
[ad_1]
This blog is a comprehensive overview of techniques for structured key-value pair information extraction from invoices. We review the latest research papers that explore this topic and towards the end touch upon how you can get started implementing these methods.
Introduction
Around 18 billion invoices are issued each year in USA and Europe alone. Form-like documents such as invoices, purchase orders, tax forms and insurance quotes are common in everyday business, but current techniques for processing these still employ a large amount of manual effort/time or use OCR based heuristics for extraction. Although OCR has been fairly successful in helping digitization of machine-printed text there are quite a lot of limitations in dealing with form-like data available.
Using AI to process form-like data is a challenging task since it involves the usage of both Computer Vision and NLP. In addition, the data input in forms need not be natural language and hence the NLP algorithms have to be trained to deal with unknown words. In this article we shall look at the various challenges involved in dealing with dynamic data, how various AI techniques can be used in attacking the problem along with corresponding code references.
Template-based OCR challenges
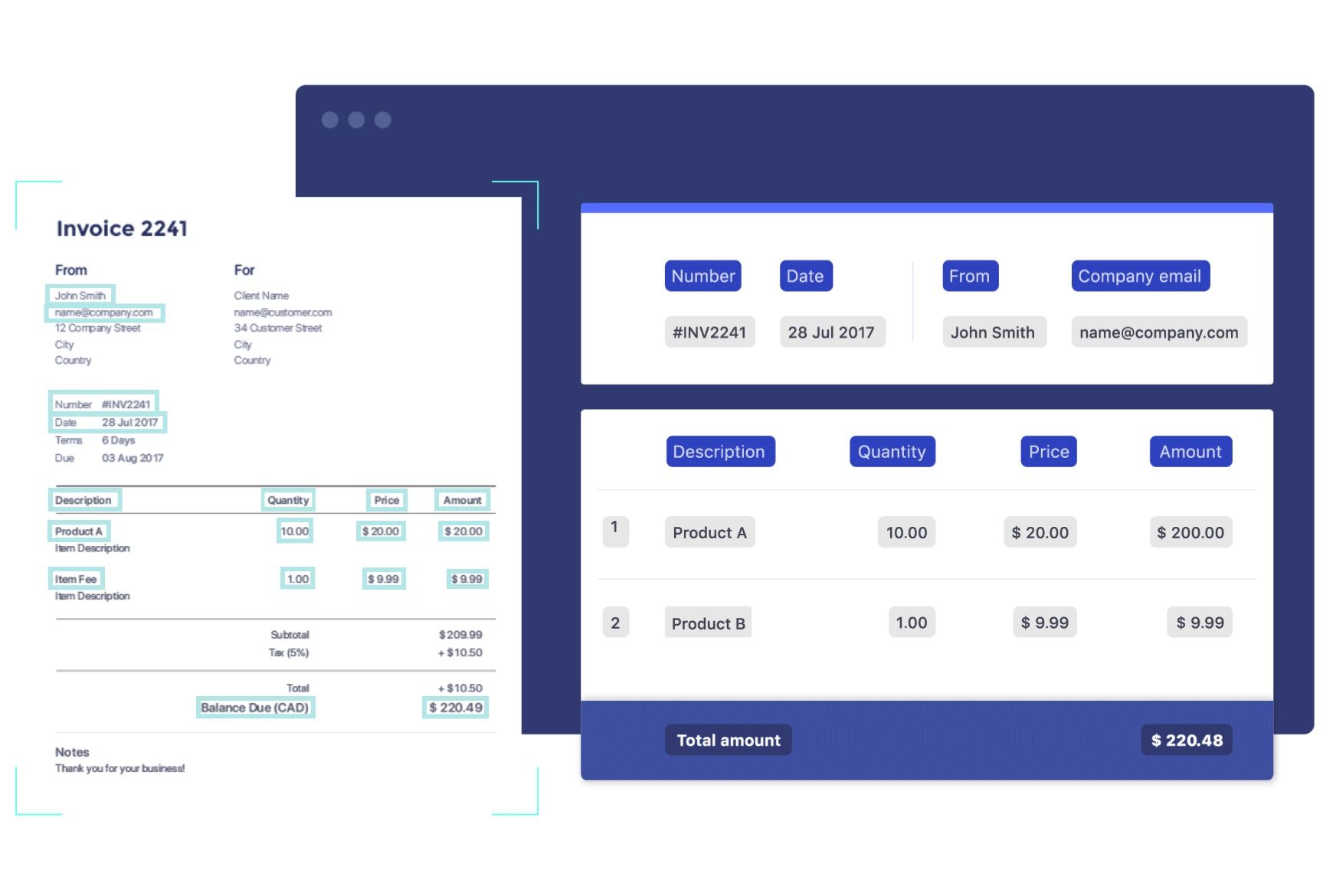
Traditional OCR solves the problem of processing invoices using manual setup of heuristics but this is not scalable since there could be a huge amount of variance in the invoices that are being provided by various vendors as can be seen in below figure.

Setting up these heuristics manually is a cumbersome and error-prone process. Understanding spatial relationships across various fields is critical for achieving good information extraction performance on form-like documents. There could be multiple date fields mentioned in the invoice say Invoice Data, Due Date, Transaction Date etc. but if we want to extract only Invoice Date we have to identify the position of date segment and it’s relation to other fields. Thus we need an AI algorithm which is intelligent enough of dealing with unknown templates and can identify the various 2D relations present in the document.
Template-free AI algorithms
As we have seen using a template based algorithm has a lot of problems in scaling and generalization. To overcome these let’s discuss template-free AI techniques which can work without the need for manual heuristics.
Deep Visual Template-Free Form Parsing
This work focuses on the problem of detecting text in noisy form documents such as cheques/invoices and performing information extraction. Older methods for information extraction have mostly focused on documents following a template, rather than documents with complex layouts which change from invoice to invoice. The template based approaches must be aware of text regions and their positions in the document upfront which is a bottleneck to digitization. They are also not generally resistant to noise which is a common case in real-world documents like bank cheques. Also the template based approaches are trained for a specific language which is not scalable considering the amount of languages in real-world.
The proposed method is language-agnostic and does not use text transcriptions, meaning it can directly be applied to forms in different languages and is also quite efficient in dealing with noisy data. It is not dependent on any template and hence can deal with complex layouts and can generalize a lot better
Approach
In this research the authors come up with a trained end-to-end language-agnostic method for finding label-value pairs in noisy form images which outperforms existing heuristic based pairing methods. In addition, a new annotated dataset NAF is provided as a contribution
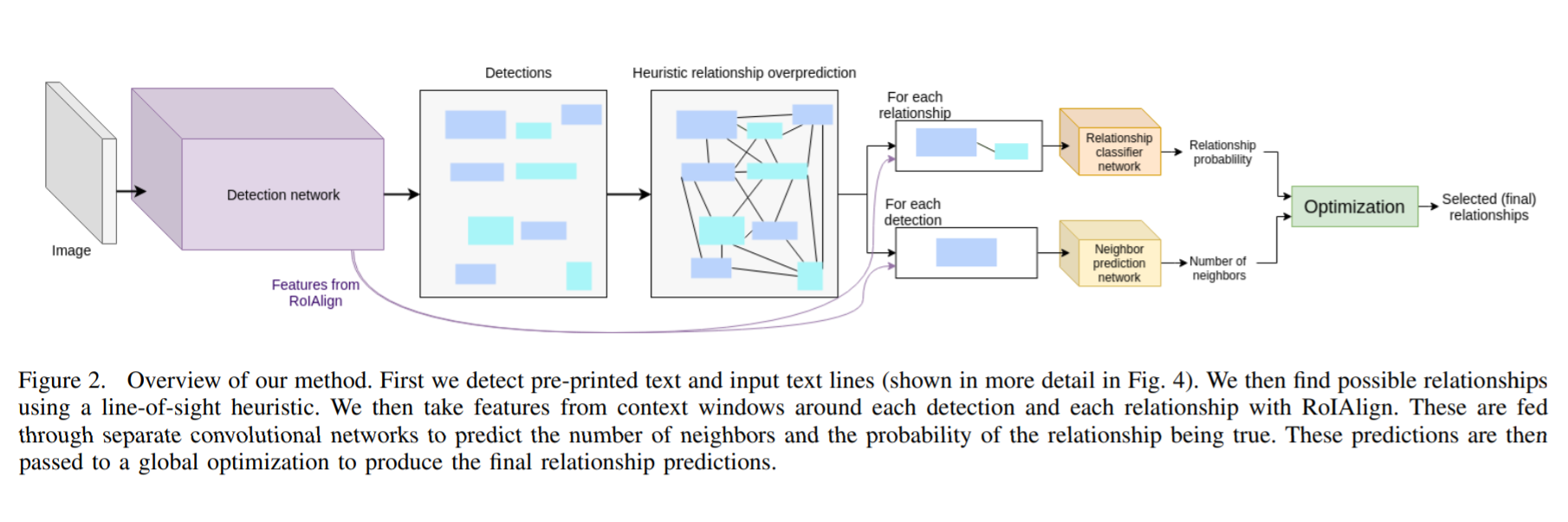
The entire workflow of the algorithm can be divided into the following steps
- Pre-printed text/handwriting instances are detected using an object detector network
- A possible set of relations are generated for each detection using line of sight
- Features from detector network for a pair of related boxes along with detection masks are used to predict relationship probability by a Relationship classifier network
- Features from detector network for a detection along with detection masks are used to predict the number of related boxes by a Neighbor prediction network
- All the prediction probabilities and number of neighbors predictions are sent to an global optimization algorithm which uses the overall context to select the best relationships
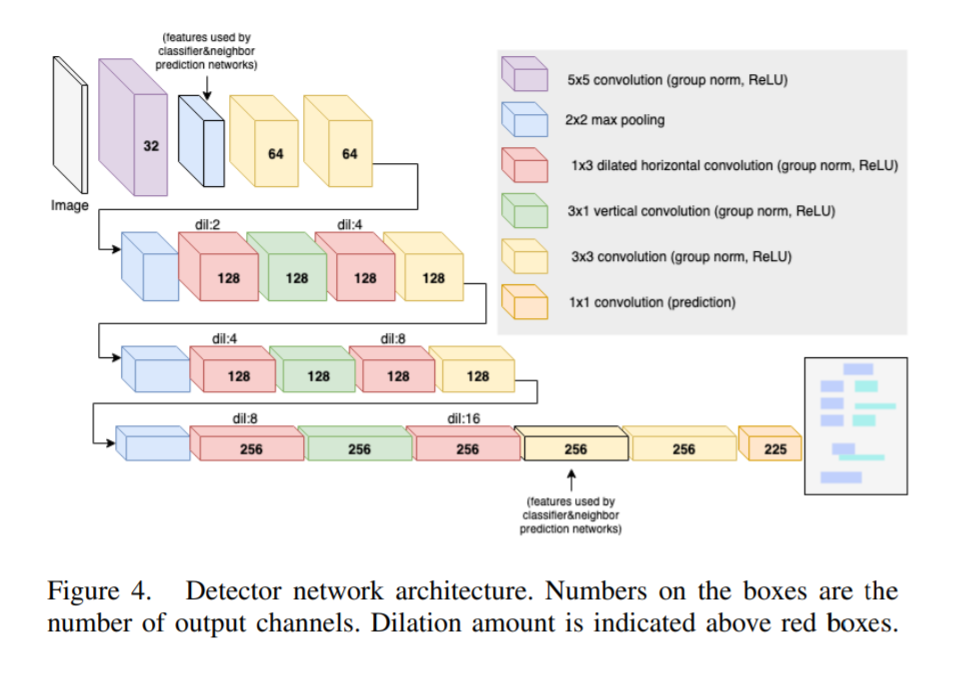
A FCN based approach is used to solve the problem of detecting the printed/handwritten text similar to an object detection problem. The detection algorithm is based on the architecture of YOLOv2 and uses the loss function of YOLOv3. The authors observed that usage of standard 3×3 convolutions resulted in poor results on long text lines. The lengths of the bounding boxes that can be accurately predicted are limited by the horizontal receptive field of the network.
The authors observed that usage of standard 3×3 convolutions resulted in poor results on long text lines
The authors propose a novel way of increasing the horizontal receptive field of the network using 1×3 dilated convolutions. Applying a 3×3 convolution has almost the same effect of applying a 1×3 convolution followed by a 3×1 convolution. As there is only a need for increasing the horizontal receptive field, 1×3 dilated convolution is applied to 3×1 non-dilated convolution.
25 anchor boxes are used which are found using k-nearest neighbours algorithm for YOLO algorithm. To prune spurious detections before pairing, a threshold of 0.5 confidence is used and non-maximal suppression is applied. The detector network in addition provides a preliminary prediction of the number of neighbours (relationship pairs) for each detected text. This is done by having the final 1×1 convolution predict an additional value trained with mean-squared-error loss
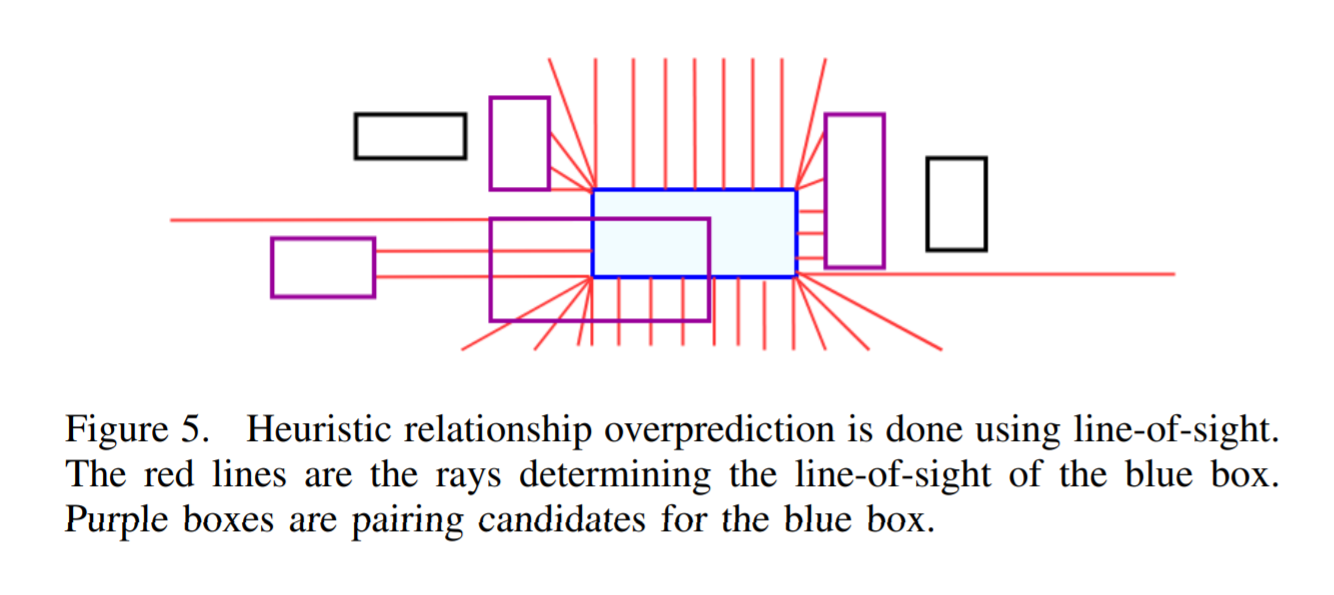
Once the text has been identified using the detector, the output boxes are paired using a simple heuristic line of sight to have a high recall. All pairs of bounding boxes whose edges are within line-of-sight of each other, and are not too far away from each other, are considered candidates. The line-of-sight is determined by tracing rays from points along the edges of bounding boxes which terminate after entering a bounding box. Total number of candidate relationships are limited to 370 due to memory constraints.

Once the candidates pairs are determined by the line of sight algorithm, we used the below features to predict the probability of relationship between candidate pairs
- Difference of center x and y positions
- Distance from each corner to its counterpart (top-left to top-left etc.)
- Normalized height and width
- Detector predicted probabilities of belonging to the pre-printed text / input text classes
- Predicted number of neighbors
In addition to spatial features humans also use multiple visual cues like lines, borders, nearby text etc. to determine relationships. The detector network features from both the second to last convolution layer and the first pooling layer are passed through ROIAlign to size 32×32. In addition we append three binary masks, one each for bounding box in the relationship and a mask of all detected bounding boxes. All the masks are resized to 32×32 before appending.
The concatenated features are sent to a Relationship Classifier Network as seen in the figure. The output of the global average pooling is appended with the handmade spatial features mentioned above and is then given to a fully connected neural network which gives a binary classification of valid or invalid relation. The network is trained with binary cross-entropy loss.
The Neighbor prediction network works in a similar way to Relationship classification network with slight changes. It has only 2 input masks, one for the detection of interest an one for a mask of all detections. The spatial features added before fully connected layers consist of normalized height and width, initially predicted number of neighbors, and class prediction. The regression output of predicting the number of relationships/neighbors is trained using a MSE loss. The neighbor prediction network predicts the number of neighbors with 72% accuracy, while the detector alone predicts the number of neighbors with 50% accuracy, suggesting that the use of this neighbor prediction network is helpful
A final global optimization step is performed to select the best relations as predicting a relationship can depend on other relationship decisions in a form. For example when a pre-printed text line has an equal probability to be in a relationship with two different handwriting instances, but one of them has another possible pairing while the other does not. Assuming we know each of these handwriting instances should be paired with only one pre-printed text instance, we can easily recognize the appropriate pairings for them. To take all relationship decisions into account at once global optimization is applied as a post-processing step.

The results show that dilated 1×3 convolutions make a FCN more effective at detecting long text lines. The results also indicate that having a learned method that uses visual features is important when pairing text lines. Also it is found that optimizing results across a page using a global optimization algorithm as a post-processing step leads to increased precision.
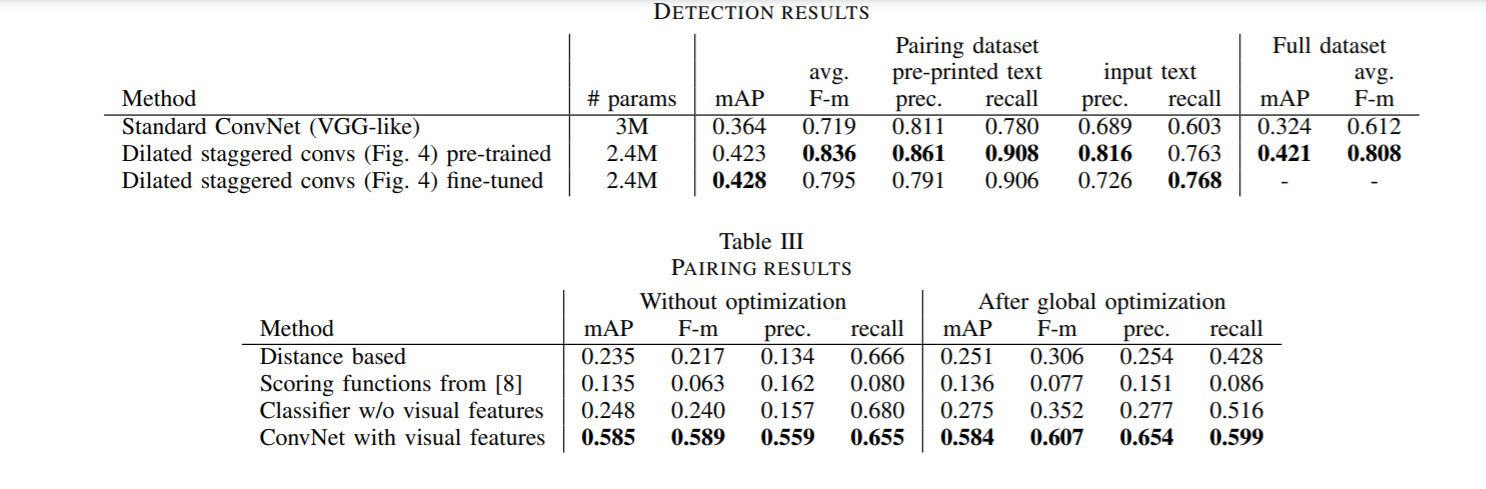
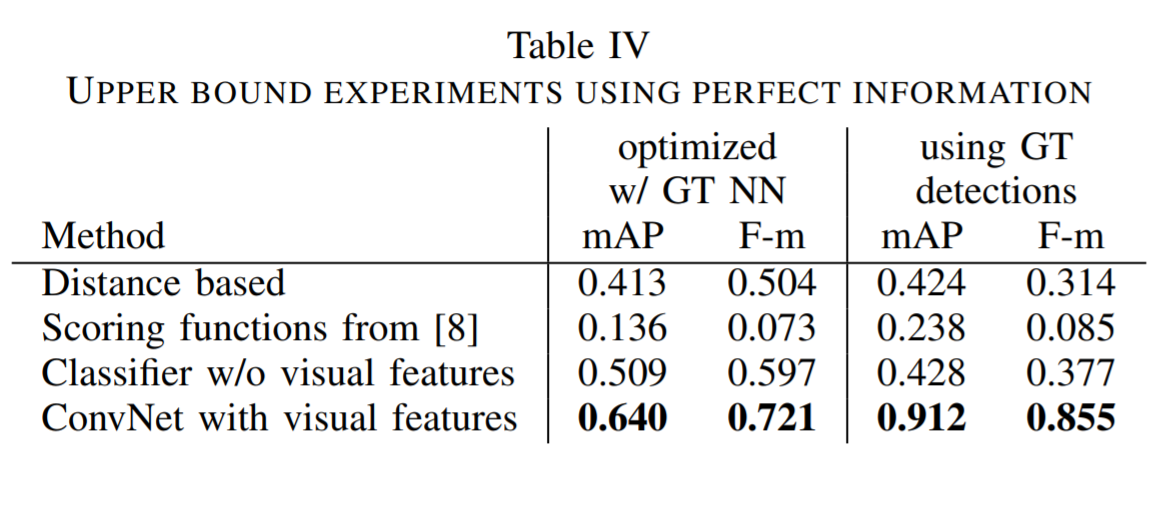
The model performed significantly better than the baseline heuristic based methods as can be seen in the results. The code is available here and the dataset from here.
Attend, Copy, Parse
The current state of the art approaches for information extraction in invoices require labeling of each word which is costly to obtain and can take a large time to collect. To address this problem they propose an end-to-end approach where just the invoice data being extracted by the employees during digitization can be used directly. This kind of data is readily available and can be collected by anyone naturally during the digitization process. The authors propose an end-to-end architecture which can directly deal with end-to-end data.
There is a slight difference between the end-to-end data and data labelled at a word level. In the case of word level labels the exact position of the words needs to be provided along with the word details whereas in end-to-end method we need need the word details which are automatically captured during the digitization process. The end-to-end data is plentiful, produced naturally and is hard to learn from whereas the word level data is scarce and needs manual efforts and money to generate.
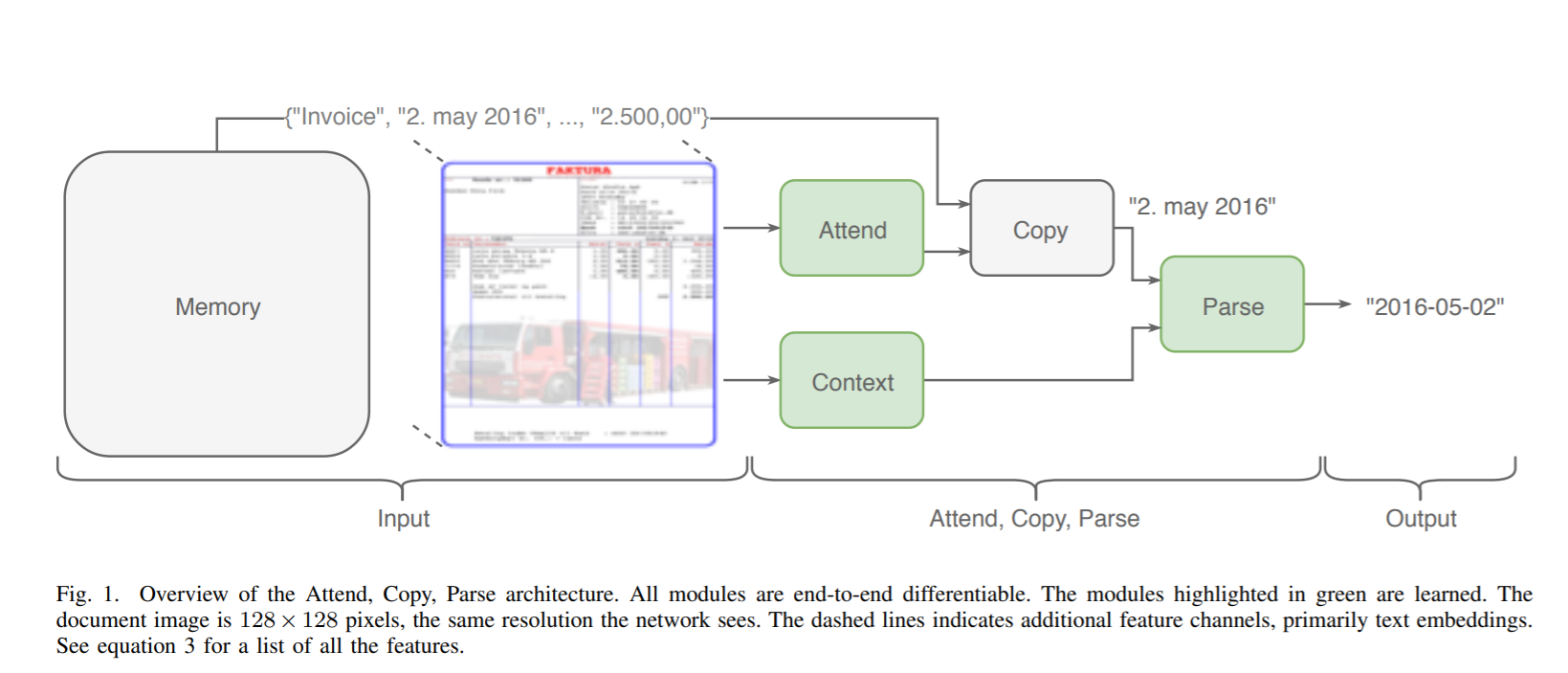
A human way to solve the problem of information extraction would be to
- Locate the string to extract
- Parse it into the desired format
The proposed approach is broadly inspired by the above way of how humans solve the problem manually. It consists of 4 components Attend, Copy, Context and Parse as shown in figure above. The framework produces an output string y by following the below 4 steps
a = Attend(x, w)
c = Copy(a, w)
h = Context(x, w)
y = Parse (c, h)
The algorithm builds an external memory bank of the same size as the document image. It contains the words encoded as a sequence of characters at the memory positions corresponding to the positions of the words in the image. The attend module attends to this memory bank and the copy module copies out the attended string. The parse module parses the attended string into the desired output format, optionally given a context vector computed from the inputs
External Memory
The external memory bank is creating by using N-grams of up to length G generally taken as G=4. The N-grams are encoded as a sequence of one-hot encoded characters, such that L is the maximum sequence length we consider and D is the size of the character set we are using. The encoded N-grams are stored in the single slot corresponding to the top-left corner position of the first word in each N-gram
Attend
u = Attend (x, w)
This block computes the unnormalized attention logits for each slot in external memory. The input x is the document image while the input w is the set of words generated by an OCR engine applied to the document image.
r = Concat(x, qw, qp, qc, z, δx, δy, η)
The Attend function is parameterized in the above way. qw, qp, qc are learnt 32 dimensional word, character and pattern embeddings. The pattern embedding is an embedding of the word after all characters have been replaced with the character x, all digits with 0 and all other characters with a dot. Word and pattern embeddings are replicated across the spatial extent of the entire word. Character embeddings are replicated across the spatial extent of each character in the word.
z is two binary indicator channels whether the N-gram at this position parses as an amount or a date, according to two pre-configured parsers. δx and δy contain the normalized horizontal and vertical positions. η is a binary indicator whether the external memory at this spatial position is non-empty.
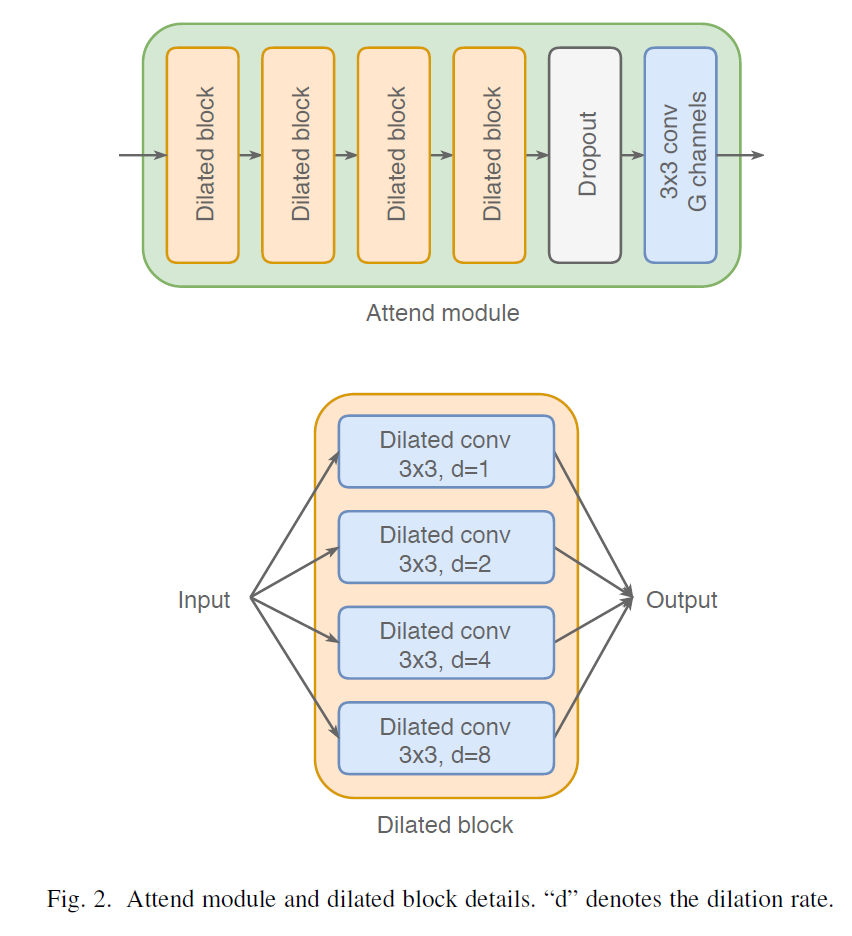
The created input r is passed through 4 dilated convolution blocks. A dilated convolution block consists of a number of dilated convolution operations, each with a different dilation rate, that all operate in parallel on the input, and whose outputs are concatenated channel wise. Each dilated convolution block contains 4 dilated convolution operations with dilation rates [1, 2, 4, 8], each with 32 3×3 filters with ReLU non-linearity. The output of each dilated convolution block has 128 channels.
The dilated convolution block allows the network to preserve detailed local information through the layers with smaller dilation rates, while capturing a large context through the layers with higher dilation rates, both of which are important for this task. After the 4 dilated convolution blocks dropout is applied followed by a final convolution operation with G linear 3×3 filters, to get the unnormalized attention logits u, for each memory slot. Since we know which slots in the memory are not empty we put u = -1000 in the empty slots to not provide any attention to them
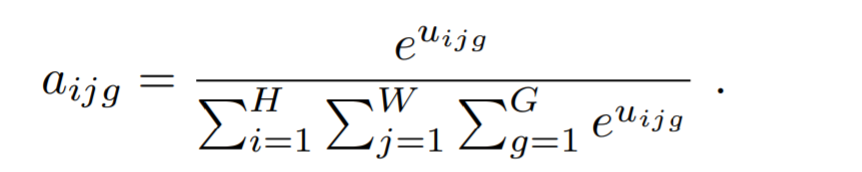
The attention distribution is computed from the unnormalized attention logits using the above formula.
Copy
Using the memory M and the attention distribution from above, the copy of the attended N-gram is obtained using the below formula
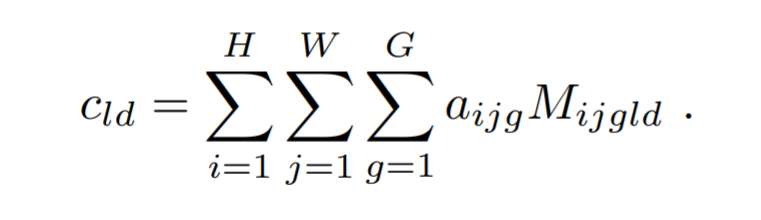
Context
The context of an N-gram is often important for parsing it correctly. For instance the date 02/03/2018 is ambiguous. It can either be the 2nd of March or the 3rd of February, but the context can disambiguate it. For instance, if the language of the document is German, then it is more likely that it is the former.
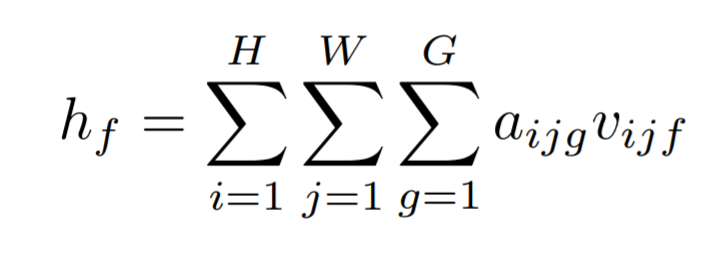
The above function is used to generate context. Here v is the output of the last dilated convolution block of the attend module, after dropout.
Parse
Given the attended word c and the context vector h, c can be parsed into the output y. This is in essence a character based sequence to sequence task
y = Parse(c, h)
The implementation of Parse depends on the output format. Some fields might not need any parsing, while dates and amounts need different parsing. Date Parser uses a custom CNN followed by MLP to generate results. The amount parser uses a pointer-generator network with a bidirectional LSTM with 128 units to encode the input sequence, and a LSTM with 128 units to generate the output hidden states.
A separate model is trained for each of the seven fields Number, Order id, Date, Total, Sub total, Tax total, Tax percent. All the models have the same architecture and hyper-parameters, except for the parsers. The invoice number uses the no-op parser, the order number the optional parser, the date the date parser, and the rest use the amount parser.
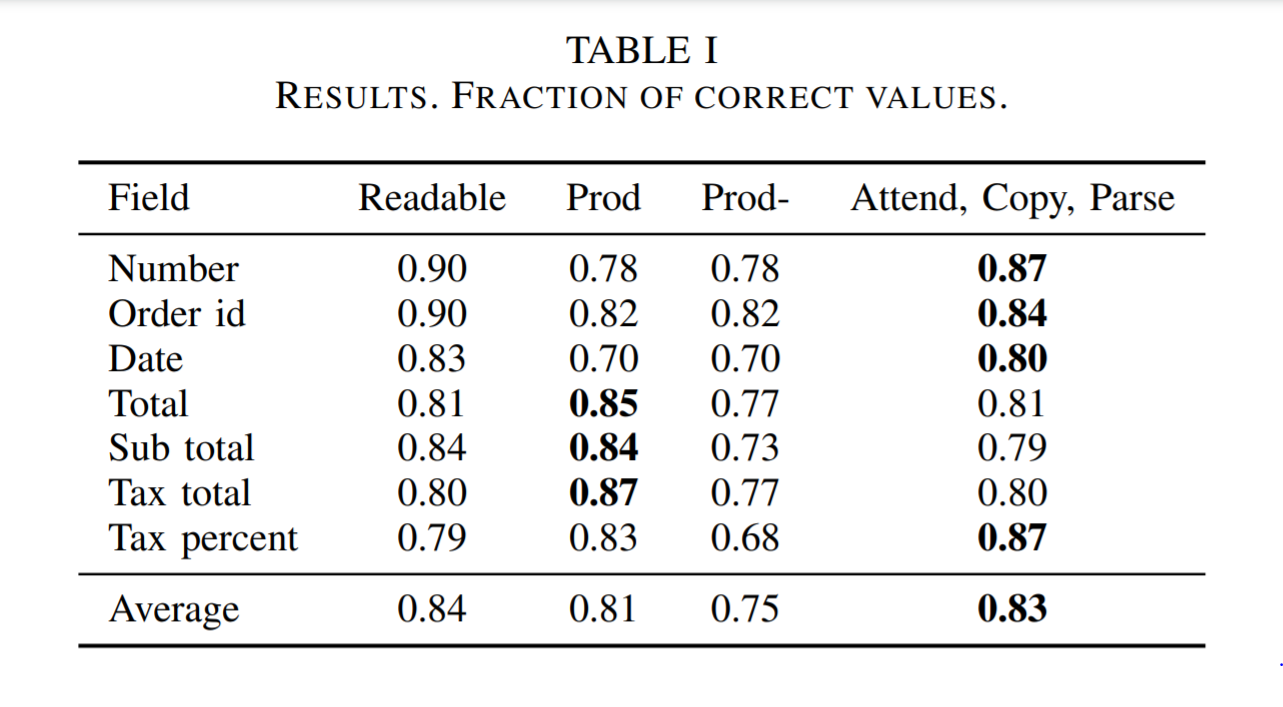
The proposed Attend, Copy, Parse system performs better on average, and close to the approximate maximum accuracy possible. The architecture does not need expensive word-level labels, instead it can directly use the end-to-end data that is naturally produced in a human information extraction tasks and results show it outperformed several state-of-the-art production systems. The code for this research is available from here.
Graph Convolution Networks
The dataset of key-word pairs and their relationships in a document have inherent form of a graph kind of structure and hence can be modeled using Graph Convolution Networks. The GCN architecture can be seen as a generalization of the regular CNN. More information on Graph Convolution Networks is covered in this article. We shall see now how a GCN can be used for template free information extraction
Graph Convolution for Multimodal Information Extraction from Visually Rich Documents
Visually rich documents (VRDs) are used in a lot of places such as purchase receipts, insurance policy documents, custom declaration forms and so on. In VRDs, visual and layout information is critical for document understanding, and texts in such documents cannot be serialized into the one-dimensional sequence without losing information. Classic information extraction models such as BiLSTM-CRF typically operate on text sequences and do not incorporate visual features. In this paper, a graph convolution based model to combine textual and visual information presented in VRDs is introduced. Graph embeddings are trained to summarize the context of a text segment in the document, and further combined with text embeddings for entity extraction
The authors proposed a model which first encodes each text segment in the document into graph embedding, using multiple layers of graph convolution. The embedding represents the information in the text segment given its visual and textual context. The graph embeddings are combined with text embeddings and a standard BiLSTM-CRF model is applied for entity extraction
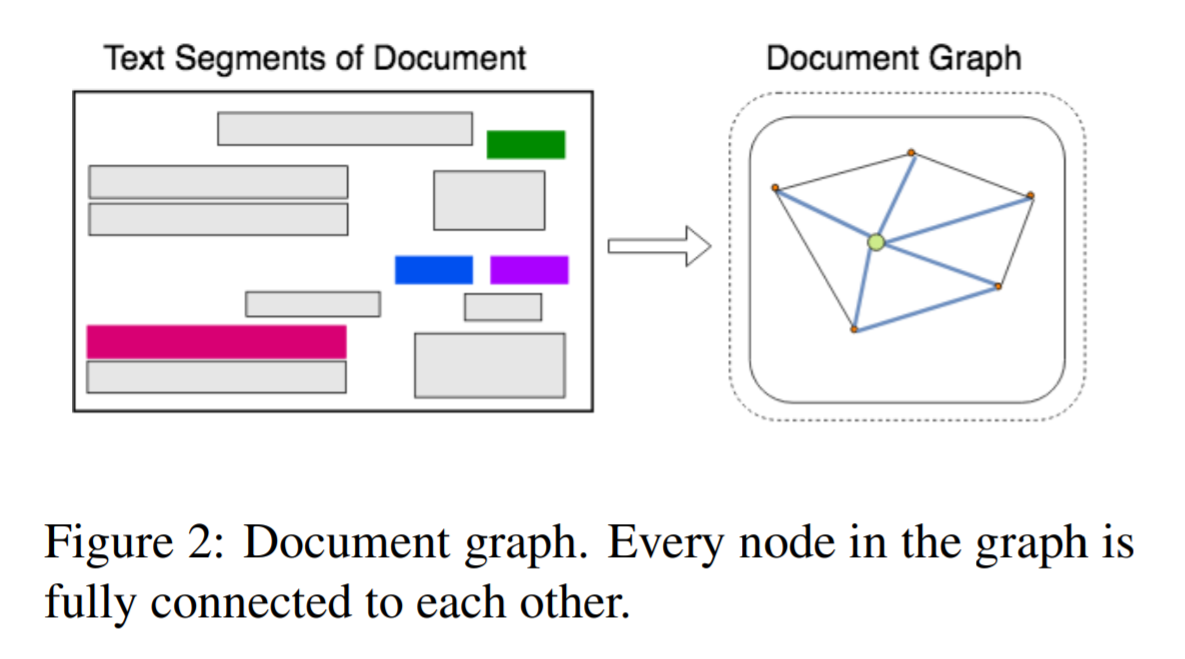
Each document is modeled as a graph of text segments where each text segment is comprised of the position of the segment and the text within it. The graph is comprised of nodes that represent text segments, and edges that represent visual dependencies, such as relative shapes and distance, between two nodes. Text segments are generated using an OCR system.
For every node the corresponding node embedding is calculated using a single layer Bi-LSTM to extract features from the text content in the segment. Edge encoding between 2 nodes uses the visual features such as horizontal and vertical distance between the two text boxes, aspect ratio, relative height and width of node with the other node.
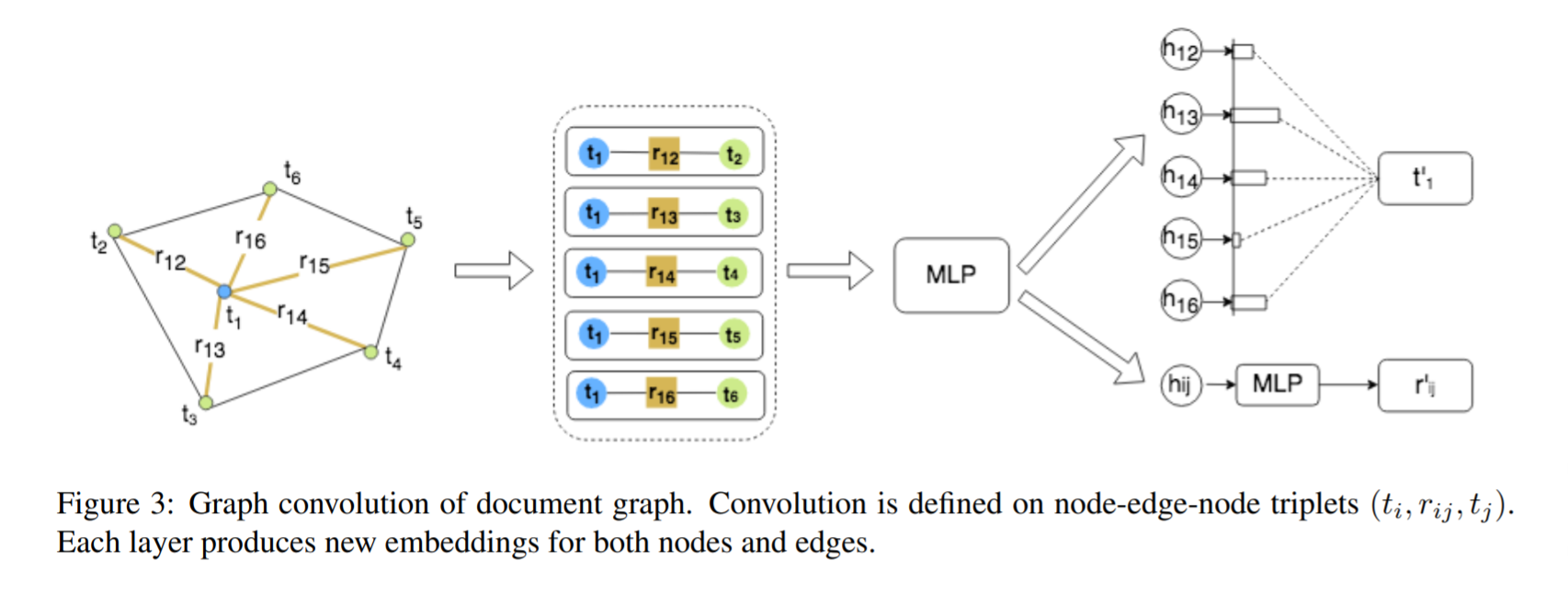
Graph convolution is applied to compute visual text embeddings of text segments in the graph. Convolution is defined on the node-edgenode triplets (ti , rij , tj) where ti, tj represent the node embedding and rij represents the edge embedding. For node ti, features hij for each neighbour tj using a multi-layer perceptron (MLP) network.
The graph convolution is defined based on the self-attention mechanism. The output hidden representation of each node is calculated by attending to each of its neighbors.
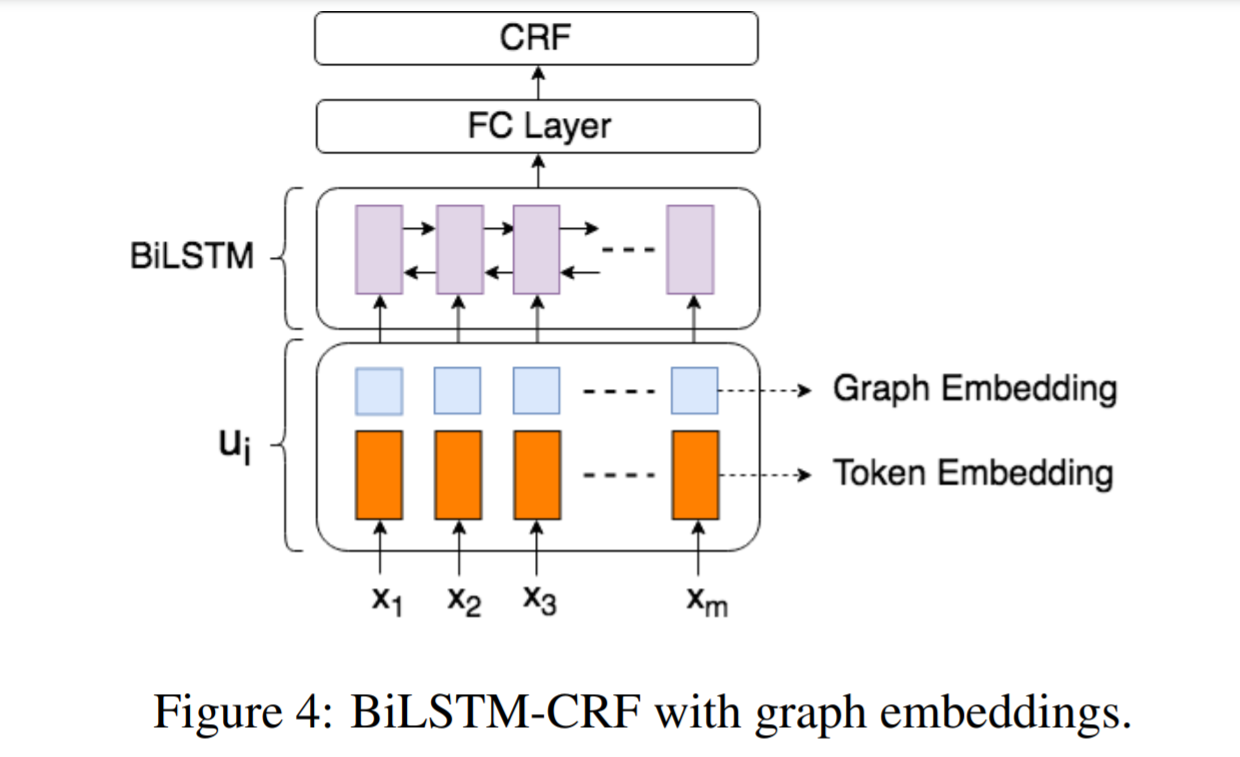
The graph embeddings are combined with token embeddings and fed into a standard BiLSTM-CRF for entity extraction. Word2Vec vectors are used as token embeddings. The output is further passed to a fully connected network and then a CRF layer. The graph convolution layers and BiLSTM-CRF extractors are trained jointly.
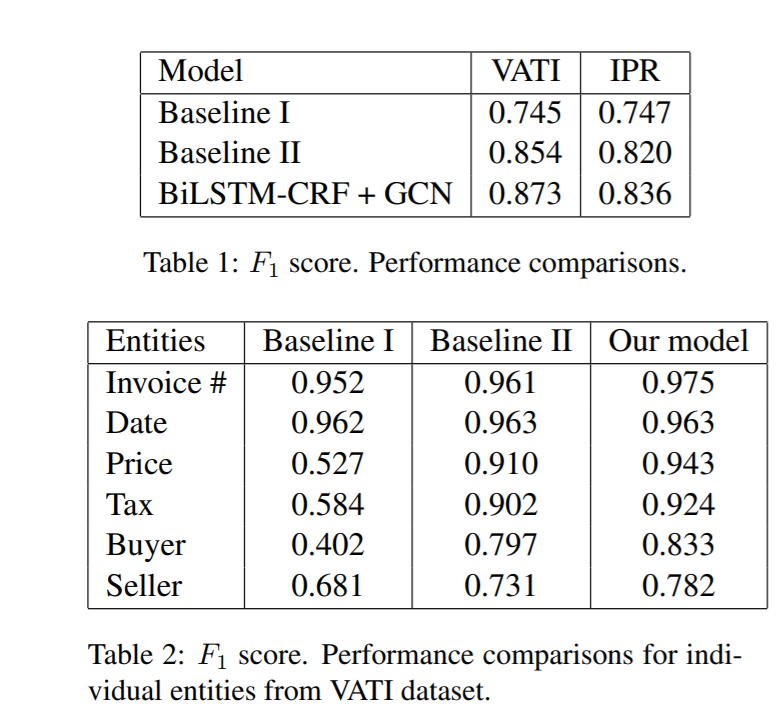
F1 score is used to evaluate the performances of the model. As can be seen the proposed model outperforms both baselines by significant margins. The proposed model clearly outperforms baselines on entities which can not be represented by text alone, such as Price, Tax, Buyer, and Seller hence underlying the importance of visual information.
The current techniques for processing form-like documents largely still employ either manual effort or brittle and error-prone heuristics for extraction. We have seen ways of solving this problem using the approaches we discussed so far. In contrast to the above approaches, the authors propose an approach based on representation learning for this task. Invoices from the suppliers share similar presentation and differ only in specific values and hence can use representation learning on them. An advantage of the representation learning approach is that it allows to encode certain priors developed based on these observations into the architecture of the neural network and its input features
The authors propose an extraction system that uses knowledge of the types of the target fields to generate extraction candidates, and a neural network architecture that learns a dense representation of each candidate based on neighboring words in the document. These learned representations are not only useful in solving the extraction task for unseen document templates from two different domains, but are also interpretable
The design of this method rests on 3 observations of form-like documents
- Each field often corresponds to a well-understood type. For example, the only likely extraction candidates for the invoice_date field in an invoice are instances of dates. A currency amount like $25.00 would clearly be incorrect
- Each field instance is usually associated with a key phrase that bears an apparent visual relationship with it i.e the filed instance and the key phrase in the document should have some sort of relation such as lying side-by-side/top-and-bottom etc.
- Key phrases for a field are largely drawn from a small vocabulary of field-specific variants. For example in the corpus collected for conducting the research, 93% of the invoice date instances are associated with key phrases that included the word “date” and “dated”.
The stages of the entire pipeline in extracting the information from invoices is laid out below
Ingestion
Each document in input is rendered to an image and a cloud OCR service is used to ingest all the text in the image. The generated text is arranged in hierarchy with individual characters at leaf level, and words, paragraphs and blocks respectively in higher levels. The nodes in each level of hierarchy are associated with bounding boxes in the 2D plane of document image
Candidate Generation
Fields in our target schema correspond to well-understood types like dates, currency amounts, addresses, etc. Each field type in the document is associated with one or more candidate generators which use a cloud-based entity extraction service to detect spans of OCR text.
Scoring and Assignment
Given a set of candidates from a document for each field in target schema, the algorithm has to identify the correct extraction candidate. To achieve this a score for each candidate is computed independently using a neural model. Then the mostly likely true extraction candidate is assigned for each field choosing the highest-scoring candidate for each field independently of other fields
Neural Scoring model
The authors propose an architecture where the model learns separate embeddings for the candidate and the field it belongs to, and where the similarity between the candidate and field embeddings determines the score. The learned representation of a candidate encodes the words in its neighborhood. The spatial relationships between candidates and their key phrases are observed to generalize across fields. The embedding for a field encodes the key phrase variants that are usually indicative of it.
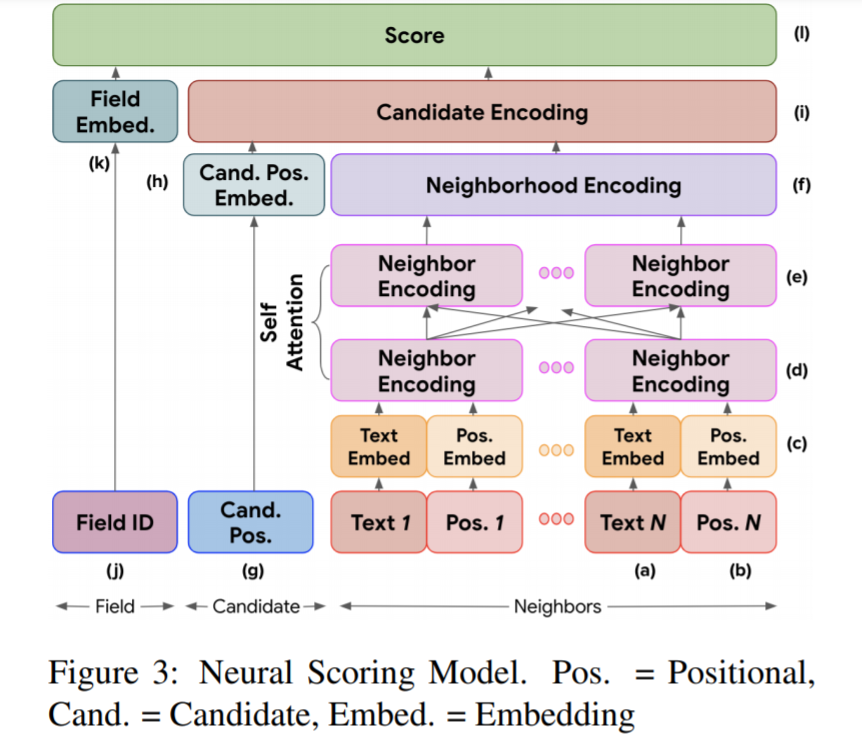
Candidate features
The candidate features are selected to learn a candidate representation that can capture the neighborhood. Thus the text token that appear nearby along with their positions are used. The position of a candidate and each of its neighbors are represented using the 2D coordinates of the centroids of their respective bounding boxes. The relative position of a neighbor is calculated using difference between its normalized 2D coordinates and those of the candidate. The absolute position of the candidate itself is used in addition to the above features.
The neighboring text tokens are embedded using a word embedding table. Each neighbor relative position is embedded through a nonlinear positional embedding. The candidate position feature is embedded using just a linear layer. An embedding table is used for the field to which a candidate belongs. In order to capture interactions between neighbors, self-attention allowing each neighbor to have its embedding affected by all others is used. This helps the model to down weigh a neighbor that has other neighbors between itself and the candidate
The N neighbor encodings are combined to form a single encoding of size 2D for the entire neighborhood. Maxpooling is used to make the neighborhood encoding invariant to the order in which the neighboring features are included. The overall neighboring encoding is concatenated with the candidate position embedding and projected back down to d dimensions.
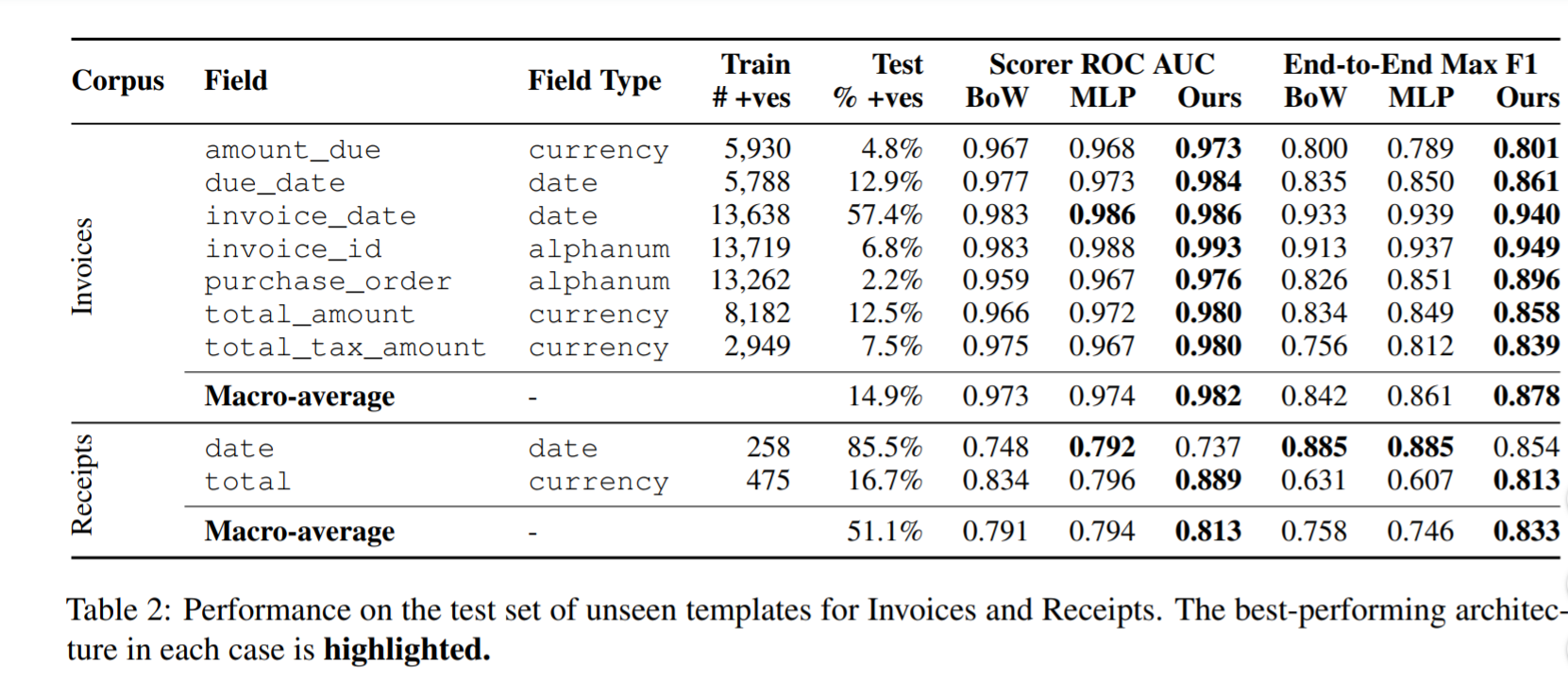
As can be seen, the model showed a significant improvement over the baselines in both metrics ROC AUC and F1 score. The results show that self-attention contributes greatly to model performance leading to a 1-point improvement in ROC AUC and a 1.7 point improvement in F1 score.
Summary
To conclude, although the task of invoice extraction from structured documents is a tough challenge, the recent developments in AI allow us now not only to parse the text available in the document but also to capture the relationships across various fields and text and thus helps to automate generating end-to-end results which are much more generalized compared to creating manual heuristics traditionally.
In addition, AI methods evolve on a regular basis with the advancements in research and with them outperforming traditional OCR methods already it becomes a no-brainer to invest in AI based solutions for information extraction.
[ad_2]
Source link