
[ad_1]
This tutorial blog examines some of the use cases of key-value pair extractions, the traditional and current approaches to solve the task, and a sample implementation with code.

Key-Value Pairs or KVPs are essentially two linked data items, a key, and a value, where the key is used as a unique identifier for the value. A classic example of KVP data is the dictionary: the vocabularies are the keys, and the definitions of the vocabularies are the values associated with them. In fact, these pairs of data can exist in various types of text documents; in forms, the keys are the data types/questions (eg. Name, Age), and the values are the actual attributes you fill in correspondingly; in invoices, the keys are the items purchased, and the values could be the prices for different items.

However, unlike tables, KVPs could often exist in unstructured data or unknown formats and are sometimes even partially handwritten. For instance, when you fill in a form, the key aspects could be pre-printed as boxes, and the values are handwritten by you when completing it. Manual data extractions from such documents could be daunting and error-some, not to mention the difficulty when these documents are scanned in as images instead of machine-encoded texts. Thus, finding the underlying structures to automatically perform KVP extraction may drastically improve efficiencies for both personal and industrial usages.
The applications of efficient KVP extraction can be roughly categorized into personal and business uses. The following section provides an overview of several major use cases where fast and accurate data retrieval can be greatly beneficial.
Personal

While automation is mostly used for large-scale productions, a fast and accurate key-value extraction can also be beneficial to small parties and personal usages to improve the organization and efficiency of our daily routine.
ID-scanning and data conversion:
Personal IDs are typical examples of documents that contain various KVPs, from the given name to date of birth. When needed for online applications, we often have to manually find and type in the information, which could be dull and repetitive. KVP extractions from images of the ID can allow us to quickly convert data into machine-understandable texts. Finding the matching fields for different values will then become a trivial task for programs, and the only manual effort required would be to just scan through for double-checking.
Invoice data extraction for budgeting:
Budgeting is an important aspect of our personal routine. While the development of excel and spreadsheets have already made such irritable tasks simpler, a KVP extraction of items purchased and their corresponding prices from merely an image of the invoice can speed up the entire process even faster. Structured data and numbers can allow us to quickly perform analysis and watch out for purchases that are beyond our affordability.
Businesses/Industries

Both industries and corporations have to deal with thousands of paperwork with similar formats a day. From applications to asset management, these document information retrieval processes are often labor-intensive. Hence, automation on the initial step of extracting key-value pairs within unformatted data can significantly reduce the redundancy of human resources, while simultaneously ensuring the reliability of the data retrieved.
Automation of document scanning:
Governments or large businesses such as banks process a large number of handwritten forms with identical formats for various purposes (eg. Visa application, bank transfer). Retrieving the handwritten information out of the forms and converting it into digital documents via human effort could be an extremely repetitive and boring task that consequently leads to frequent minor errors. A proper KVP extraction pipeline of converting handwritten data into corresponding values of different keys, then inputting into large-scale systems can not only reduce such errors but also save extra labour expenditures.
Survey collection and statistical analysis:
Companies and Non-Governmental Organisations (NGOs) may often require feedbacks from customers or citizens in general to improve on their current product or promotional plans. To comprehensively evaluate the feedbacks, statistical analysis is often required. Yet, the similar problem of converting unstructured data and handwritten surveys into numerical figures that could be used for calculations still exists, and hence KVP extraction plays a crucial role in converting images of these surveys into analyzable data.
Traditional Approach
The most important element of KVP extraction and finding the underlying useful data is the Optical Character Recognition (OCR) process. In simple words, OCR is the electronic conversion of scanned images and photos into machine-encoded texts for further computations.
Before the accuracy of deep learning meets the needs of the markets for such tasks, OCRs are performed with the following procedure:
- Collect a database of known types (eg. letters and symbols)
- Use a photosensor to gather the points/features from an image
- Compare the points retrieved from the photosensors with the physical attributes of letters and symbols
- Convert the set of points into the known types after finding the highest similarity attributes
While this method appears to be effective most of the time, there exist two major restrictions from the traditional approach:
Requiring templates and rules for different document types:
By using only alignments of physical attributes, it is still hard to determine the boxes or the formats the forms are created, and thus the KVP extraction may still require extra templates or rules in order to capture the necessary data.
Easily flawed due to difficult handwriting:
Alignments of physical attributes become error-prone when the handwritings differ too much in terms of size and style. As these handwritten characters are unknown before they are actually seen, it is not possible for them to be part of the database either. This often requires OCRs to perform more sophisticated algorithms besides attribute-matching for better accuracy.
However, despite these obstacles making KVP extractions from scanned documents seemingly hitting a dead end, the recent rise of deep learning has shed light on new and creative approaches to the problem.
Deep Learning in Action
Deep learning is one of the major branches of machine learning that gained popularity in the past decades. Unlike traditional computer science and engineering approaches, where we design the system that receives an input to generate an output, deep learning hopes to rely on the inputs and outputs to design an intermediate system that can be extended to unseen inputs by creating a so-called neural network.

A neural network is an architecture that is inspired by the biological function of the human brain. The network consists of multiple layers, each layer containing numerous artificial neurons and activation functions. Inputs such as images are feeded forward to create a prediction, and the prediction error is backpropagated to change the weights throughout the network.
As the capacity of GPUs and memories drastically advanced, deep learning has become the favorable strategy in recent years which ignited creative variations of neural networks. One of the most typical neural networks used today, especially in the domain of computer vision is the convolutional neural network (CNN). CNNs are essentially convolutional kernels that slide through the image to extract features, which are often accompanied by traditional network layers to perform tasks such as image classification or object detection.
With some basic understanding of deep learning, the following section goes through several deep learning approaches for KVP extraction.
Tesseract OCR Engine
Recent OCR techniques have also incorporated deep learning models to achieve higher accuracy. The Tesseract OCR engine currently maintained by Google is one of the examples that utilises a particular type of deep learning network: a long short-term memory (LSTM).
What is LSTM?
An LSTM is a particular family of networks that are applied majorly to sequence inputs. The intuition is simple — for data that are sequential, such as stocks or weather forecasting, previous results may be important indicators for the next input, and hence it will be beneficial to consistently pass in information from prior data points for new predictions. Likewise, for letter detection in OCR, previously detected letters may be helpful in determining whether the less letter predicted in line makes sense (eg. If the letter “D” and “o” are detected, “g” has a much higher likelihood of being the next letter in line than “y”, even though they may look similar).
Tesseract Architecture
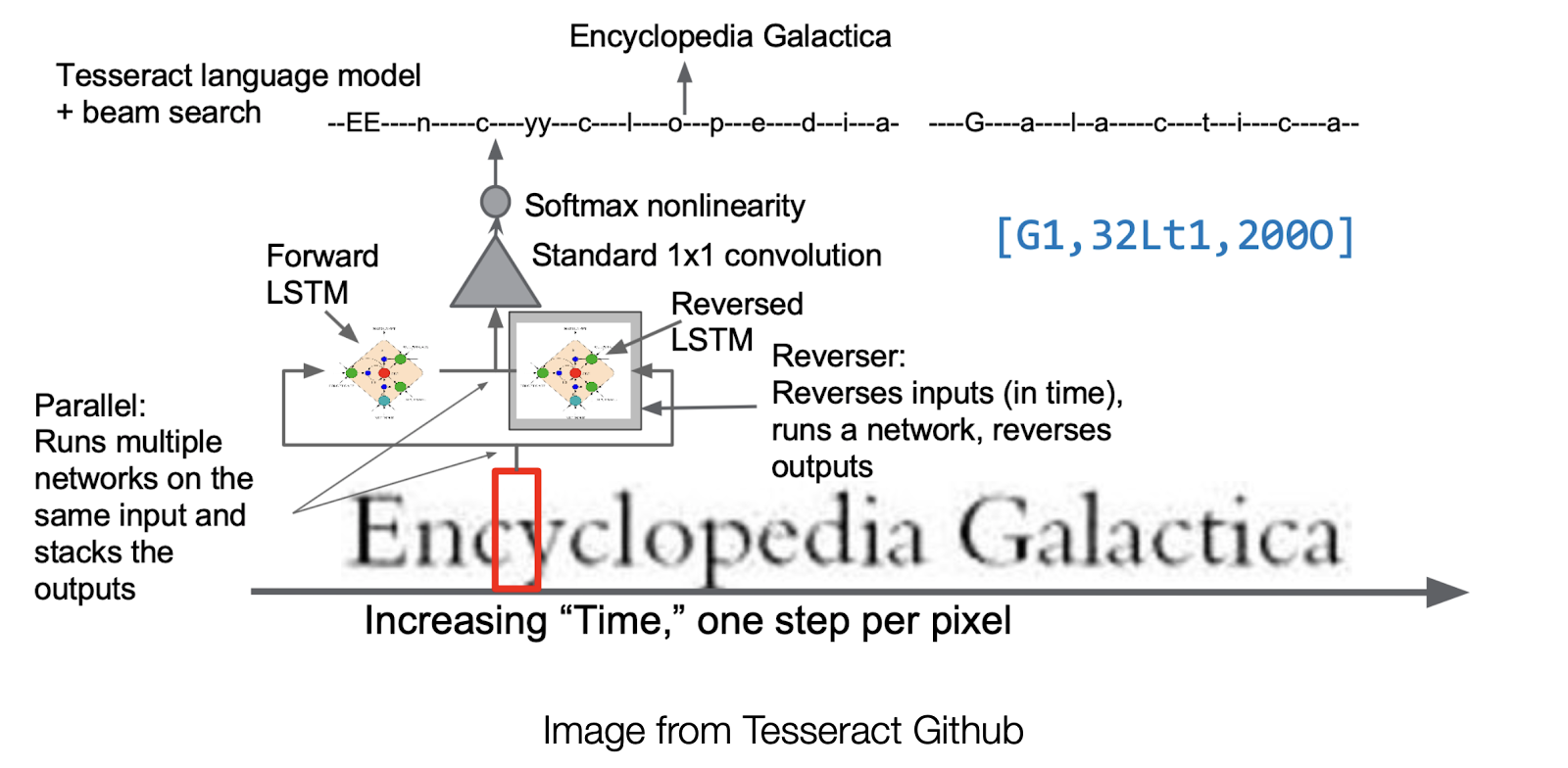
The above figure is the detailed architecture of the current Tesseract V4. A small bounding box is moved forward pixel by pixel with time. The image bounded by the box is extracted to pass through both a forward and backward LSTM, followed by a convolution layer for the final output.
How does it help with KVP Extraction?
The improved architecture makes the accuracy and robustness of the OCR much higher, and hence easier to convert multiple different types of texts into one structured, electronic document. These electronic documents with machine-readable strings are much easier to be organised for KVP extraction.
Deep Reader
Besides leading the advancements in OCR, deep learning also created opportunities for exploration. Deep Reader, a workshop paper from the top CS conference ACCV*, is one of the examples that utilises neural networks to recognise shapes and formats extending beyond just words and symbols of a scanned document. Such techniques can be particularly helpful in tasks such as KVP extraction.
*Side Note: The best research papers from the computer science domain are usually published in top-tier conferences. Acceptance into such conferences symbolises an approval and recognition of by experts within the field. The Asian Conference on Computer Vision (ACCV) is one of the recognised conferences within the domain of computer vision.
What is Deep Reader?
In simple words, Deep Readers attempts to tackle the ongoing problem of insufficient information retrieval when extracting only words and texts alone by also finding the visual entities such as lines, tables, and boxes within these scanned documents. For every image, Deep Reader denoises the image, identifies the document, and processes the handwritten text with a deep-learning approach before detecting and extracting meaningful texts and shapes. These features are then used to retrieve tables, boxes, and most importantly, KVPs.
Pre-processing
Prior to extracting textual entities, Deep Reader performs several pre-processing steps to ensure best quality retrieval in the latter parts:
- Image De-noising: Deep Reader adopts a generative adversarial network (GAN) to generate a de-noised version of an input. GAN, first developed by Ian et al. in 2014, is a neural network that comprises two sub-networks — a generator and a discriminator. Once an input is given, the generator generates an image based on the input, and the discriminator tries to distinguish between the ground truth and the generated input. Upon training-completion, a generator can successfully generate an image based on the input that is close to the actual ground truth. In this case, the GAN, given pairs of images (one de-noised and one noised), attempts to learn how to generate the de-noised version of the image from the perturbed one.
- Document Identification: In order to accurately retrieve visual entities, Deep Reader also attempts to classify the scanned documents into one of the templates via a convolutional Siamese network. The Siamese network consists of two identical convolutional layers that accept images of the scanned document and templates as inputs respectively, then compute the similarity between the two. The highest similarity among all comparisons implies that the document is based on the template.
- Processing Handwritten Text: To tackle the problem of recognising handwritten texts, Deep Reader also adopts a handwritten text recognition through an encoder-decoder to map the handwritten texts into sets of characters.
Architecture
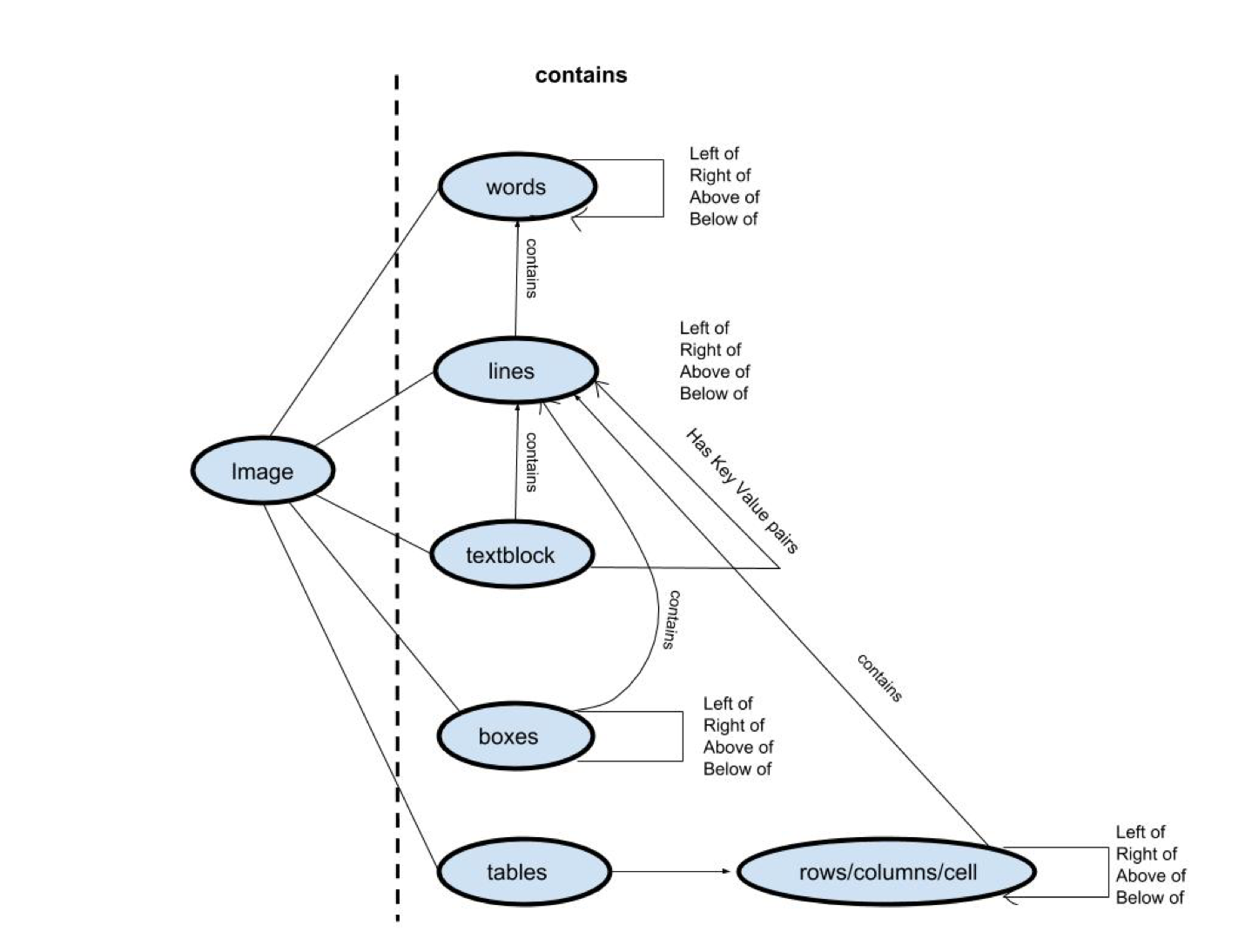
After pre-processing, Deep Reader detects a set of entities from the image, including page lines, text blocks, lines of text blocks, and boxes. The detection goes through the schema as shown on the above figure to retrieve a comprehensive set of data from the scanned document. Rule-based methods provided by domain experts are also adopted to aid the extraction process. For example, Deep Reader uses abstract universal data types such as city, country, and date to ensure that fields retrieved are relevant.
Code Implementation
With some understanding of KVP extraction, let’s dig into the code implementation through a simple scenario — company, address, and price extraction from invoices.
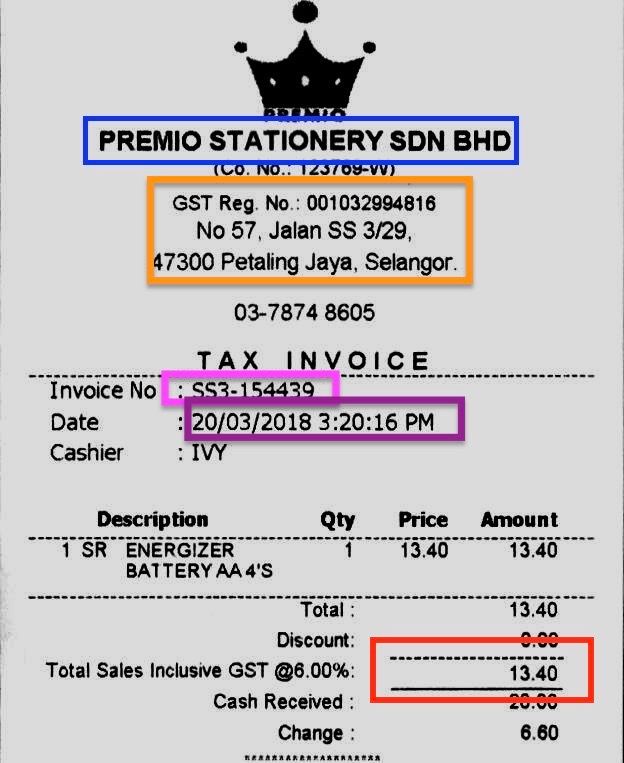
The figure above is a standard invoice template, saved in an image format. We have many of these invoices with similar formats but manually finding out the KVPs such as the company name, address, and total price is a tiring job. Thus, the aim is to design a KVP extractor such that with a given format (or similar formats), we can automatically retrieve and present the KVPs.
To perform KVP extraction, we will need an OCR library and an image processing library. We will use the infamous openCV library for image reading and processing, and PyTesseract library for OCR. The PyTesseract library is a wrapper of the aforementioned Google Tesseract engine, which will be sufficient for our task.
*Side Note: The program is based on the solution of ICDAR Robusting Reading Challenge
Part I — Libraries
You can use pip to install the two libraries via the following commands:
https://gist.github.com/ttchengab/c040ab7ce44114d76c63ecef226d5d09
After installation, we can then import the libraries as the following:
https://gist.github.com/ttchengab/cd32bcd502e99c3e3cc9c73f693927c7
We will also have to import some external libraries:
https://gist.github.com/ttchengab/01280236448e4fc4a03505f6f0baea3f
Part II — Image Preprocessing
https://gist.github.com/ttchengab/293fc3ca782b20cf9b05c33f13583338
The function above is our image preprocessing for text retrieval. We follow a two stage approach to accomplish this:
Firstly, we utilize the cv2.imread() function to retrieve the image for processing. To increase the clarity of the texts in the image, we performed image dilation followed by noise removal using some cv2 functions. Some additional functions for image processing is also listed in the comment section. Then, we find contours from the image and based on the contours we find the bounding rectangles.
Secondly, after image processing, we then iteratively retrieve each bounding box and use the pytesseract engine to retrieve retrieve all the text information to feed into a network for KVP extraction.
https://gist.github.com/ttchengab/b81ea8bb1c21121237845d65d15aa3a0
The model above is a simple LSTM that takes the texts as inputs and outputs the KVPs of company name, date, address, and total. We adopted the pre-trained model from the solution for testing.
The following are the evaluation functions for the LSTM network with a given set of texts:
https://gist.github.com/ttchengab/9f31568ef1b916ab0ee74ac1b8b482e5
Part IV – Entire Pipeline
https://gist.github.com/ttchengab/c2f7614cbeaa8cd14883d4ebbcd36ba6
With all the functions and libraries implemented, the entire pipeline of KVP extraction can be achieved with the above code. Using the invoice above, we could successfully retrieve the company name and the address as the following:

To test the robustness of our model, we can also tested on invoices with unseen formats such as the following:
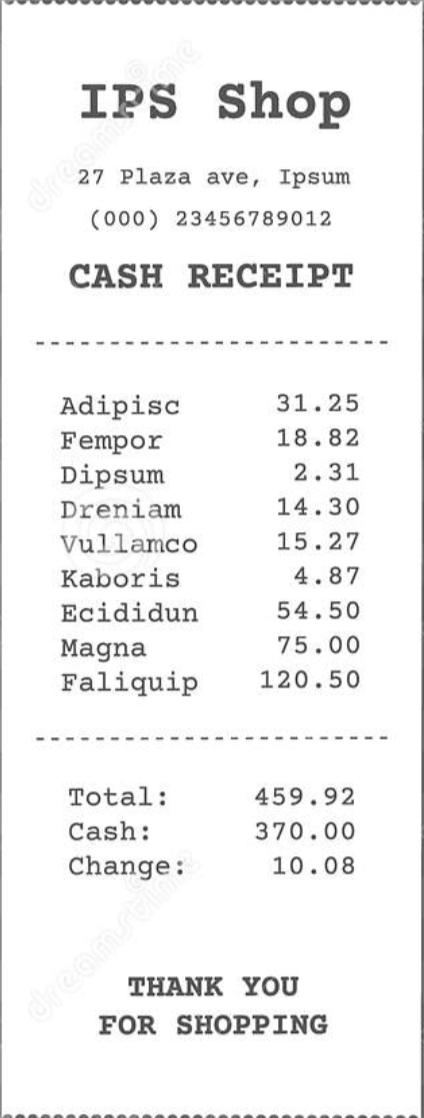
By using the same pipeline, without further training, we could obtain the following:

Even though we couldn’t retrieve other information such as company name or address, we were still able to obtain the total correctly without ever seeing any similar invoice formats before!
With an understanding of the model architecture and pipeline, you can now use more invoice formats that are more relevant as training and continue to train the model so that it would work with higher confidence and accuracy.
Summary
The rise of deep learning has created opportunities to rethink some of the non-trivial problems in information retrieval. This article serves as an introduction to KVP extraction. We began by discussing the concept of KVPs and the use cases of its extractions. Then, we dive into the approaches of utilizing the traditional OCR as well as the deep learning methods of the extractions. Finally, we learnt how to utilize one of the state-of-the-art deep learning-based OCR engines to perform KVP extraction from invoices of similar templates.
[ad_2]
Source link