
[ad_1]
Want to OCR handwritten forms? This blog is a comprehensive overview of the latest methods of handwriting recognition using deep learning. We’ve reviewed the latest research and papers as of 2020. We also build a handwriting reader from scratch.
Introduction
Optical Character Recognition(OCR) market size is expected to be USD 13.38 billion by 2025 with a year on year growth of 13.7 %. This growth is driven by rapid digitization of business processes using OCR to reduce their labor costs and to save precious man hours. Although OCR has been considered a solved problem there is one key component of it, Handwriting Recognition or Handwritten Text Recognition(HTR) which is still considered a challenging problem statement. The high variance in handwriting styles across people and poor quality of the handwritten text compared to printed text pose significant hurdles in converting it to machine readable text. Nevertheless it’s a crucial problem to solve for multiple industries like healthcare, insurance and banking.
Recent advancements in Deep Learning such as the advent of transformer architectures have fast-tracked our progress in cracking handwritten text recognition. Recognizing handwritten text is termed Intelligent Character Recognition(ICR) due to the fact that the algorithms needed to solve ICR need much more intelligence than solving generic OCR.
In this article we will be learning about the task of handwritten text recognition, it’s intricacies and how we can solve it using deep learning techniques.
Want to extract data from handwritten forms? Head over to Nanonets and start building form OCR models for free!
Challenges in Handwriting Recognition
- Huge variability and ambiguity of strokes from person to person
- Handwriting style of an individual person also varies time to time and is inconsistent
- Poor quality of the source document/image due to degradation over time
- Text in printed documents sit in a straight line whereas humans need not write a line of text in a straight line on white paper
- Cursive handwriting makes separation and recognition of characters challenging
- Text in handwriting can have variable rotation to the right which is in contrast to printed text where all the text sits up straight
- Collecting a good labelled dataset to learn is not cheap compared to synthetic data
Use cases
Healthcare and pharmaceuticals
Patient prescription digitization is a major pain point in healthcare/pharmaceutical industry. For example Roche is handling millions of petabytes of medical PDFs daily. Another area where handwritten text detection has key impact is patient enrollment and form digitization. By adding handwriting recognition to their toolkit of services, hospitals/pharmaceuticals can significantly improve user experience
Insurance
A large insurance industry receives more than 20 million documents a day and a delay in processing the claim can impact the company terribly. The claims document can contain various different handwriting styles and pure manual automation of processing claims is going to completely slow down the pipeline

Banking
People write cheques on a regular basis and cheques still play a major role in most non-cash transactions. In many developing countries, the present cheque processing procedure requires a bank employee to read and manually enter the information present on a cheque and also verify the entries like signature and date. As a large number of cheques have to be processed every day in a bank a handwriting text recognition system can save costs and hours of human work
Online Libraries
Huge amounts of historical knowledge is being digitized by uploading the image scans for access to the entire world. But this effort is not very useful until the text in the images can be identified which can be indexed, queried and browsed. Handwriting recognition plays a key role in bringing alive the medieval and 20th century documents, postcards, research studies etc.
Methods
Handwriting Recognition methods can be broadly classified into the below two types

- Online Methods :- Online methods involve a digital pen/stylus and have access to the stroke information, pen location while text is being written as the seen in the right figure above. Since they tend to have a lot of information with regards to the flow of text being written they can be classified at a pretty high accuracy and the demarcation between different characters in the text becomes much more clear
- Offline Methods :- Offline methods involve recognizing text once it’s written down and hence won’t have information to the strokes/directions involved during writing with a possible addition of some background noise from the source i.e paper.
In real world it’s not always possible/scalable to carry a digital pen with sensors to capture stroke information and hence the task of recognizing text offline is a much more relevant problem. Thus, now we will discuss various techniques to solve the problem of recognizing offline text.
Techniques
The initial approaches of solving handwriting recognition involved Machine Learning methods like Hidden Markov Models(HMM), SVM etc. Once the initial text is pre-processed, feature extraction is performed to identify key information such as loops, inflection points, aspect ratio etc. of an individual character. These generated features are now fed to a classifier say HMM to get the results. The performance of machine learning models is pretty limited due to manual feature extraction phase and their limited capacity of learning. Feature extraction step varies for every individual language and hence is not scalable. With the advent of deep learning came tremendous improvements in accuracy of handwriting recognition. Let’s discuss few of the prominent research in the area of deep learning for handwriting recognition
Multi-dimensional Recurrent Neural Networks
RNN/LSTM as we know can deal with sequential data to identify temporal patterns and generate results. But they are limited to dealing with 1D data and hence won’t be directly applicable to image data. To solve this problem, the authors in this paper proposed a multi-dimensional RNN/LSTM structure as can be seen in the figure below
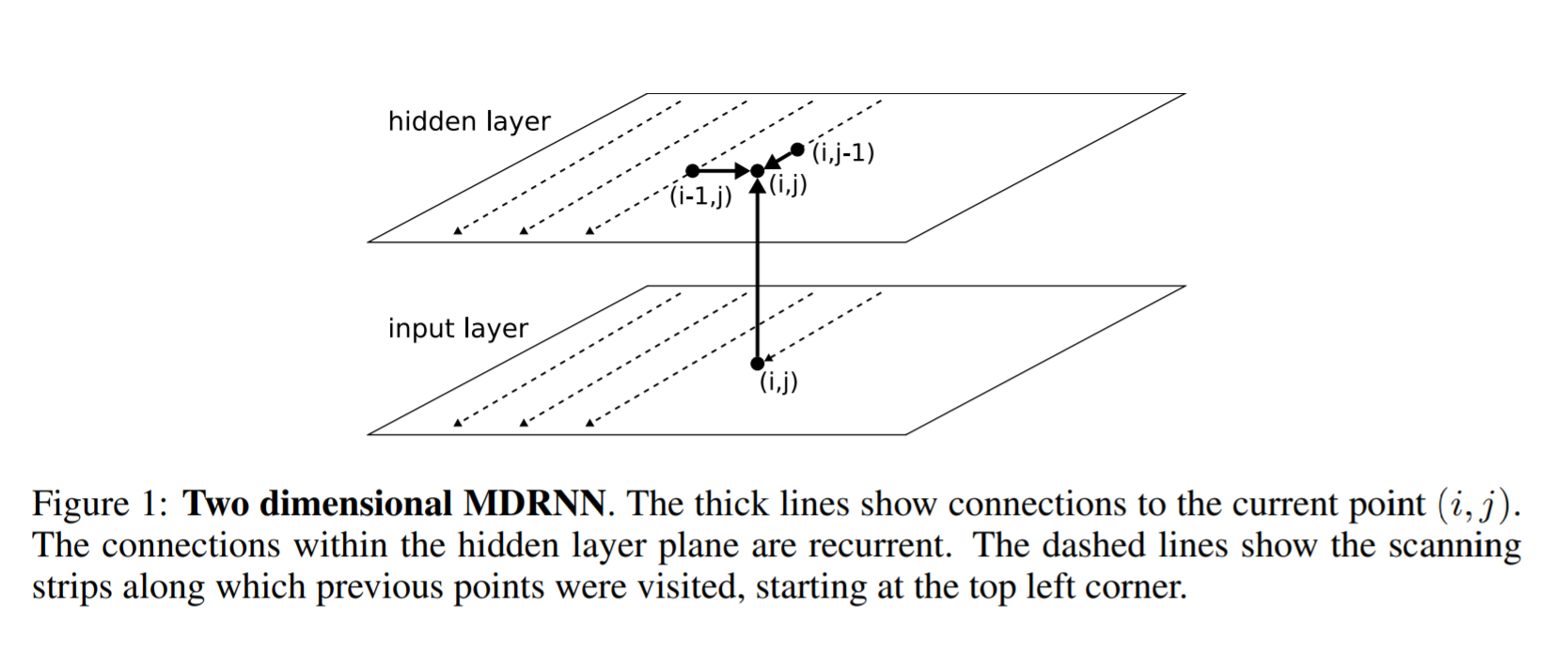
The following is the difference between a general RNN and a multi-dimensional RNN. In a general RNN, hidden layer say i receives state from a previous hidden layer in time i-1. In Multi-dimensional RNN say for example a 2 dimensional RNN, the hidden layer (i, j) receives states from multiple previous hidden layers i.e (i-1, j) and (i, j-1) and thus captures context from both height and width in an image which is pivotal for getting a clear understanding of the local region by a network. This is further extended to get information not only from previous layers but also from future layers similar to how a BI-LSTM receives information from t-1 and t+1. Similarly a 2D MDRNN hidden layer i can now receive information (i-1, j), (i, j-1), (i+1, j), (i, j+1) thus capturing context in all directions

The entire network structure is shown above. MDLSTM is used which is nothing but replacing RNN block with a LSTM block from the above discussion of MDRNN. The input is divided into blocks of size 3×4 which is now fed into MDSTM layers. The network has a hierarchical structure of MDLSTM layers followed by feed-forward(ANN) layers in tandem. Then the final output is converted into a 1D vector and is given to CTC function to generate output
Connectionist Temporal Classification(CTC) is an algorithm used to deal with tasks like speech recognition, handwriting recognition etc. where just the input data and the output transcription is available but there are no alignment details provided i.e how a particular region in audio for speech or particular region in images for handwriting is aligned to a specific character. Simple heuristics such as giving each character same area won’t work since the amount of space each character takes varies in handwriting from person to person and time to time.
For our handwriting recognition use-case consider the input image regions for a particular sentence as input X=[x1,x2,…,x**T] while expected output as Y=[y1,y2,…,y**U] . Given X we are supposed to find accurate Y. CTC algorithm works by taking input X and giving distribution over all possible Y’s using which we can make a prediction for final output.
CTC uses a basis character say – to differentiate between duplicate characters and repeated characters in a input region. For example a particular character can span multiple regions of input and thus CTC would output the same character consecutively. Example:- Input james and Output of CTC is jjaammmees. The final output is derived by collapsing the repeated outputs and hence we get james. But now to present duplicate characters say ‘l’ in hello, we need to have a separation in place and thus all outputs are separated by hyphen(-). Now the output for hello could be h-ee-ll-lll-oo which if collapsed will become hello and not helo. More information on how CTC works can be seen here CTC.
While decoding the output of CTC based on the simple heuristic of highest probability for each position, we might get results which might not make any sense in the real world. To solve this we might employ a different decoder to improve the results. Let’s discuss different types of decodings
- Best-path decoding :- This is the generic decoding we have discussed so far. At each position we take the output of the model and find the result with the highest probability.
- Beam search decoding :- Instead of taking a single output from the network every time beam search suggests keeping multiple output paths with highest every probabilities and expand the chain with new outputs and dropping paths having lesser probabilities to keep the beam size constant. The results obtained through this approach are more accurate than using the greedy approach
- Beam search with Language Model :- Beam search provides more accurate results than grid search but still it won’t solve the problem of having meaningful results. To solve this we can use a language model along with beam search using both probabilities from the model and the language model to generate final results.
More details in generating accurate decoding results can be looked at in this article
Encoder-Decoder and Attention Networks
Seq2Seq models having Encoder-decoder networks have recently been popular for solving the tasks of speech recognition, machine translation etc and thus have been extended to solve the use-case of handwriting recognition by deploying an additional attention mechanism. Let’s discuss some seminal research in this area
Scan, Attend and Read
In this seminal work Scan, Attend and Read(SAR) the authors propose the usage of an attention-based model for end-to-end handwriting recognition. The main contribution of the research is the automatic transcription of text without segmenting into lines as a pre-processing step and thus can scan an entire page and give results.
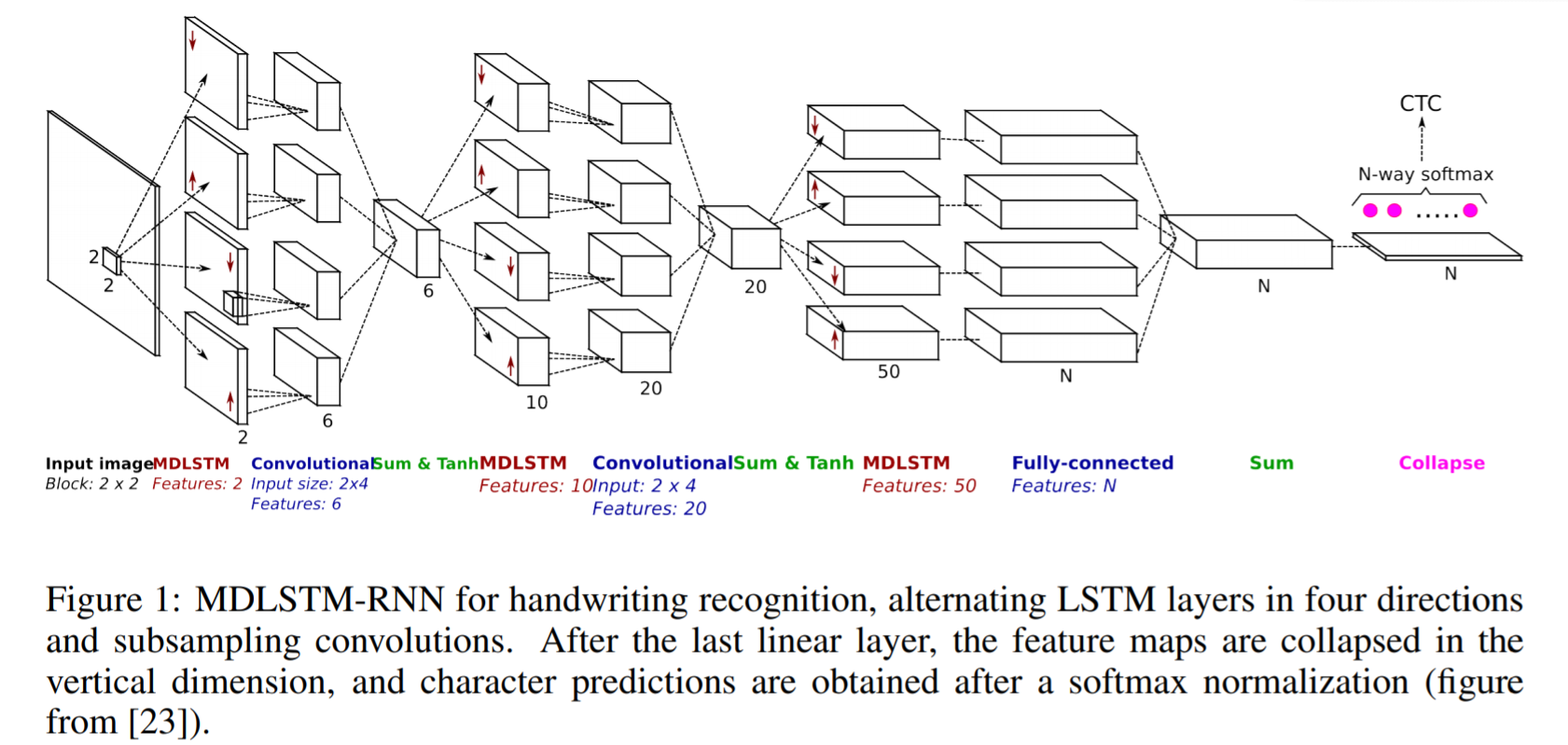
SAR uses MDLSTM based architecture similar to the one we discussed above with one small change at the final layer. After the last linear layer i.e the final Sum block in figure above, the feature maps are collapsed in the vertical dimension and a final softmax function is applied to get the outputs.
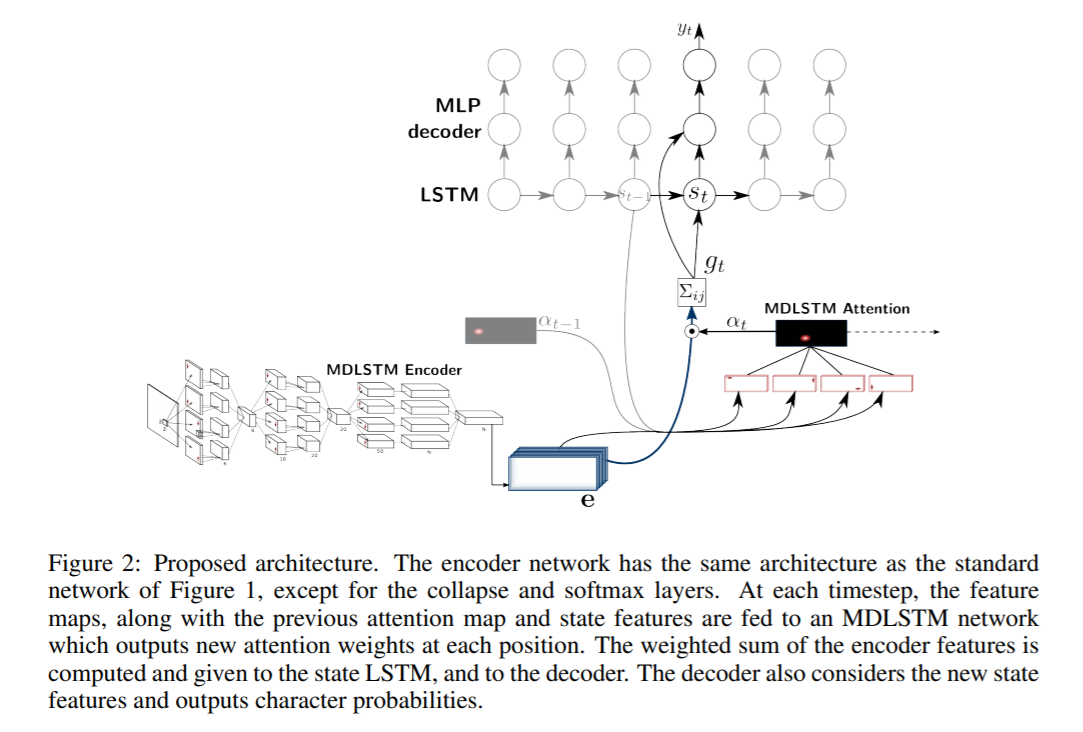
SAR architecture consists of a MDLSTM architecture which acts as the feature extractor. The final collapsing module with a softmax output and CTC loss is replaced by an attention module and a LSTM decoder. The attention model used is a hybrid combination of content based attention and location based attention which is explained in more detail in the next paper. The decoder LSTM modules take the previous state, previous attention map and the encoder features to generate the final output character and the state vector for next prediction.
Convolve, Attend and Spell
This paper proposes an attention based sequence-to-sequence model for handwritten word recognition. The proposed architecture has three main parts: an encoder, consisting of a CNN and a bi-directional GRU, an attention mechanism devoted to focus on the pertinent features and a decoder formed by a one-directional GRU, able to spell the corresponding word, character by character.
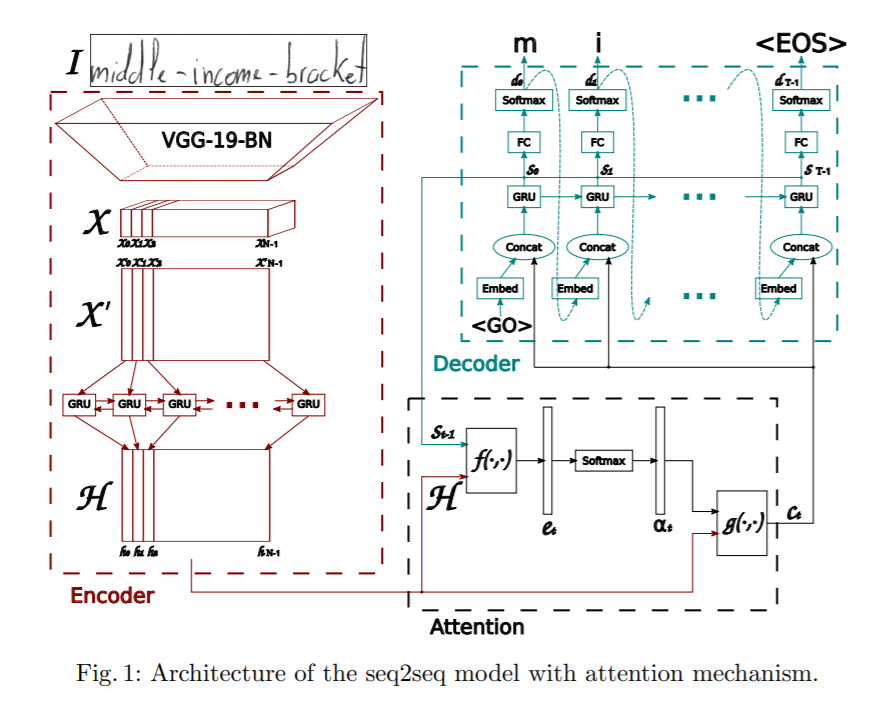
The encoder uses a CNN to extract visual features. A pre-trained VGG-19-BN architecture is used as a feature extractor. The input image is converted into feature map X which is then reshaped into X’ by splitting all channels column wise and combining them to get the sequential information. X’ is further converted to H by using a bi-directional GRU. GRU is a neural network similar to LSTM in nature and can capture temporal information.
Further an attention model is employed while predicting the output from the decoder. The paper discusses two different types of attention mechanisms explored.
- Content-based Attention :- The idea behind this is to find the similarity between the current hidden state of the decoder and the feature map from encoder. We can find the most correlated feature vectors in the feature map of the encoder, which can be used to predict the current character at the current time step. More details into how attention mechanism works can be seen from here Attention
- Location-based Attention :- The main disadvantage of Content-based Location mechanisms is that there is an implicit assumption that the location information is embedded in the output of the encoder. Otherwise there is no way to differentiate between character outputs which are repeated from the decoder. For example consider a word Charmander, the character a is repeated twice in it and without location information the decoder won’t be able to predict them as separate characters. To alleviate this the current character and it’s alignment is predicted by using both the encoder output and previous alignment. More details onto how location based attend works can be seen here.
The decoder is a one-directional multi-layered GRU. At each time step t it receives input from previous time step and the context vector from the attention module. Multinomial Decoding and label smoothing are explored at training to improve generalization capability.
Transformer Models
Although encoder-decoder networks have been pretty good in achieving results for handwriting recognition they have a bottleneck in training due to the LSTM layers involved and hence can’t be parallelized. Recently transformers have been pretty successful and replaced LSTM in solving various language related tasks. Let’s discuss now how transformer based models can be applied for handwriting recognition.
Pay Attention to What You Read
In this work the authors proposed usage of a transformer based architecture using multi-headed attention self-attention layers at both visual and text stages and thus can learn both character recognition as well as language-related dependencies of the character sequences to be decoded. Since the language knowledge is embedded into the model itself, there is no need for any additional post-processing step using a language model and hence has the capability to predicts outputs which are not part of vocabulary. To achieve this text encoding happens at a character level and not word level. As the transformer architecture allows training the model in parallel for every region or character, the training process is much simplified.
The network architecture consists of the following components
- Visual encoder :- To extract relevant features and apply multi-headed visual self-attention on different character locations
- Text Transcriber :- It does the task of taking the text input, encoding it, applying multi-headed language self-attention and applying mutual attention on both visual and text features.
Visual Encoder
Resnet50 backbone is to used to extra the features as can be seen in the figure above. The 3 dimensional feature map output from Resnet50 Fc is passed to Temporal Encoding module which reshapes to 2d by keeping the same width and hence the shape of (f x h, w). This is fed into a fully connected layer to reduce the shape to (f, w) and the resultant output is Fc’. In addition a positional encoding TE is added to Fc’ to retain the position information as mentioned in Transformer paper by Vaswani. More info of how transformer architecture is designed can be seen here. The output is passed through a fully connected layer to get the final feature map with shape (f , w). The final output is passed through a multi-headed attention module with 8 heads to get visual rich feature map
Text Transcriber
The input text is passed through an encoder which generates character level embeddings. These embeddings are combined with temporal location similar to the way in Visual Encoder using a Temporal Encoder module. This result is then passed to a Multi-Head Language Self-Attention module which is similar to attention module in Visual encoder. The text features generated along the visual features from visual encoder are passed to a mutual-attention module whose task is to align and combine the learned features from both images and the text inputs. The output is passed through a softmax function to get the final result.
When evaluating on test data, the transcriptions are not available. Thus only the start token < S > is passed as input and the first predicted character is fed back to the system, which outputs the second predicted character. This inference process is repeated in a loop until the end of sequence symbol < E > is produced or when the maximum output length N is reached.
Handwriting Text Generation
Handwriting Text Generation is the task of generating real looking handwritten text and thus can be used to augment the existing datasets. As we know deep learning requires a lot of data to train while obtaining huge corpus of labelled handwriting images for different languages is a cumbersome task. To solve this we can use Generative Adversarial Networks to generate training data. Let’s discuss one such architecture here
ScrabbleGAN
ScrabbleGAN follows a semi-supervised approach to synthesize handwritten text images that are versatile both in style and lexicon. It has the capability to generate images of varying length. The generator also can manipulate the resulting text style which allows us to decide whether the text has to be cursive or say how thick/thin should be the pen stroke
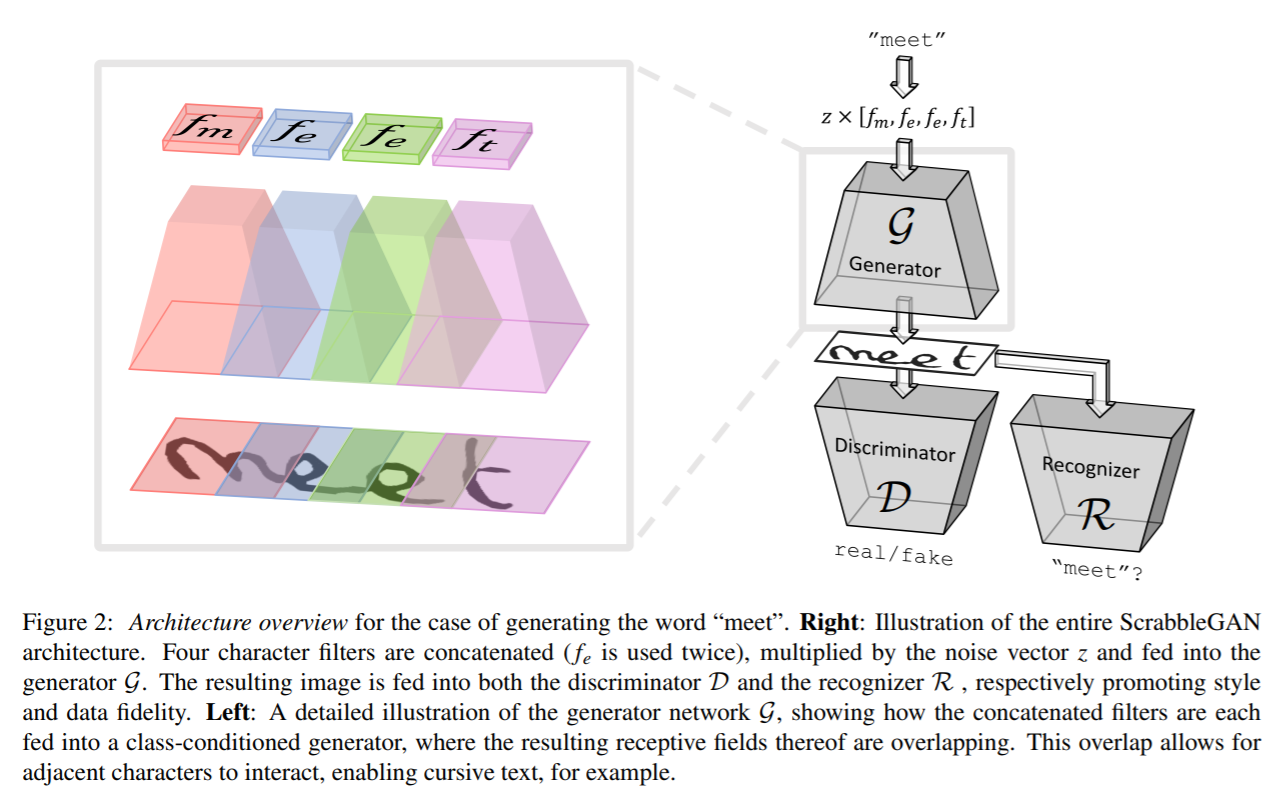
The architecture consists of a fully convolutional generator based on BigGAN. For each character in the input a corresponding filter is chosen and all the values are concatenated together which is then multiplied by a noise vector z which controls the generated text style. As can be seen above, the regions generated for each individual character overlap thus helping in generating connected recursive text as well as allowing the flexibility of different characters size. For example m takes up much of the space while e and t take limited area. In order to keep the same style for entire word or sentence, the style vector z is kept constant for all characters.
A convolutional discriminator based on BigGAN architecture is used to classify if the generate style of images is looking fake or real. The discriminator doesn’t rely on character level annotations and hence is not based on a class conditional GAN. The advantage of this being there is no need for labelled data and hence data from unseen corpus which is not part of training data can be used for training discriminator. Along with the discriminator a text recognizer R is trained to classify if the text generated makes real world sense or if it’s gibberish. The recognizer is based on CRNN architectures with the recurrent head removed to make the recognizer a little weaker and not recognize text even if it is unclear. The text generated in the output of R is compared with the input text given to generator and a corresponding penalty is added to loss function.
The outputs generated by ScrabbleGAN are shown below

Datasets :-
- IAM :- IAM dataset contains about 100k images of words from the English languagewith words written by 657 different authors. The train, test and validation set contain words written by mutually exclusive authorsLink :- http://www.fki.inf.unibe.ch/databases/iam-handwriting-database
- CVL :- The CVL dataset consists of seven handwritten documents written by about 310 participants, resulting in about 83k word crops, divided into train and test setsLink :- https://cvl.tuwien.ac.at/research/cvl-databases/an-off-line-database-for-writer-retrieval-writer-identification-and-word-spotting/
- RIMES :- Contains words from the French language of about 60k images and written by 1300 authors corresponding to about 5 mails written by each person.Link :- http://www.a2ialab.com/doku.php?id=rimes_database:start
Metrics :-
Character Error Rate :- It is computed as the Levenshtein distance which is the sum of the character substitutions (Sc), insertions (Ic) and deletions (Dc) that are needed to transform one string into the other, divided by the total number of characters in the groundtruth (Nc)
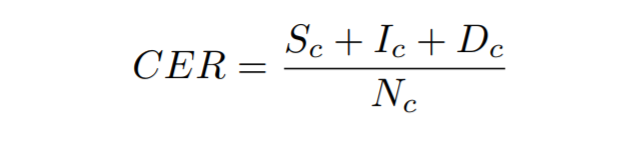
Word Error Rate :- It is computed as the sum of the word substitutions (Sw), insertions (Iw) and deletions (Dw) that are required to transform one string into the other, divided by the total number of words in the groundtruth (Nw)
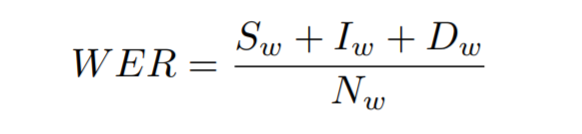
Train your own handwriting recognition model
Now let’s see how we can train our own handwritten text recognition model. We will be training on IAM dataset but you can train the model on your own dataset as well. Let’s discuss the steps involved in setting this up
Data
To download IAM dataset register from here. Once registered download words.tgz from here. This contains a dataset of handwritten word images. Also download the annotation file words.txt from here.
If you want to use your own dataset you need to follow the data structuring of IAM dataset.

The above shows how AIM dataset folder structure looks. Here a01, a02 etc. represent the parent folders each having sub-folders of data. Each sub-folder has a set of images having name of the folder added as a prefix to it’s file name.
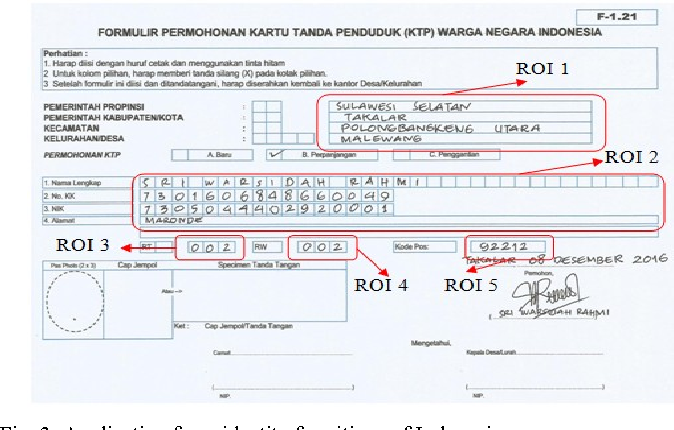
In addition we need an annotation file to mention the paths to the images files and the corresponding transcriptions. Consider for example the above image with text nominating, the below would be the representation in annotation file words.txt
a01-000u-01-00 ok 156 395 932 441 100 VBG nominating
- a01-000u-01-00 -> word id for a line in form a01-000u
- ok/err -> Indicator of quality of segmentation output
- 156 -> grey level to binarize the line containing this word
- 395 932 441 100 -> bounding box around this word in x,y,w,h format
- VBG -> the grammatical tag for this word. Here it is Verb Gerund
- nominating -> the transcription for this word
Architecture :-
We will be training a CRNN based architecture with CTC loss. A CNN is used to extract the visual features which are passed to a RNN and a CTC loss is applied to the end with a greedy decoder to get the output.

Training
We shall be using the CRNN code from here to train our model. Follow the steps from below to prepare the data
python checkDirs.py
Run above command and you should see an output like below
[OK] words/
[OK] words/a01/a01-000u/
[OK] words.txt
[OK] test.png
[OK] words/a01/a01-000u/a01-000u-00-00.png
Now you are all set to start training.
Go to root directory and execute
python main.py --train
Results
After training for about 50 epochs the Character Error Rate(CER) is 10.72 % while the Word Error Rate(WER) is 26.45 % and hence Word Accuracy is 73.55% . Some of the predictions can be seen in the below figure.

The model is able to predict the characters accurately to a great extent but it suffers in few cases such as awfully is predicted as anfully, stories is predicted as staries. These issues can be resolved by employing a language model as a post processing step along with the decoder which can generate meaningful words and rectify simple mistakes.
Summary
Although there have been significant developments in technology which help in better recognition of handwritten text, HTR is a far from a solved problem compared to OCR and hence is not yet extensively employed in industry. Nevertheless with the pace of technology evolution and with the introduction of models like transformers, we can expect HTR models to become a commonplace soon.
To catch more research on this topic you can get started from here
[ad_2]
Source link