007/13:29: 17
Bar Tisch 7/01
2xLatte Macchiato &ä 4.50 CHF 9,00
1xGloki a 5.00 CH 5.00
1xSchweinschnitzel ä 22.00 CHF 22.00
IxChässpätz 1 a 18.50 CHF 18.50
Total: CHF 54.50
Incl. 7.6% MwSt 54.50 CHF: 3.85
Entspricht in Euro 36.33 EUR
Es bediente Sie: Ursula
MwSt Nr. : 430 234
Tel.: 033 853 67 16
Fax.: 033 853 67 19
E-mail: grossescheidegs@b luewin. chNeed to digitize documents, receipts or invoices but too lazy to code? Head over to Nanonets and build OCR models for free!
As I’ve mentioned before the most common way of extracting information is by a rule-based approach.
All receipts from this hotel will follow a fixed structure and the information appears on different lines. This is reflected in the OCR output where newlines are represented by ‘n’. Using these let’s write a set of rules to extract information. This set of rules can be applied to any receipt from this hotel since they’ll follow the same format.
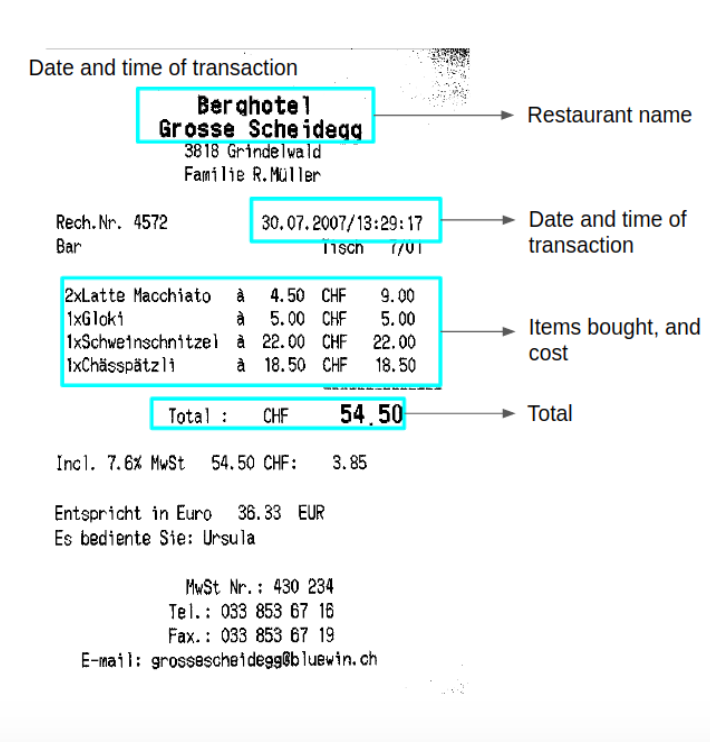
I will be extracting the Restaurant name, date of transaction, the items bought, their quantity, total costs per item and the total amount using simple python commands and regular expressions.
This is a dictionary where I’ll be storing the extracted information.
receipt _ocr = {}The first step is to extract the Restaurant name. The location of the restaurant name is going to be constant in all receipts and that is in the first 2 lines. Let’s use this to create a rule.
splits = extracted_text.splitlines()
restaurant_name = splits[0] + '' + splits[1]Next, we extract the date of transaction. Date regex is pretty straightforward.
import re
# regex for date. The pattern in the receipt is in 30.07.2007 in DD:MM:YYYY
date_pattern = r'(0[1-9]|[12][0-9]|3[01])[.](0[1-9]|1[012])[.](19|20)dd'
date = re.search(date_pattern, extracted_text).group()
receipt_ocr['date'] = date
print(date)
Output –
‘30.10.2007’
Next we extract all information related to the items and cost.
The items contain a CHF which is the swiss franc. Let’s detect all occurrences of CHF. Now we can detect lines by recognizing the characters between 2 n and containing a CHF. I’m detecting the total here also.
# get lines with chf
lines_with_chf = []
for line in splits:
if re.search(r'CHF',line):
lines_with_chf.append(line)
print(lines_with_chf)Output –
2xLatte Macchiato &ä 4.50 CHF 9,00
1xSchweinschnitzel ä 22.00 CHF 22.00
IxChässpätz 1 a 18.50 CHF 18.50
Total: CHF 54.50
Incl. 7.6% MwSt 54.50 CHF: 3.85If you notice, Tesseract missed one item out because it detected CH instead of CHF. I’ll be covering challenges in traditional OCR systems in the next section.
# get items, total, ignore Incl
items = []
for line in lines_with_chf:
print(line)
if re.search(r'Incl',line):
continue
if re.search(r'Total', line):
total = line
else:
items.append(line)
# Get Name, quantity and cost
all_items = {}
for item in items:
details = item.split()
quantity_name = details[0]
quantity = quantity_name.split('x')[0]
name = quantity_name.split('x')[1]
cost = details[-1]
all_items[name] = {'quantity':quantity, 'cost':cost}
total = total.split('CHF')[-1]
# Store the results in the dict
receipt_ocr['items'] = all_items
receipt_ocr[‘total’] = total
import json
receipt_json = json.dumps(receipt_ocr)
print(receipt_json)Printing our JSON output –
{'date': '30.07.2007', 'items': {'Chässpätz': {'cost': '18.50', 'quantity': 'I'}, 'Latte': {'cost': '9,00', 'quantity': '2'}, 'Schweinschnitzel': {'cost': '22.00', 'quantity': '1'}}, 'total': ' 54.50'}
All the key information has been extracted and dumped into receipt_json..
Problems with the conventional approach
Although we extracted the information, the above pipeline misses out on a few things and is sub optimal. For each new receipt we need to write a new set of rules and is thus not scalable.
There could be lots of variations in Layouts, font and font sizes, handwritten documents etc. Differences in layouts will affect rule-based approaches and these need to be accounted for, which becomes very tedious. Differences in Font and font sizes makes it difficult to recognize and extract information.
Why is an end-to-end Deep Learning pipeline better?
One of the biggest problems with the standard approach is the lack of generalization. Rule based approaches cannot generalize and new rules need to be written for any new template. Also any changes or variations in an existing template need to be accounted for too.
A Deep Learning approach will be able to learn these rules, and will be able to generalize across different layouts easily, provided we have them in our training dataset.
Deep Learning and Information Extraction
Here I review a few papers that use end-to-end Deep Learning approaches.
CUTIE
CUTIE: Learning to Understand Documents with Convolutional Universal Text Information Extractor
This paper proposes a learning-based key information extraction method with limited requirement of human resources. It combines the information from both semantic meaning and spatial distribution of texts in documents. Their proposed model, Convolutional Universal Text Information Extractor (CUTIE), applies convolutional neural networks on gridded texts where texts are embedded as features with semantical connotations.
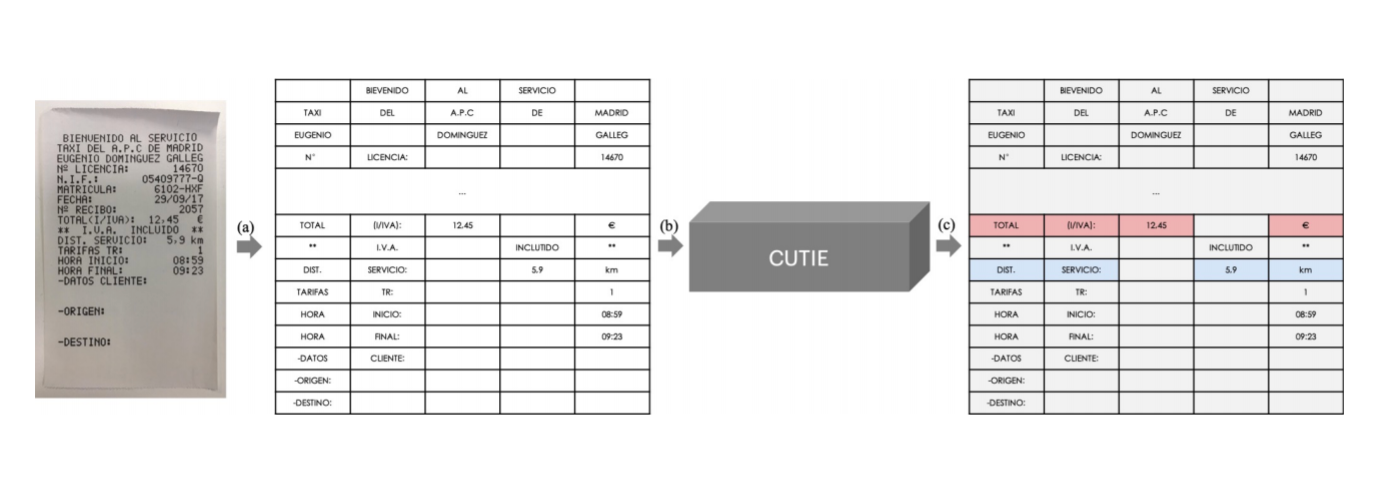
The proposed model, tackles the key information extraction problem by
- First creating gridded texts with the proposed grid positional mapping method. To generate the grid data for the convolutional neural network, the scanned document image are processed by an OCR engine to acquire the texts and their absolute/relative positions. The texts are mapped from the original scanned document image to the target grid, such that the mapped grid preserves the original spatial relationship among texts yet more suitable to be used as the input for the convolutional neural network.
- Then the CUTIE model is applied on the gridded texts. The rich semantic information is encoded from the gridded texts at the very beginning stage of the convolutional neural network with a word embedding layer.
The CUTIE allows for simultaneously looking into both semantical information and spatial information of the texts in the scanned document image and can reach a new state of the art result for key information extraction.
CUTIE Model
They have 2 models CUTIE-A and CUTIE-B. the proposed CUTIE-A is a high capacity convolutional neural network that fuses multi-resolution features without losing high-resolution features. CUTIE-B is a convolutional network with atrous convolution for enlarging the field of view and Atrous Spatial Pyramid Pooling (ASPP) module to capture multi-scale contexts. Both CUTIE-A and CUITE-B conducts semantical meaning encoding process with a word embedding layer in the very beginning stage.
The task of CUTIE bears resemblance to semantic segmentation task. The mapped grid contains scattered data points (text tokens) in contrast to the images bespread with pixels. The grid positional mapped key texts are either close to or distant to each other due to different types of document layouts. Therefore, incorporating multi-scale context processing ability benefits the network.
Dataset
The proposed method is evaluated on ICDAR 2019 robust reading challenge on SROIE dataset and is also on a self-built dataset with 3 types of scanned document images.
The ICDAR 2019 SROIE data set is used which contains 1000 whole scanned receipt images. Each receipt image contains around about four key text fields, such as goods name, unit price, date, and total cost. The text annotated in the dataset mainly consists of digits and English characters.
The self-built dataset contains 4, 484 annotated scanned Spanish receipt documents, including taxi receipts, meals entertainment (ME) receipts, and hotel receipts, with 9 different key information classes.
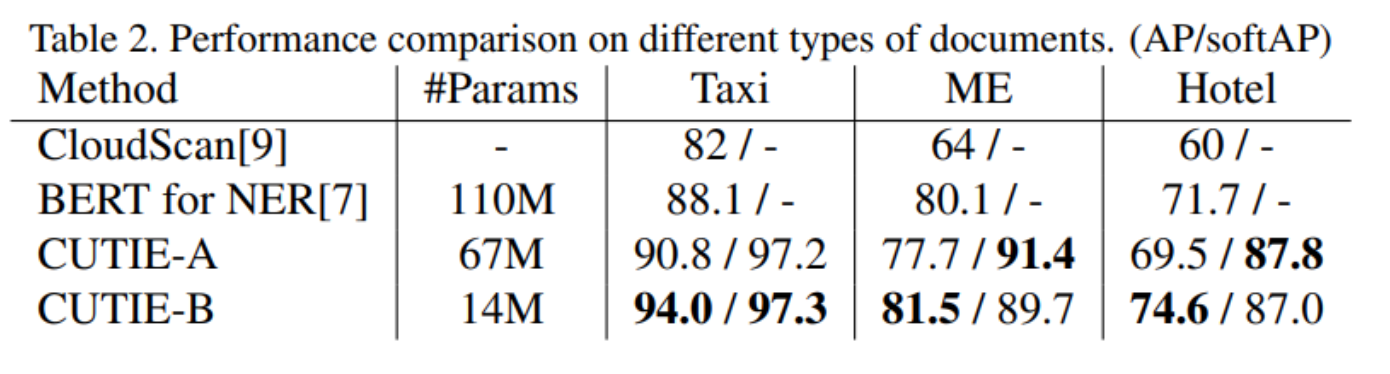
Results
The overall performance is evaluated using average precision (AP – and measured in terms of per-class accuracy across the 9 classes,.) and soft average precision (softAP) where the prediction of a key information class is determined as correct if positive ground truths are correctly predicted even if some false positives are included in the final prediction. joint analysis of AP and softAP provides a better understanding of the model performance.
You can see the results in the table below.
GCNs for VRDs
Graph Convolution for Multimodal Information Extraction from Visually Rich Documents
This paper introduces a graph convolution-based model to combine textual and visual information presented in Visually Rich documents (VRDs). Graph embeddings are trained to summarize the context of a text segment in the document, and further combined with text embeddings for entity extraction.
In this paper they call a document a VRD and I’ll be sticking with it.
Each document is modelled as a graph of text segments, where each text segment is comprised of the position of the segment and the text within it. The graph is comprised of nodes that represent text segments, and edges that represent visual dependencies, such as relative shapes and distance, between two nodes.
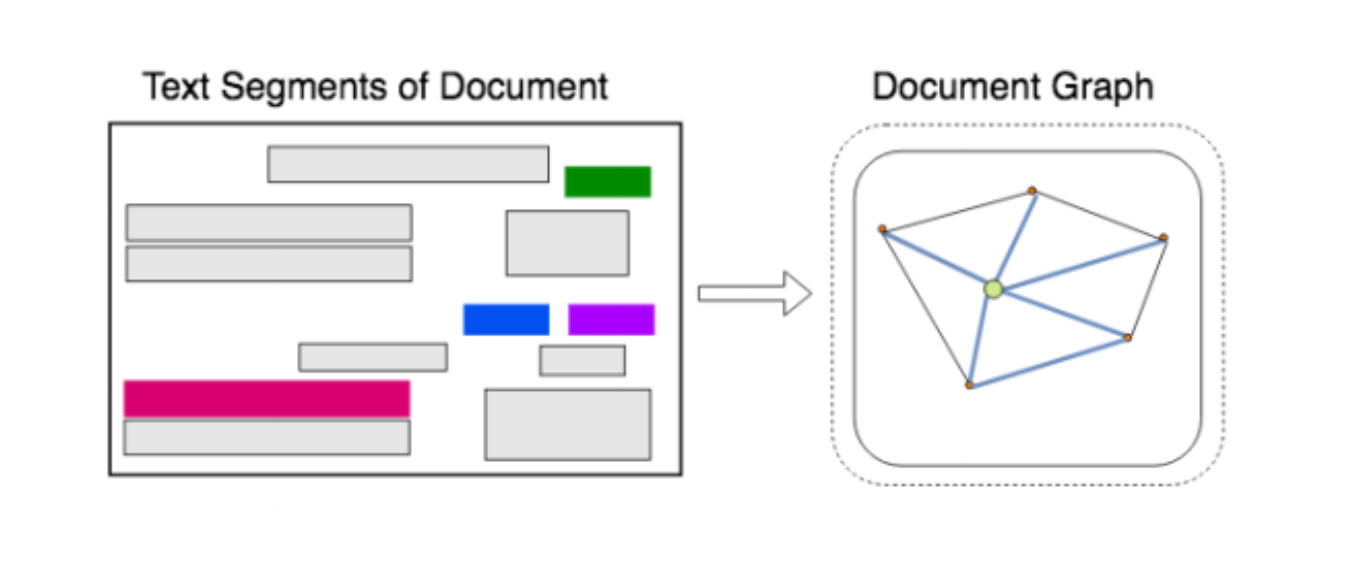
The graph embeddings produced by graph convolution summarize the context of a text segment in the document, which are further combined with text embeddings for entity extraction using a standard BiLSTM-CRF model.
Model
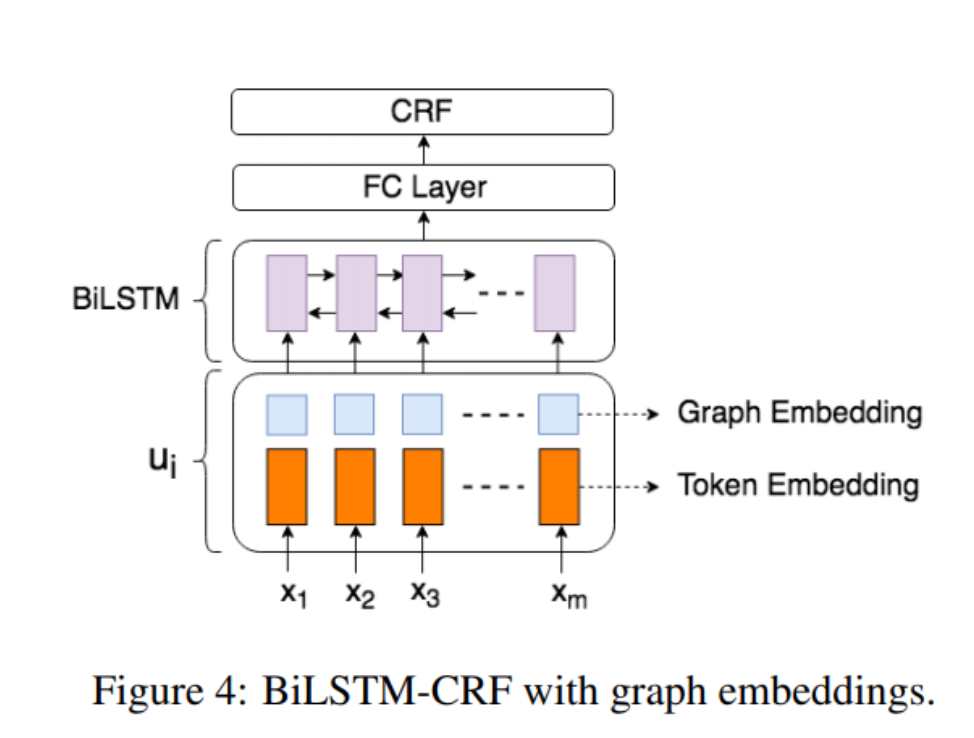
The model first encodes each text segment in the document into graph embedding, using multiple layers of graph convolution. The embedding represents the information in the text segment given its visual and textual context. Visual context is the layout of the document and relative positions of the individual segment to other segments. Textual context is the aggregate of text information in the document overall; The model learns to assign higher weights on texts from neighbor segments. Then the paper combines the graph embeddings with text embeddings and apply a standard BiLSTM-CRFmodel for entity extraction.
Dataset
Two real-world datasets are used. They are ValueAdded Tax Invoices (VATI) and International Purchase Receipts (IPR). VATI consists of 3000 user-uploaded pictures and has 16 entities to exact. Example entities are the names of buyer/seller, date and tax amount. The invoices are in Chinese, and it has a fixed template since it is national standard invoice.
IPR is a data set of 1500 scanned receipt documents in English which has 4 entities to exact (Invoice Number, Vendor Name, Payer Name and Total Amount). There exist 146 templates for the receipts.
Results
F1 score is used to evaluate the performances of the model in all experiment. The table below has the results on thr 2 datasets.
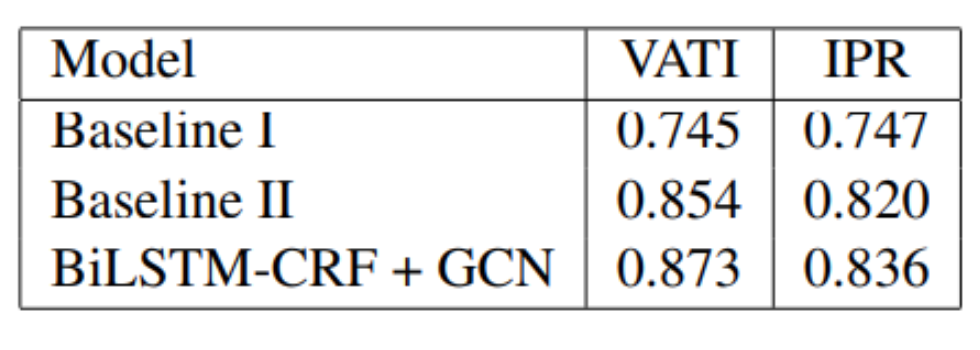
Baseline I applies BiLSTM-CRF to each text segment, where each text segment is an individual sentence.
Baseline II applies the tagging model to the concatenated text segments.
Faster-RCNN + AED
Deep Learning Approach for Receipt Recognition
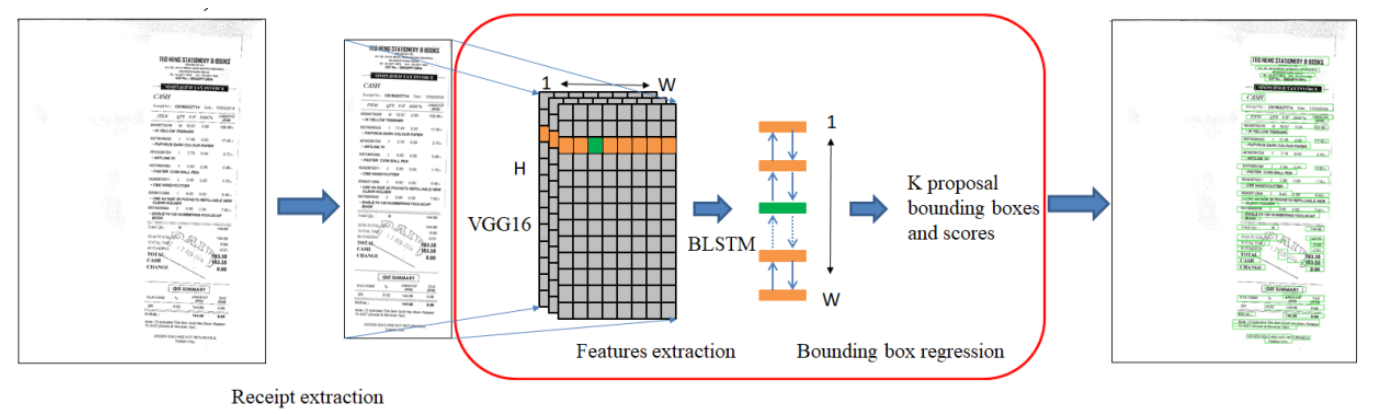
This paper presents a deep learning approach for recognizing scanned receipts. The recognition system has two main modules: text detection based on Connectionist Text Proposal Network and text recognition based on Attention-based Encoder-Decoder. The system achieved 71.9% of the F1 score for detection and recognition task.
Text detection
The CTPN structure is similar to Faster R-CNN, with the addition of the LSTM layer. The network model mainly consists of three parts: feature extraction by VGG16, bidirectional LSTM, and bounding box regression
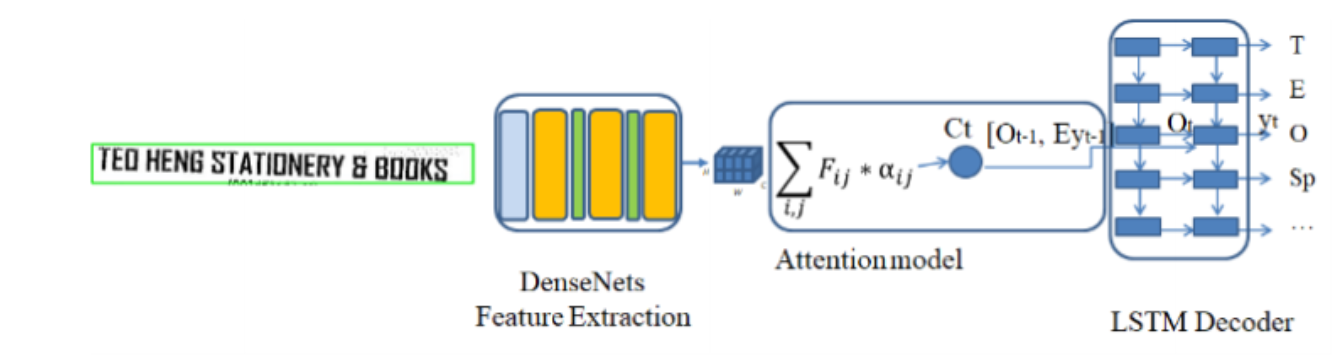
Text Recognition
The AED is used recognizing text lines. The AED has two main modules: DenseNet for extracting features from a text image and an LSTM combined with an attention model for predicting the output text.
Dataset
The dataset from SROIE 2019 is used. They divided the training data into training, validation, and testing and randomly selected 80% of receipts for training, 10% of receipts for validation, and the rest for testing. Resulting in 500 receipts for training, 63 receipts for validation, and 63 for testing.
Results
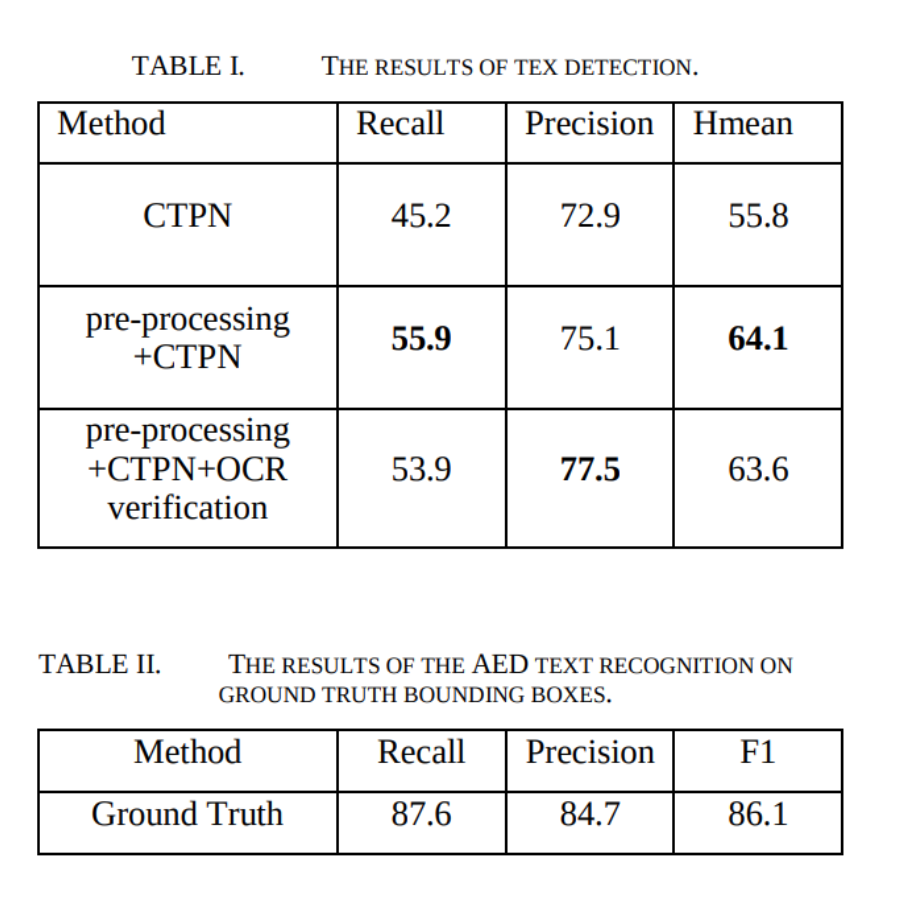
For text detection, the paper uses Tightness-aware Intersection-over-Union (TIoU)For text recognition, the paper used F1 , Precision and Recall.

Table I shows the result of CTPN with three conditions: CTPN on original images; pre-processing + CTPN, pre-processing + CTPN + OCR verification. Table 2 shows the results of the AED network.
There’s of course, an easier, more intuitive way to do this.
OCR with Nanonets
Update #1: We just released our receipt OCR pre-trained model. Head over to https://app.nanonets.com and start testing!

The Nanonets OCR API allows you to build OCR models with ease. You do not have to worry about pre-processing your images or worry about matching templates or build rule based engines to increase the accuracy of your OCR model.
You can upload your data, annotate it, set the model to train and wait for getting predictions through a browser based UI without writing a single line of code, worrying about GPUs or finding the right architectures for your deep learning models. You can also acquire the JSON responses of each prediction to integrate it with your own systems and build machine learning powered apps built on state of the art algorithms and a strong infrastructure.
Using the GUI: https://app.nanonets.com/
You can also use the Nanonets-OCR API by following the steps below:
Step 1: Clone the Repo, Install dependencies
git clone https://github.com/NanoNets/nanonets-ocr-sample-python.git
cd nanonets-ocr-sample-python
sudo pip install requests tqdm
Step 2: Get your free API Key
Get your free API Key from http://app.nanonets.com/#/keys
Step 3: Set the API key as an Environment Variable
export NANONETS_API_KEY=YOUR_API_KEY_GOES_HERE
Step 4: Create a New Model
python ./code/create-model.py
Note: This generates a MODEL_ID that you need for the next step
Step 5: Add Model Id as Environment Variable
export NANONETS_MODEL_ID=YOUR_MODEL_ID
Note: you will get YOUR_MODEL_ID from the previous step
Step 6: Upload the Training Data
The training data is found in images (image files) and annotations (annotations for the image files)
python ./code/upload-training.py
Step 7: Train Model
Once the Images have been uploaded, begin training the Model
python ./code/train-model.py
Step 8: Get Model State
The model takes ~2 hours to train. You will get an email once the model is trained. In the meanwhile you check the state of the model
python ./code/model-state.py
Step 9: Make Prediction
Once the model is trained. You can make predictions using the model
python ./code/prediction.py ./images/151.jpg
[ad_2]
Source link